通用科技文本可视化挖掘系统
Intelligence Insight
【ItgInsight】
使用手册
V2.4@202401
北京正乙科技有限公司
3.11 网络布局算法/选择合适的网络布局算法使网络图尽可能美观 41
6) 按照关系强度、节点形状、节点名称、节点大小对节点染色 47
3.20 计算网络密度、节点中心度、主路径、技术竞争力指标 58
3.27 打开保存layout位置信息文件(位置信息的重复利用) 65
3.28 打开保存graph style样式信息文件(样式信息的重复利用) 65
第四章:聚类分析、热力图/地形图/密度图、世界地图、气象图、矩阵图可视化 70
6.8 组合分析(跨维度、跨层次的共现矩阵、引证矩阵) 93
第九章:中英文科技术语识别(构建用户自定义主题词表) 109
第十章:与VosViewer,Pajek,Ucinet进行交互 111
12.3 依据元数据对图形进行查找、更改节点大小、更改节点文字、绘制凸包 115
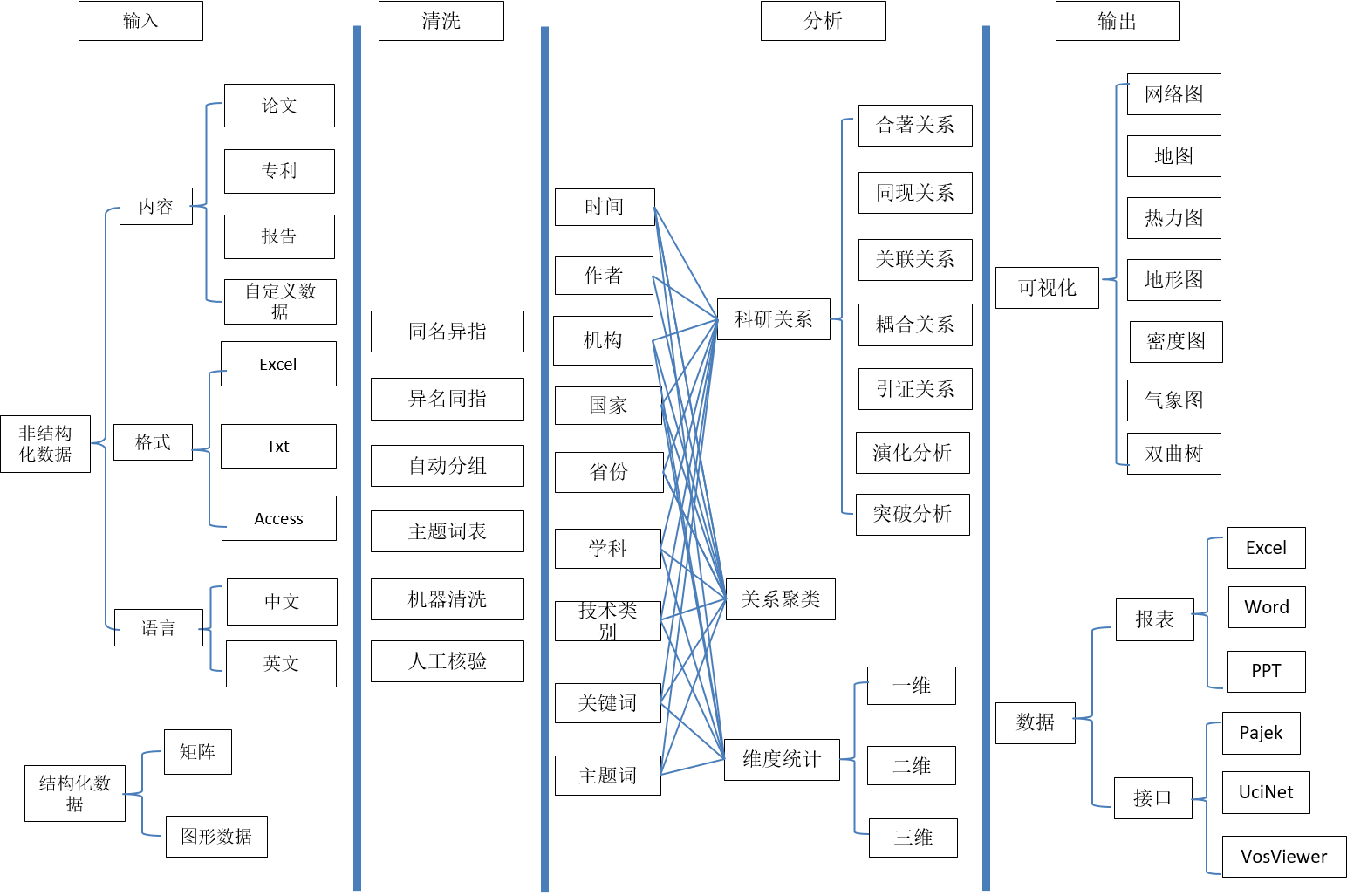
通用科技文本可视化挖掘系统,英文简称为ItgInsight,英文全称为Intelligence Insight,由北京正乙科技有限公司(www.zyinsight.com)设计开发,资源下载地址www.ItgInsight.com。该软件是一款商业化科技文本挖掘与可视化分析工具,主要针对科技文本,如专利、论文、标准、政策、报告、报刊等进行可视化分析与挖掘,也可应用于微博、微信等互联网文本数据可视化,可视化挖掘方法有合作关系可视化、同现关系可视化、耦合关系可视化、关联关系可视化、引证关系可视化、演化分析可视化、突破分析可视化,可视化输出包括网络图、热力图、密度图、地图、矩阵图、演化图、聚类图、突破图。该工具增强了对大规模数据的处理,将聚类分析、技术热力图、技术地形图、技术气象图整合到系统中。
用户可应用该工具对SCI、CNKI、万方论文数据,德温特专利、美国专利、中国专利、欧洲专利,科研项目、技术标准、产业政策等数据进行文本可视化挖掘,进而开展学术评价、学科服务、技术监测、技术机会分析、竞争态势分析等科研管理与情报分析任务。同时,该工具也是一款综合的情报分析平台,提供除数据清洗、文本挖掘和可视化分析以外的基本维度统计、excel报表、word智能报告、ppt可视化输出等辅助功能。
该系统支持用户自定义格式的任何文本数据、图形数据,并提供与情报分析工具VOSviewer、复杂网络工具Pajek、UCINET的数据接口、使用接口。
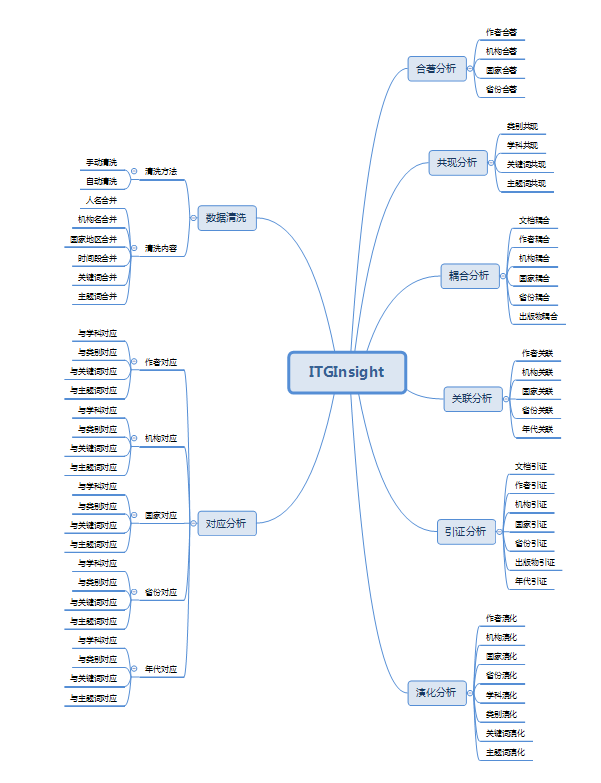
该系统的功能框架可参考如下两幅图,具体操作过程见第三、四章。
| 序号 | 软件 | 归属 | 商业化 | 功能类型 | 数据清洗 | 分析数据 | 分析方法 | 可视化输 | 自动报告 | ||||||||||
| 数据源 | 数据类型 | 数据清洗 | 用户词表 | 基本统计 | 合作分析 |
共词
分析 |
引证
分析 |
关联分析 |
演化
分析 |
可视化图形 | 交互接口 | 自动报表 | 自动报告 | ||||||
| 1 | UCINET |
美国
加州大学 |
否 |
复杂网络工具
可视化展示工具 |
无 | 任意 | 结构 | 无 | 无 | 有 | 无 | 无 | 无 | 无 | 无 | 统计图、网络图 | 弱 | 无 | 无 |
| 2 | Pajek |
斯洛文尼亚
卢布尔雅那大学 |
否 |
复杂网络工具
可视化展示工具 |
无 | 任意 | 结构 | 无 | 无 | 无 | 无 | 无 | 无 | 无 | 无 | 网络图、树图 | 强 | 无 | 无 |
| 3 | Vxinsight |
美国
Sandia国家实验室 |
否 | 可视化展示工具 | 无 | 任意 | 结构 | 无 | 无 | 无 | 无 | 无 | 无 | 无 | 无 | 网络图、主题图 | 强 | 无 | 无 |
| 4 | CiteSpace |
美国
Drexel 大学 陈超美 |
部分 | 基于文本的可视化分析软件 | 无 | 任意 | 结构/非结构 | 有 | 无 | 无 | 有 | 有 | 有 | 无 | 无 | 网络图、地图、突破图、时区图 | 强 | 无 | 无 |
| 5 | VOSviewer |
荷兰
莱顿大学的科学和技术研究中心 |
否 | 基于文本的可视化分析软件 | 无 | 任意 | 结构/非结构 | 有 | 无 | 无 | 有 | 有 | 无 | 无 | 无 | 热力图、网络图、聚类图 | 弱 | 无 | 无 |
| 6 | True-Teller | 日本
野村研究所 |
是 | 基于文本的可视化分析软件 | 有 | 任意 | 结构/非结构 | 有 | 无 | 无 | 无 | 有 | 无 | 无 | 无 | 热力图、网络图 | 弱 | 无 | 无 |
| 7 | Vantage-Point | 美国
GIT技术政策与评估中心/佐治亚理工 |
是 | 基于文本的可视化分析软件 | 有 | 任意 | 结构/非结构 | 有 | 有 | 强 | 有 | 有 | 无 | 有 | 无 | 统计图、矩阵图、网络图、Aduna图 | 强 | 有 | 有 |
| 8 | Thomson Data Analyzer(TDA)
更名为Derwent Data Analyzer(DDA) (Vantage-Point的中文本版) |
美国
汤姆森·路透 加拿大 科睿唯安 |
是 | 基于文本的可视化分析软件 | 有 | 任意 | 结构/非结构 | 有 | 有 | 强 | 有 | 有 | 无 | 有 | 无 | 统计图、矩阵图、网络图、Aduna图 | 强 | 有 | 有 |
| 9 | ItgInsight | 中国
正乙科技 |
是 | 基于文本的可视化分析软件 | 有 | 任意 | 结构/非结构 | 有 | 有 | 强 | 有 | 有 | 有 | 有 | 有 | 热力图、网络图、矩阵图、聚类图、演化图 | 强 | 有 | 有 |
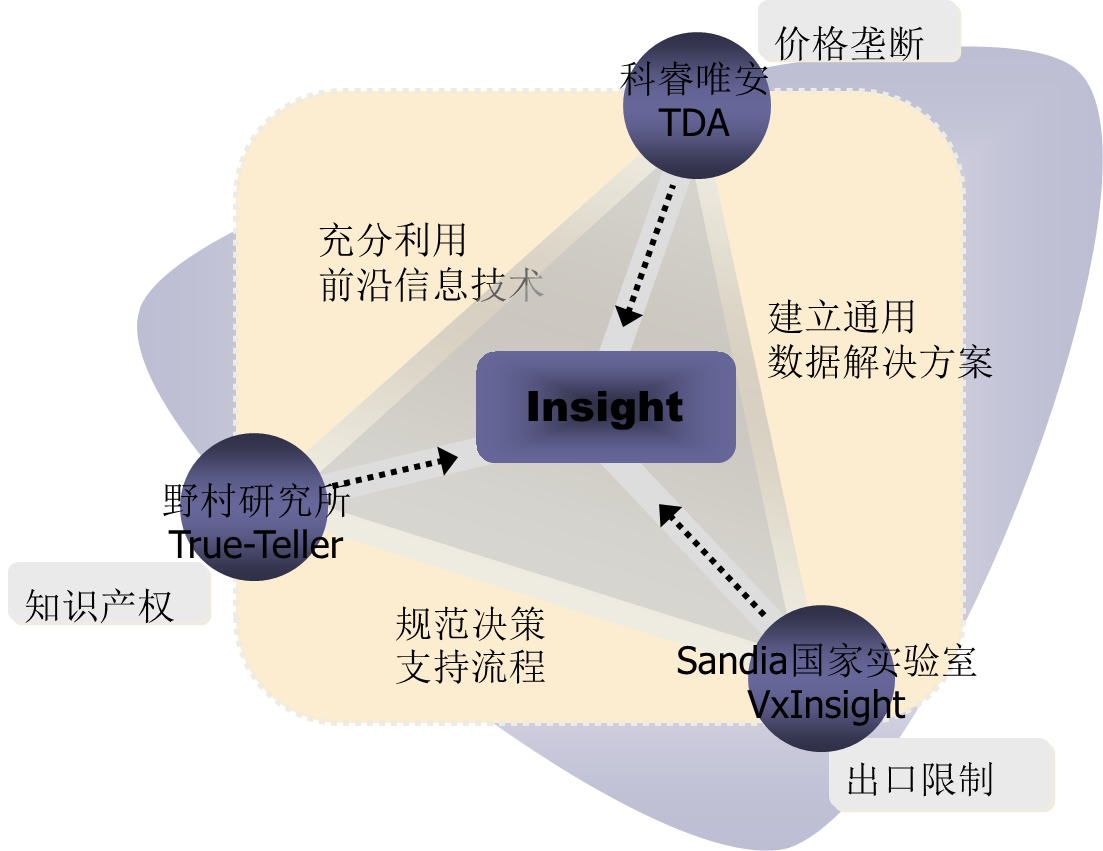
国内无同类产品,国外加拿大科睿唯安DDA(原来汤姆森路透TDA)、日本野村研究所的True-Teller、美国Search Tech公司Vantange Point、美国Sandia国家实验室的VxInsight与ItgInsight具有相似的功能。相比国外产品,ItgInsight在术语识别、中文支持、数据处理数量、数据清洗方便性,以及可视化展示的美观程度上具有显著的技术优势。
- 高校图书馆
- 科技情报研究所
- 企业工程技术人员
- 企业知识产权管理决策人员
- 高校、科研机构教师、学生
- 其它情报分析师、知识产权分析师、咨询师、代理人、律所
ItgInsight典型客户包括高校图书馆、高校经济管理学院、各级科技情报所、信息中心,部分高校,如武汉大学、华中科技大学、北京理工大学、吉林大学、西北大学、北京工业大学、中国传媒大学等一批高校开设了ItgInsight相关的本科生、研究生课程。中国大学慕课https://www.icourse163.org/course/WHU-1465998163?from=searchPage&outVendor=zw_mooc_pcssjg_有关ItgInsight授课视频。
软件分为保密版(内网版),企业版,教学版(学术研究版)和学生版(社区版)。学生版(社区版)下载地址为www.ItgInsight.com,不用注册,仅限学生撰写论文,禁止商业应用,禁止项目应用,禁止集中教学,须联网,上传用户数据,无技术支持,数据分析数量一般为5000条,通过微信支付获取临时授权可增加数据分析量。其他版本均针对付费用户,不支持试用,实行价格标准化,全网公开(公开地址:http://zc.zyinsight.com/?page_id=67)。
任何基于学生版(社区版)撰写的学术论文,在您获得免费的软件使用权后,我方可以以宣传为目对相关论文进行对外宣传展示,并不受论文版权方的约束,请您在发表论文时注意此项要求,如果您不认可此项条款,请勿使用学生版(社区版)发表论文。无论您是否使用了临时授权,都应遵守社区版、个人版的使用约束!
各版本差异如下:
| 个人学术版(在线注册) | 团队学术版
(在线注册) |
图书馆、情报所版(在线注册) | 企业版、教学版本(在线注册) | 保密版(内网离线注册) | |
| 适用用户 | 仅限个人用户 | 仅限高校教师科研团队 | 高校图书馆,各级科技情报所 | 高校图书馆,科技情报所 | 其他机构,有保密需求单位 |
| 数据分析数量 | 有限制,不上传用户数据 | 30万,不上传用户数据 | 30万限制,不上传用户数据 | 300万,不上传用户数据 | 无限制,不上传用户数据 |
| 硬件绑定 | 限定机器,1个账号只能在一台固定机器使用 | 不限制机器,1个账号可在多台机器使用 | 不限制机器,1个账号可在多台机器使用 | 不限制机器,1个账号可在多台机器使用 | 不限制机器,1个账号可在多台机器使用 |
| 自动报告 | 无 | 48次/年 | 48次/年 | 96次/年 | 有 |
| 培训服务 | 线上不限 | 线上不限 | 线下一次、线上不限 | 线下一次、线上不限 | 线下一次、线上不限 |
软件为64位计算机程序,一般情况下在8G内存的普通计算机支持至少10万条数据分析/清洗,16G内存最高可支持至少15万条数据的分析/清洗。在实际使用过程中,用户使用64G内存可处理100万以上文献,256G内存24核心CPU可处理500万以上文献。
文本聚类分析,普通8G内存计算机可支撑2万条专利或论文的聚类,提高计算机配置可提高聚类专利或论文数量。
本软件提供详尽的视频教程,http://cn.ItgInsight.com/course/
本软件根据用户级别提供技术支持,线上技术支持为QQ群:908179419,对于企业级最高权限用户提供现场技术支持和培训。
V2.4.1新增功能如下:
- 图聚类增加轮廓系数确定最优类别数后再聚类
- Txt导出到Excel增加了doi和引文数据的导出
- 比较矩阵增加默认节点的染色,按照名称染色
- 自动报表增加无offcie安装情况下输出
- 机构词表的数据清洗顺序,先用正则清洗,再用替换清洗,再用正则清洗,针对CNKI的机构数据增加该功能;同时,一个机构可以划分到两个或两个以上分组
- 手工分组的默认分组为文本最短的记录
V2.4.0新增功能如下:
- 自动报告添加ifcount判断,针对时间仅有一年或者没有情况,趋势、演化、突破进行判断再分析
- 过滤器增加Doi单独字段,对应的文档也增加了Doi字段
- 增加了更改秘密功能
- 增加类别的指纹处理,项目、省份、出版物的指纹处理
- 增加语言设置序列化,更改语言后,下次启动保留上一次选择;增加了外观设置序列化,更改外观后,下次启动保留上一次选择
- 自动报告增加图片封皮,文字颜色设置,增加NSTL论文和专利报告
- Dataset增加了ReferenceNumber和ReferencedNumber字段,对应可视化也增加了相关数字的显示,但与数据分析部分的数字显示有出入,需要对参考文献和引证文献进行严格清洗
- 数据清洗部分的可视化节点备注、数字可显示
- 修复2ITGN功能Bug
V2.3.0新增功能如下:
- 边由整数改为浮点数
- 自动报告功能,针对个人用户增加微信支付
- 社区版、学生版放开临时授权,通过微信支付增加数据分析上限
- 增加SVG格式矢量图
- 修正Dataset处数据读取时使用词表后,不去重复导致一、二、三作者统计数据差异的BUG,修正词表r|A|B只提取B不提取A的bug
- 验证服务器修改,自动报告计数功能
- 增加DataSet保存为Excel格式,删掉保存为DatasetRar格式
- 修复excel表头有空格时不能识别的bug
- 节点列表与DataSet的CheckBox过滤增加了三种状态选择
- 2Excel功能分为展示和保存两种模式
- 速度优化,数据分析速度优化,提升至少3倍速度
- 演化分析中主题词演化,词的频率改为文档频率
- 验证服务器支持多个服务器,软件启动时会自动选择第一个可用的验证服务器
- 修正自动报告矩阵图中,行列一致时不出图的bug,比如专利原创国和受理国一致不出图的情况
V2.2.0.新增功能如下:
- 增加项目耦合、项目引证关系可视化
- Dataset页面增加菜单栏,可视化,转ITGN,分组统计
- 数据分析的四种词典处理方法,词表+分词与分词+词典改成一致,主要看词表的设置,词表可以实现删除、替换、正则替换、新增(自定义词提取)
- 数据清洗部分:分词+词表,词表+分词两种模式后台改成一致,具体使用哪种方法由词表内容决定
- Bug修改:省份无顺序导致合作分析排序不准确,Doc To Excel无排序
- 增加Wos5、Wos6两个过滤器,分别实现作者、机构带地址进行提取,同时SCI的机构字典,允许多重替换:即一个机构可以替换为两个以上新的机构名,按照新机构名字在字典中的排序进行顺序替换
- Dataset增加通信作者、机构、国家,及其对应的分组、统计、聚类
V2.1.0.0新增功能如下:
- 增加突破分析
- 开放SCI/SSCI二级单位过滤器
- 数据清洗增加分组统计
- 在Dataset页面增加Doc To Excel,Doc To Txt,数据清洗读取数据的2Excel方式修订,速度加快
- 增加bigdataset,Sqlite模式,单台计算可处理百万级数据
- 作者、机构、关键词增加语义指纹,和快速模式数据清洗
- 节点名称修改支持多个正则表达式替换
- Dataset数据查询增加组合查询
- 节点名称修改替换,增加正则表达式批量替换
- 自动分组,增加正则表达式批量替换
V2.0.0.0新增功能如下:
- 数据请清洗读取的数据量和读取时间性能提升50倍以上,自动分组速度提升5倍以上
- 数据清洗页面,元数据页面整合到主页面;增加浅色和深色外观
- 增加技术竞争力指标
- 增加Recluster功能、节点分组、聚类的修改
- 增加聚类图与DataSet之间的交互,标签修改ReTag功能
- 增加Kmeans(N)聚类
- 增加聚类结果自动打标签功能
- 数据清洗增加对四种模式的分词处理
- 数据清洗时,增加只读第一作者/第一单位/第一国家等读取设置
- 增加PCA、KPCA降维
- 增加ToReference功能,即将文献著录项目转化为参考文献格式
- 可视化文字增加大小写转化 2Upper,2Lower,2Cameral功能
- 组合分析结果增加txt格式数据输出,节点列表增加2Txt,避免excel格式输出时,由于office安装问题引起的闪退
- 修正演化图保存mod文件格式不完全的BUG
- 修复节点过小引起的闪退BUG
- 修正了技术主题图重绘后,Tag标签位置没变化的BUG
- 修复进度条假死bug
- 白名单验证模式,对高校范围内的IP地址批量授权
V1.9.1.0新增功能如下:
- 字典增加大写、小写、大小写混合、首字母大写等模式;正则表达式筛选
- 修订中介中心度计算
- 增加中英文混合的数据分析,词长度阈值分中文、英文两个参数
- 增强快捷键的操作
- 优化数据读取速度,在大规模数据和大规模词典应用时,读取速度提升40%左右
- 增加聚类主题地形图
- 增加图密度指标
- 英文词语全部按照单数处理,并且增加词表的正则表达式替换功能
- 增加Scopus数据支持
- 删除世界地图和中国地图的背景,仅保留坐标布局,删除中国省份地图布局
- 集团用户登录数量提示
- 修正数据清洗,中文分组中有多余空格的问题
V1.9.0.0新增功能如下:
- 增加图例,在PPT中绘制图例
- 过滤器中的摘要和关键词字段支持多个字段合并,用|分割多个字段
- 自动报告增加Patsnap、Incopat、Innovation数据源支持
- 自动报告表格居中
- 当数据时间字段缺失时,可视化去掉了1900的数据
- 增加对高被引论文的过滤,通过设置Number1、Number2、Number3阈值来过滤论文或专利中高被引、高同族数据,使得仅超过Number1、Number2、Number3阈值的数据才会被分析、被清洗
- 增加针对单个机构文献数据的自动分析报告模板,多个机构文献对比分析的自动报告分析模板
- 字典增加了反向筛选功能,即只有词表中含有的人名、机构、国家、省份、类别、关键词等,才进入分析
- 增加绘图机器人操作,一次性绘制所有可视化图形
10)自动分组部分时在状态栏增加进度提示
V1.8.0.0新增功能如下:
1)增加class3、class4
2)优化自动报告引擎,关联分析部分,报告模板组件构成
3)aiReview.onlie\SciReport.online服务开通
V1.7.0.0新增功能如下:
1)项目合著分析
2)分析部分,删除了孤立点相关的处理操作
3)单IP提醒功能
4)增加LinLog布局,并设定为首选布局
5)自动报告改为全自动,生成单独系统ezReport,并设立独立权限
6)增加默认的参数最优化设定,后台计算
7)过滤器中的摘要字段支持多个字段合并,用|分割多个字段
V1.6.0.0新增功能如下:
1)增加了元数据功能,类似于GELPHI的增加列
2)增加了6种主题图的表现形式,类似于VOSViewer的主题图
3) 增加了聚类密度图
4)增加了标签防重叠功能
5)增加了节点大小对比度参数sizevariation
6)增加了面板边框大小设置,目的:截取密度图、热力图、聚类图,能够截取全部图形
7)增加坐标直接导出功能
8)增加数据链的功能,即在数据清洗模块增加Go To Related功能
9)增加了TSNE布局
10)增加浮动窗口
V1.5.0.9新增功能如下:
1)新增节点大小批量修改功能
2)增加普通电脑进行高清截图功能
3)增加SCI论文自动报告功能
4)版本划分为:学生版、学术版、教学版、企业版、集团用户版、军工版、内网版
5)增加批量“显示或隐藏节点名称”功能
6)修正BUG:配置文件错误强制退出
7)运行用户自定义密度图颜色
8)增加全英文自动报表,全英文用户手册
V1.5新增功能如下:
1)新增三维统计
2)新增数据清洗后文档聚类,密度图可视化
3)新增智能报告
4)增加了docadapter模式,读取数据不分析;再次读取docadapter后再分析的模式
5)增加网络图的凸包覆盖
6)增加集团客户免注册功能
7)增加.netx格式文件的处理
8)增加图形左右、上下翻转功能
9)增加excel格式的频数矩阵、相似矩阵、皮尔森矩阵可视化
V1.3新增功能如下:
1) 新增主题演化分析,跟踪技术的产生、消亡、增强、减弱、聚合和裂变的过程
2) 新增机构、作者、国家、省份、关键词、技术类别演化分析,拓展主体演化分析范围
3) 新增SPC主路径指标,识别技术发展过程中的关键技术节点
4) 增加人名的同名异指和异名同指的计算机识别
V1.2新增功能如下:
1) 全新报表引擎,一键输出近百张分析报表,全方位洞悉数据特征
2) 增强语义分析,自动识别相似主题词,相似机构名,人名,地名
3) 智能组合分析,任意二维、三维数据矩阵,跨维度跨层次可视化
4) 优化渲染技术,增加技术云图,知识扩散,功效矩阵,中国各省地图
- 操作系统:
Window7、Windows8、Windows10、Widnwos11桌面操作系统,Windows Server2016以上服务器操作系统,推荐64位操作系统为宜;office2013或以上;32位软件对应32位版本office,64位软件对应64位office
- 硬件配置:
内存:1G以上;硬盘:100M以上;CPU:主频1G以上。
绿色版不需要安装,非绿色版按照如下过程安装
- NetFramework4.5 安装,如果计算机无NetFramework4.5,需进行网络下载安装。系统会自动连接网络进行下载,无需用户做特定操作。
- ItgInsight下载地址为http://cn.ItgInsight.com/download/,ItgInsight绿色版不需要安装,解压缩后直接找到.exe文件即可运行。非绿色版安装,点击安装文件夹下的对应版本的setup.exe文件,顺序弹出如下对话框(不同版本安装页面略有不同,但过程一致):
绿色版直接删除文件夹即可。
非绿色版卸载,点击开始菜单,找到ItgInsight卸载,如下图,推荐采用此方法进行卸载。

也可以在控制面板进行下载,打开“控制面板”🡪“添加删除程序”🡪“更改或删除程序”,在“当前程序中”找到ItgInsight,如下图,不推荐控制面板卸载,因为可能会遗漏未卸载内容
点击“删除”按钮即可。
系统安装后将在“桌面”和“程序”中放置启动的快捷方式,如下图所示:

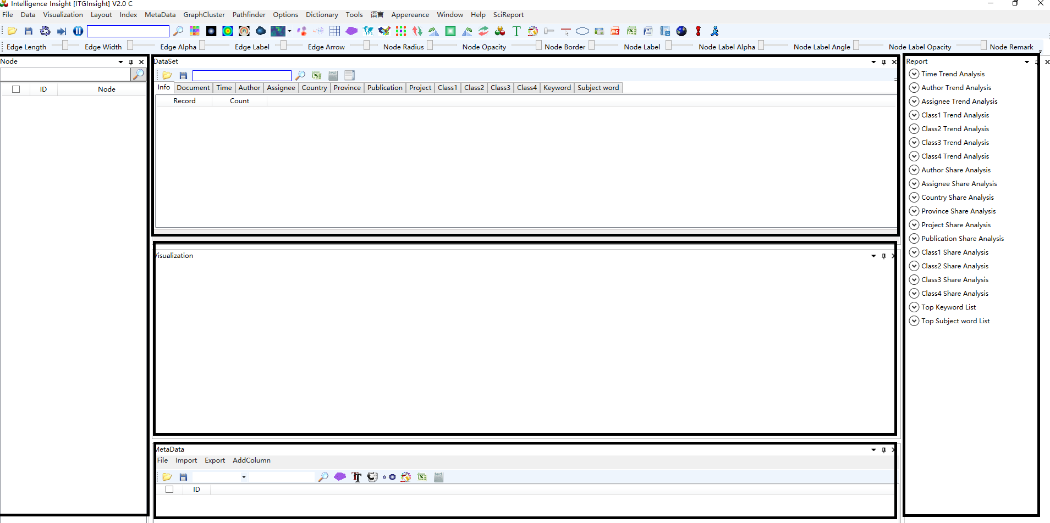
启动后,软件主要窗口区域包括可视化区域、数据集区域、元数据区域、节点区域、报告区域,如下图所示,默认只显示可视化区域、节点区域、报告区域,通过菜单栏的Window/窗口按钮,进行各个区域的显示设置。
软件支持浅色和深色两种外观,通过菜单栏的Appereance外观按钮进行切换,深浅外观如下图所示,每次更改后,下次启动将以更改后的外观进行显示。
一般情况下,系统仅需网络注册,极特殊情况需要本地注册+网络注册。如果软件能够正常启动,说明本地注册已完成,只需要网络注册。绿色版一般都不需要本地注册。
社区版/学生版不需要任何注册。非社区版/学生版需要网络注册。
软件能够启动,则不需要本地注册。
1)运行软件安装目录下子目录hid中的HID.exe文件,得到计算机的序列号:

2)将“机器码”连同“机构”、“用户”、“邮箱”等信息一起发送到客服邮箱;
3)客服在收到注册信息并通过验证后,发给具有时间限制的授权文件到用户邮箱。
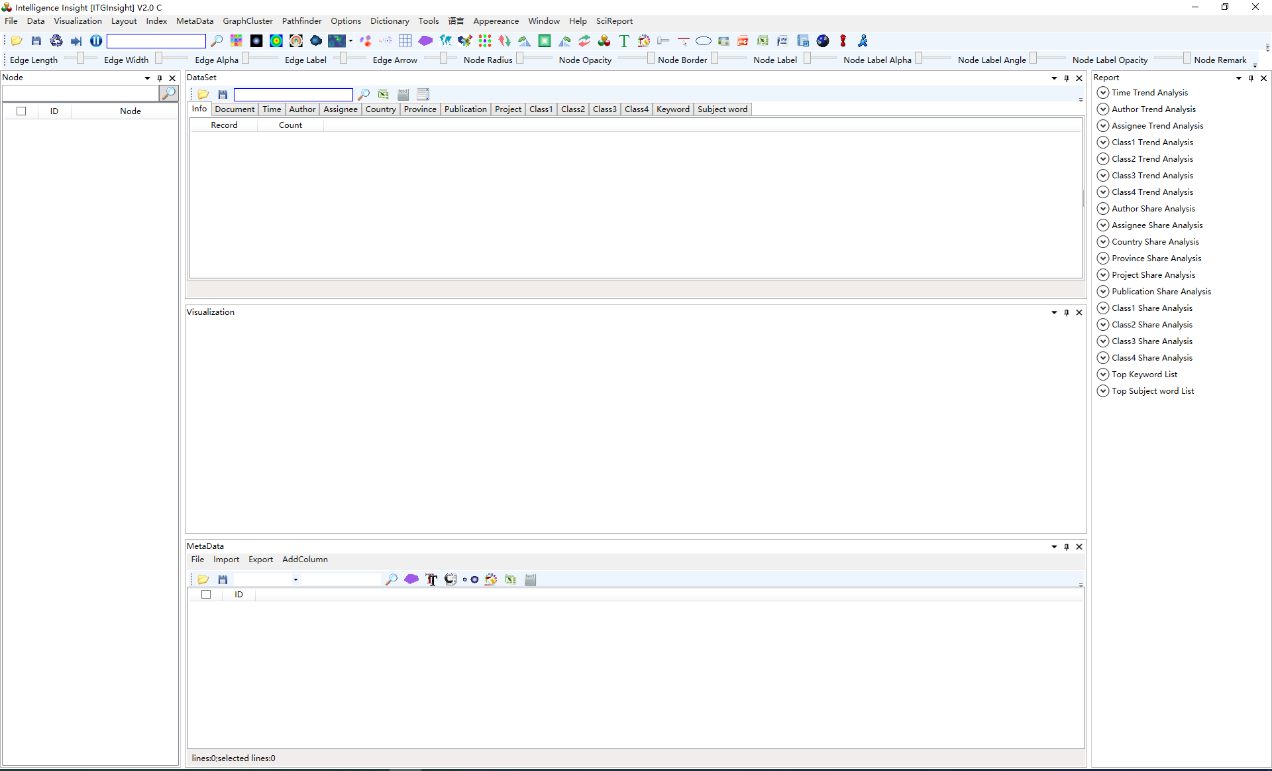
未进行本地注册的用户在使用时会定时弹出“授权警告”窗口,如下图,
4)软件技术支持QQ群:908179419,www.ItgInsight.com会发布通用的本地注册文件,该授权不与计算机硬件绑定,任何用户均可进行本地注册。
非社区版/学生版需要网络注册
1)完成本地注册
2)运行软件,点击help->register弹出如下画面
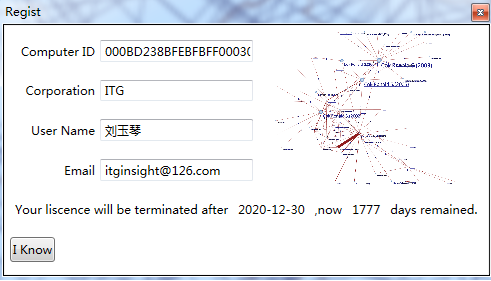
3)将“机器码”连同“机构”、“用户”、“邮箱”等信息一起发送到客服邮箱,由客服完成网络注册。或者采用2.8节商业授权方式,输入用户名密码进行注册。
4)未进行网络注册的用户,软件只有社区版/学生版的对应的权限。
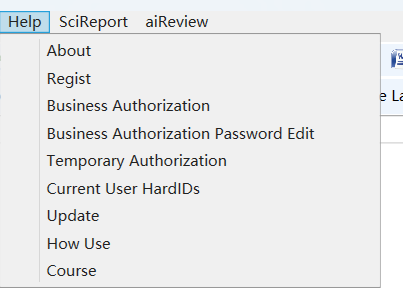
集团客户按照2.8节商业授权进行注册,当同时登陆用户数量超过集团购买数量,软件启动后会弹出当前登录用户总数量情况。比如,集团购买5个账号,仅能保证5个人同时在线。在集团用户登录时,会对登录情况进行验证,如果达到用户上限,系统提示当前达到上限,并显示已经登录的硬件ID,当前用户可以对已经登录的硬件ID进行强制退出,否则当前用户登录后也会由于达到用户上限被退出。集团用户登录后也可以通过帮助查看所有已经登录使用的用户硬件ID,如下图。

内网(保密)版需本地注册,无需网络注册,一机一码,无需联网,适用于对数据敏感或者有保密资质的单位使用。
点击“help/帮助”->“update/更新”,在联网的环境下,系统会自动检查软件版本,进行系统升级,如果在线升级较慢,建议到技术交流群或者资源网站下载最新版。
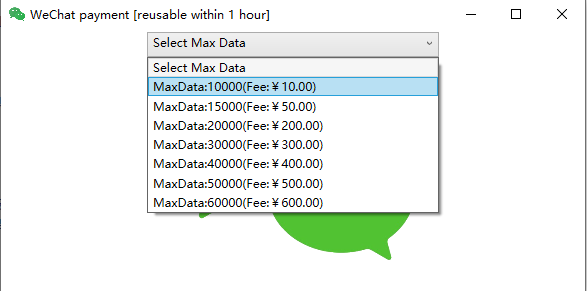
对于社区版/学生版有数据分析量限制,通过点击帮助->临时授权,进行微信支付可提高数据分析数量,如下图所示。临时授权有效时限为1小时,1小时内分析和清洗数据都可以按照相关支付金额进行数据处理。
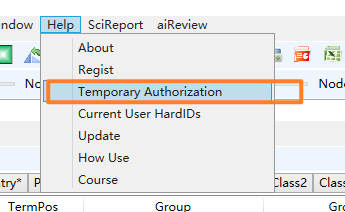
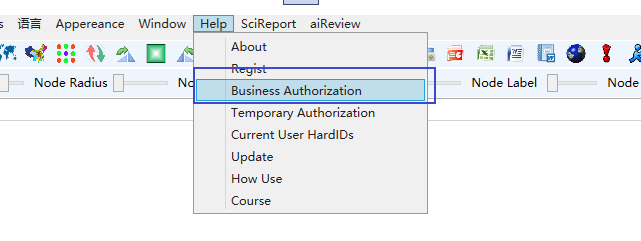
企业版、研究版用户通过商业授权下载授权文件,每次软件升级后,或者安装新的计算机,不需要再拷贝授权,点击软件工具栏的帮助->商业授权,如下图,输入用户名密码(购买时提供)即可完成授权。使用软件时以管理员身份运行本软件。
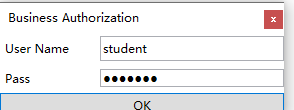
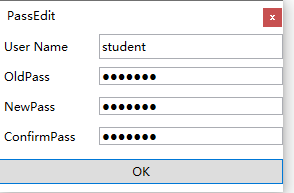
如果需要修改初始密码,点击商业授权密码编辑,如下图,进行密码重置
软件需要联网进行正版验证,验证服务器地址在软件目录下的webserver.txt中,如下截图,第一行为首选验证服务器,其他为备选,当第一个验证服务器故障时会连接第二个,以此类推。

应用ItgInsight进行数据分析,首要的工作便是将文献数据转化为ItgInsight特有的数据格式,并应用数据转化功能进行数据分析。
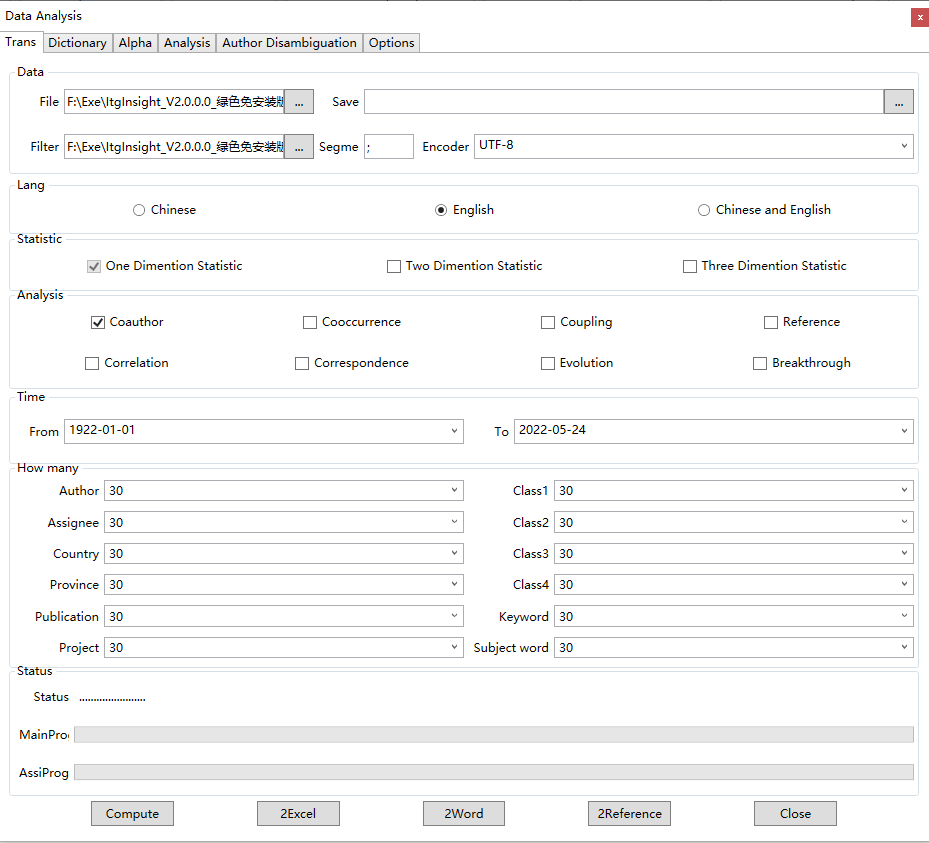
点击菜单栏上的“Data/数据->Analysis/分析”,弹出数据转化页面,如下图:
“Data数据”标签下的“File/文件”处,点击
![]()
,弹出数据导航对话框,选择数据来源,如下图:
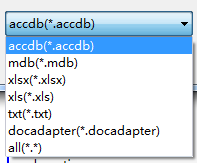
系统支持由CNKI下载的中文核心期刊数据,参考安装目录下的example_data_cnki.txt;由Web Of Science下载的SCI论文数据和德温特专利数据,参考安装目录下的example_data_wos_sci.txt;由专利检索分析系统Patsnap、Innocopat、Innovation等导出的专利。数据文件可以是Excel03、07及以上格式,Access03、07及以上格式,txt格式。同时,数据文件也可以是docapadter格式,该格式是由ItgInsight生成的数据文件。
在“Filter/过滤器”处,点击
![]()
,弹出过滤器选择导航对话框,选择过滤器,如下图:
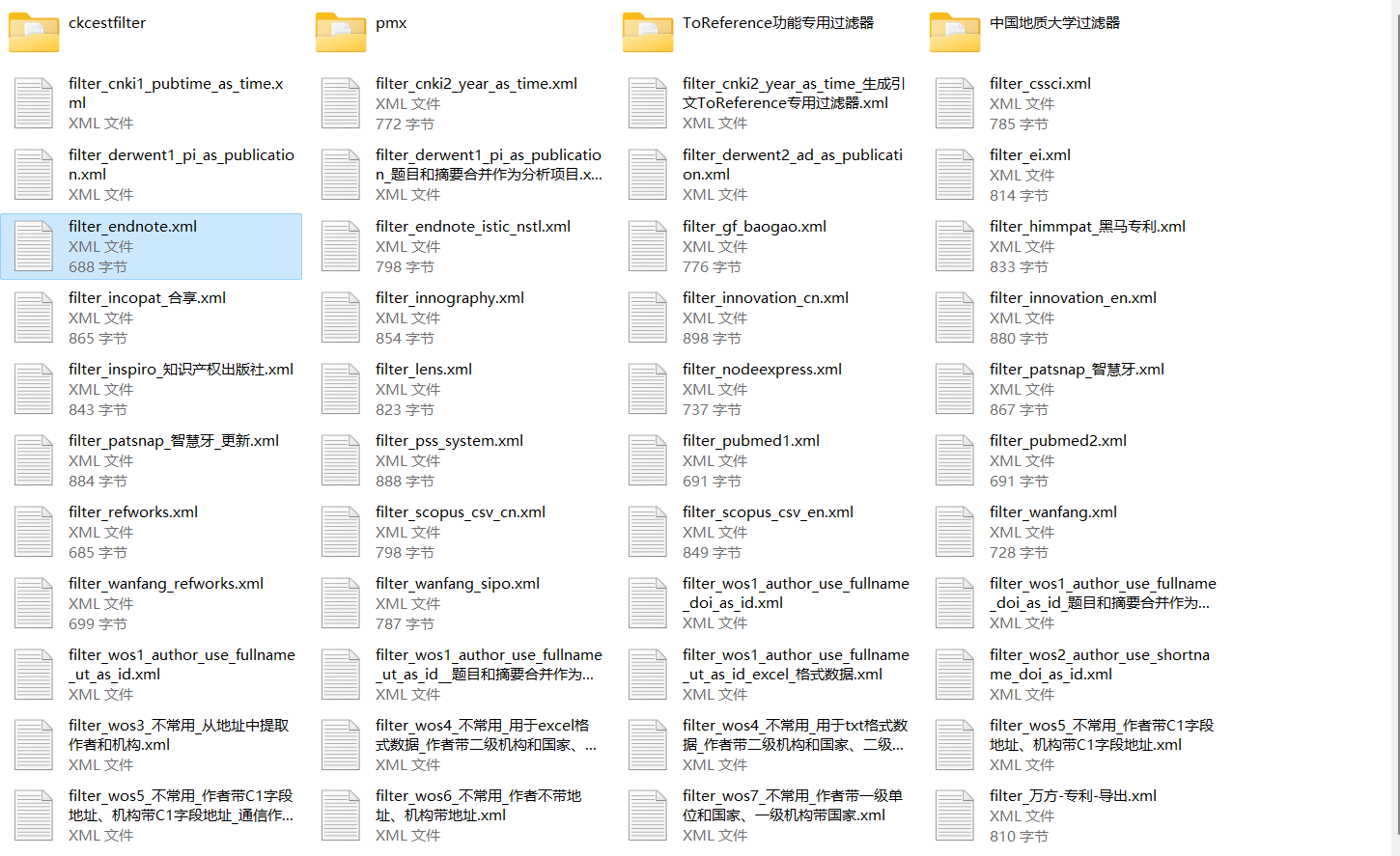
从中选择过滤器。比如,当数据是由Web of Science 导出的SCI/SSCI数据,过滤器就选择为filter_wos1_author_use_fullname_doi_as_id.xml,以此类推。
在“Segment/分隔符”一栏填写分割符号,系统默认为“;”,如果有多个分割符,同时在该处填写。
当被分析对象的一个记录中含有多个记录,比如“作者”,在数据库中一条记录有多个作者,并且用“;”分割,那么在分析时,系统会依据这个“;”分隔符把所有作者识别出来。
当选择的数据为文本txt格式时,“Encoder/编码”一栏发挥作用,系统根据编码内容进行文本的解析,如果Encoder的设置与数据txt的真实编码不一致,系统会无法正确分析文本内容。“Encoder/编码”的设置可以下拉选择,也可以手工输入。
“Save/保存”一栏,点击
![]()
,填写文件保存的路径和文件名,系统默认itgn为文件后缀,该文件是用以进行可视化分析的项目文件。
在“Statistic/统计”标签下,选择统计分析的维度,一维统计为必选项,二维统计、三维统计为可选项;当选择后面的关联分析后,二维统计自动成为必选项;当选择二维统计、三维统计后,分析时间会有所增加。
在“Analysis/分析”标签选择要进行的分析内容,“Coauthor/合著分析”“Cooccurrence/同现分析/”“Correlation/关联分析”“Correspondence/对应分析”“Reference /引证分析”等,可多选。
在“Time/时间”标签设定被分析数据的起止时间。
在“How many/多少项”标签下,输入将要分析的机构(*表示通信机构)、作者(*表示通信作者)、国家(*表示通信国家)、类别、期刊、关键词、摘要词数目,分析数目按照数量多少排序。
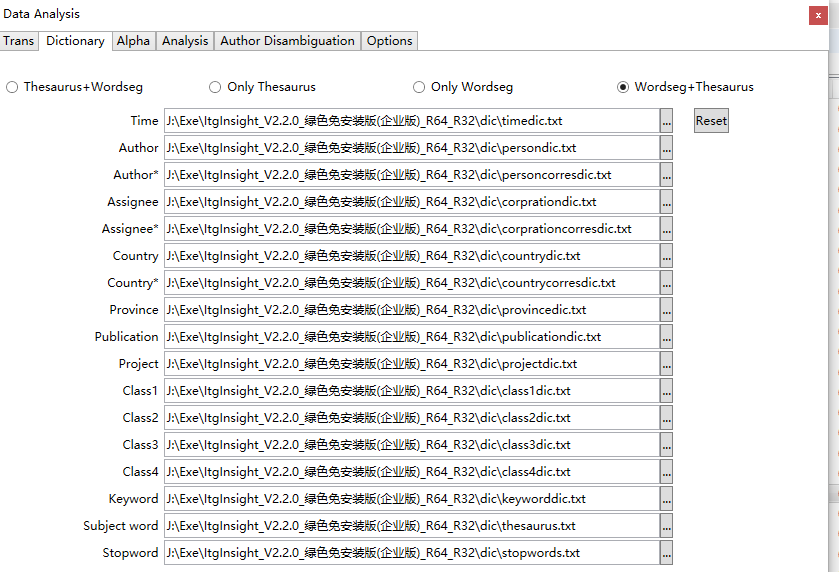
切换到Dictionary标签,如下截图:
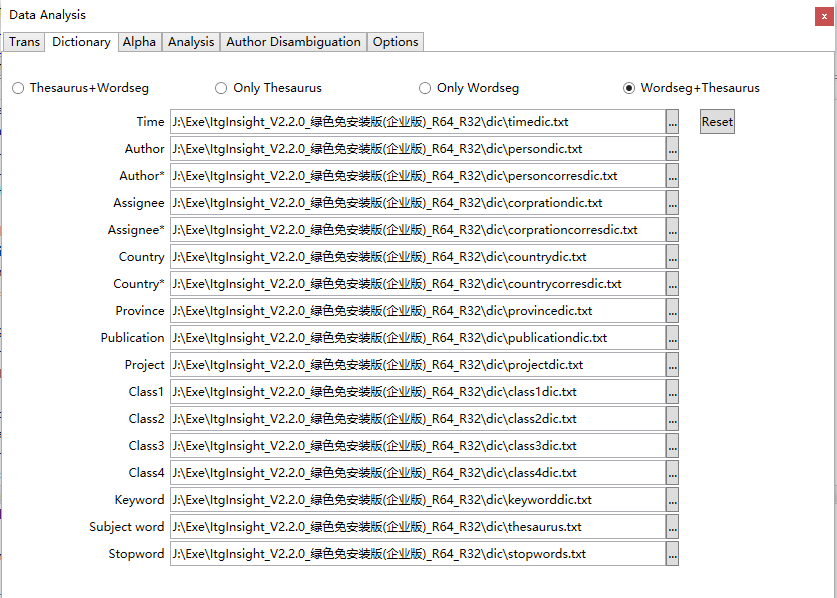
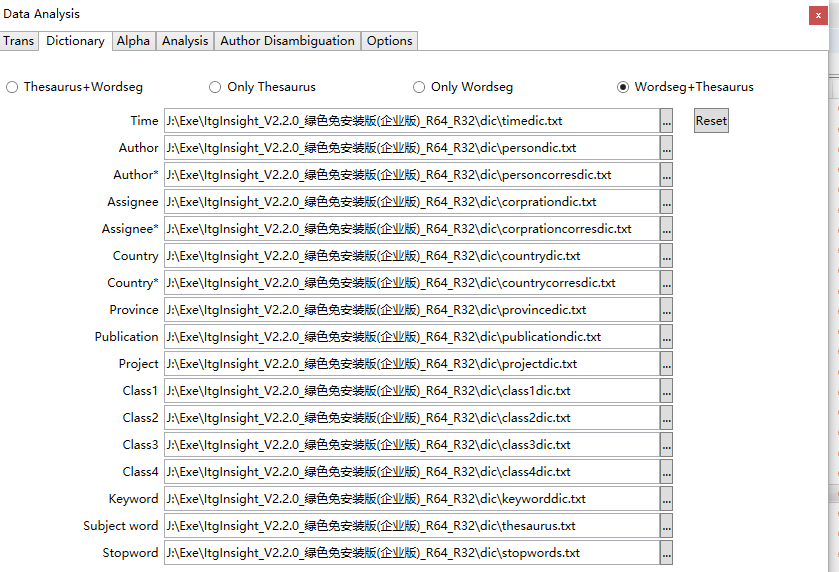
选择字典,首次使用用户可以到软件安装目录下dic目录中找到相关的字典文件。
其中对于主题词采用“词表+分词”、“仅用词表”“仅用分词”、“分词+词表”四种模式;
词表+分词:主题词提取过程,先提取词表里的词,再分词;仅用词表:只提取词表里的词;仅用分词:仅分词;分词+词表:先分词,再提取主题词表里的词。
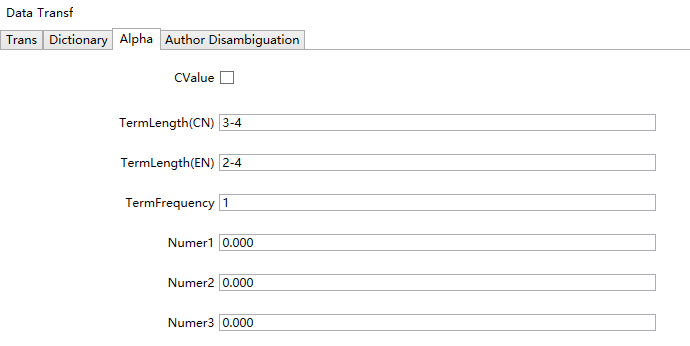
切换到Alpha标签下,如下截图:
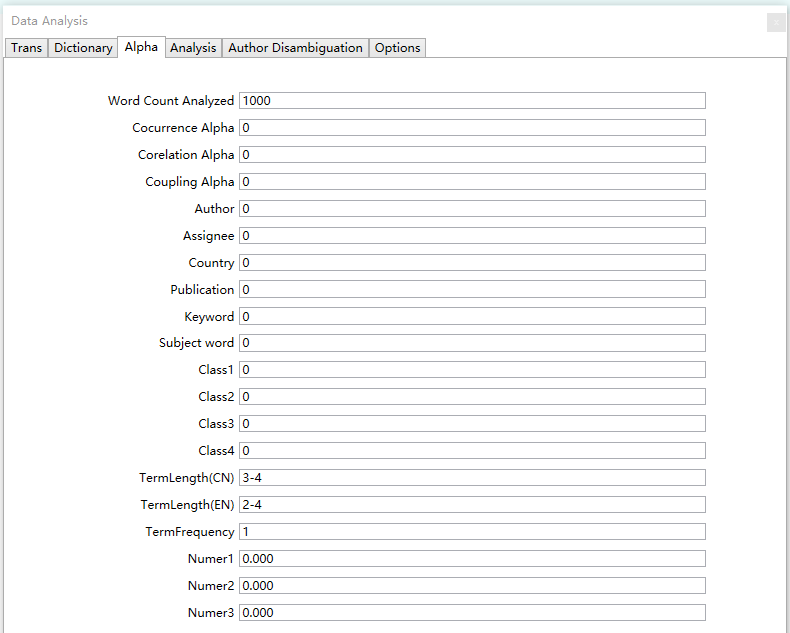
首次使用用户,保存默认不变。其中,TermLength和TermFrequency是提取主题词的词长、词频限制,英文建议词长取2,中文词长取3,当数据量比较大时提高词频阈值可以加快分析速度。
Number1的阈值含义:以SCI论文为例,当Number1设置为3时,如果被引次数超过3,参与分析;低于3的论文会被过滤掉,不参与分析。以此类推,设置Number2、Number3的阈值,但建议这两个设置0。
切换到Analysis标签下,如下截图:
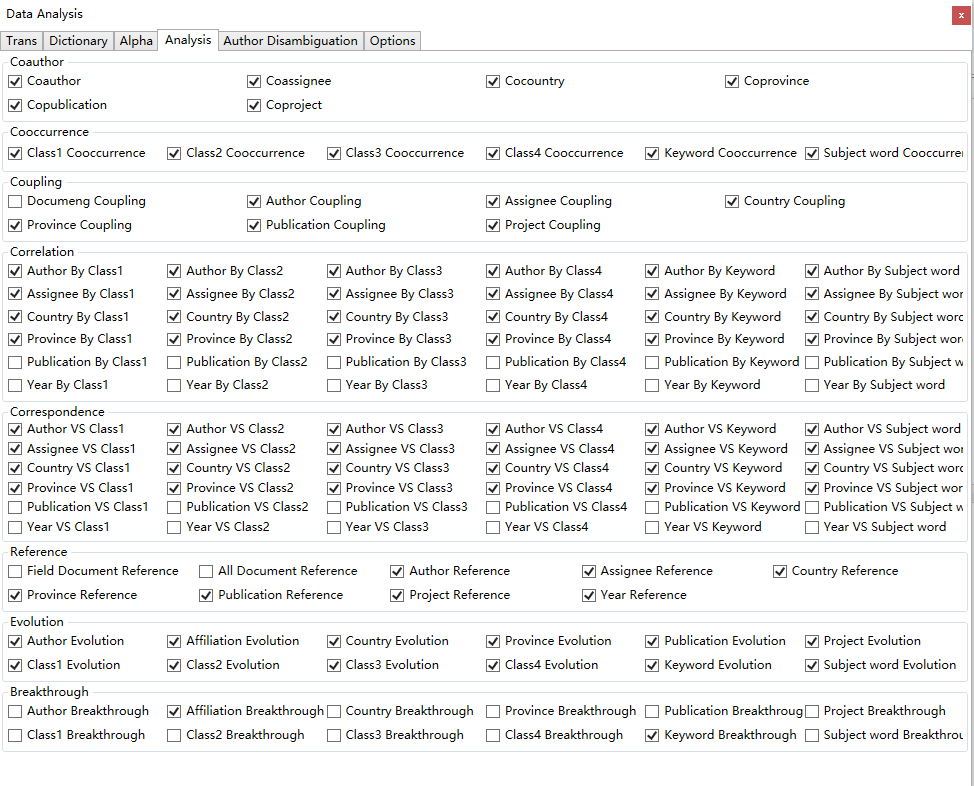
首次使用保持默认不变,如果数据量较大,Document Reference/文档引证分析会耗费较长时间,该项去掉后,分析时间会加快。
Author Disambiguation/作者消歧标签如下:

含义是说,如果遇到同名异指,即同一个名字不同人的情况,如何处理,默认No/不区分,认为是一个人。如果选择Assignee/机构,则进一步区分作者是否为同一个人,看文献的机构信息,其他字段选择的含义类似。
切换到Options/选项标签,如下图:

Save Document Adapter的意思是:读取数据完成后保留数据分析结果,这个中间结果以.docadapter为后缀,后续可以将这个文件作为输入,进行二次分析。
Apply PFNET是分析过程中是否采用PFNET进行网络图压缩,默认即可。
最后切换到Trans/转换标签,点击“OK/确认”按钮,“MainProgress/主进度”、“AssiProgress/辅进度”和“Status/状态”处将显示后台数据转换的情况。
点击菜单栏上的文件菜单项,或点击工具栏上的打开按钮,如下图:

弹出文件导航对话框,导航到要分析的itg项目文件,进行文件读取。

读取itgn项目文件后,系统主页面右侧的基本统计部分显示出一些基本的维度统计结果,可视化区域需进一步按3.3-3.9的操作方式指定分析内容,才能进行可视化结果的输出,如下图。

评估研究影响力: 合作分析可以用来评估学者、研究机构或国家在学术领域中的影响力。通过分析合作关系网络,可以识别那些在合作中具有关键地位的学者或机构,从而更全面地评估其贡献和影响。
发现研究趋势: 通过观察合作网络的演变,可以发现研究领域内的趋势和动态。合作分析有助于识别研究团队的形成、发展和变化,帮助研究者了解不同领域内的合作关系模式。
寻找潜在合作伙伴: 合作分析可用于寻找潜在的合作伙伴。通过识别在相同领域有相似兴趣和研究方向的学者或机构,研究者可以建立更广泛、有益的合作关系,促进知识的交流和共享。
评估研究领域发展阶段: 通过合作分析,可以了解一个研究领域的发展阶段。新兴领域可能呈现出不断形成的小规模合作网络,而成熟领域可能有更大规模和复杂的合作网络。
识别研究热点: 合作分析有助于识别当前研究领域的热点问题。通过观察合作网络中的关键节点和研究者之间的合作关系,可以发现正在引领领域发展的研究方向。
科研政策制定: 合作分析的结果可以为科研政策的制定提供支持。政府或研究机构可以根据合作分析的结果来调整资金分配、研究方向的引导,以促进更有效的合作和研究。
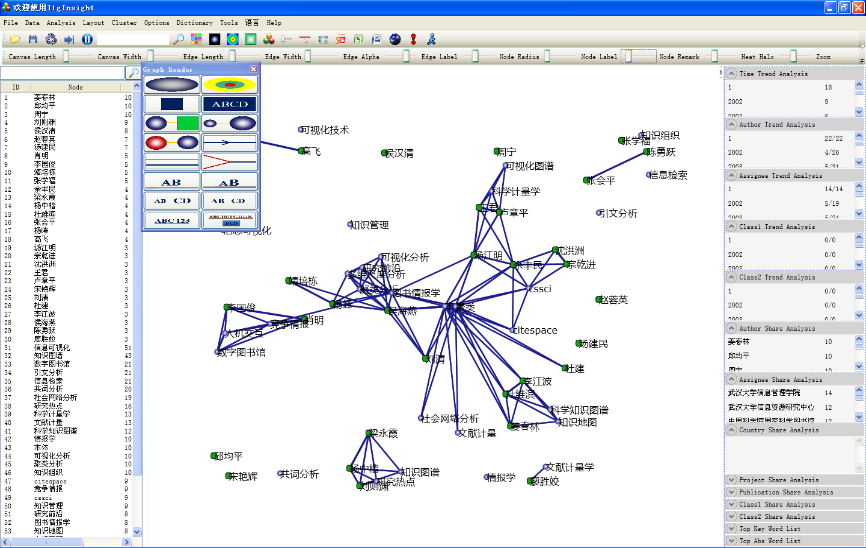
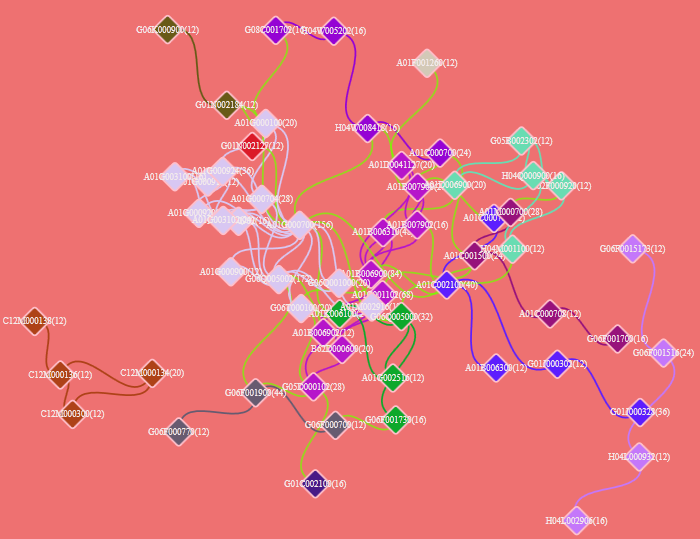
1)点击菜单栏“Visualization/可视化”——>“Cooperation/合著网络”——>“作者合著/机构合著/国家合著/省份合著/出版物合著”,如下图。
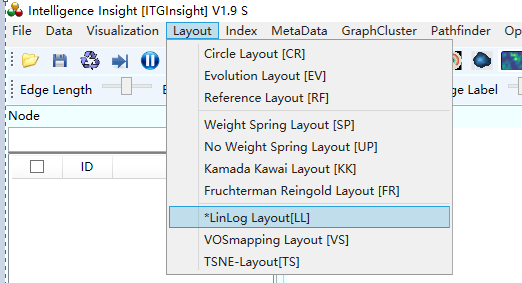
2)点击菜单栏“Layout/布局”——>“CR布局/EV布局/RF布局//UP布局/SP布局/KK布局/FR布局/LL布局/VS布局/TS ”,如下图。布局算法选择以图形是否美观、易读为标准,默认选择LL布局算法,即可满足绝大多数情况下的可视化。
3)点击工具栏
![]()
,初始可视化分析图形,如下图。
3)点击工具栏
![]()
,启动图形优化。
4)在图形优化过程中,点击工具栏
![]()
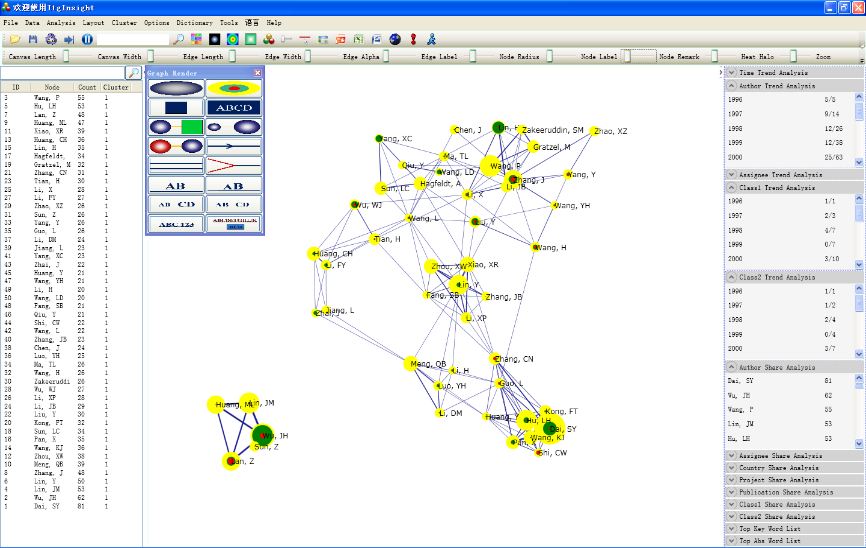
,停止图形优化,以得到更加简洁清晰的可视化分析结果,如下图。
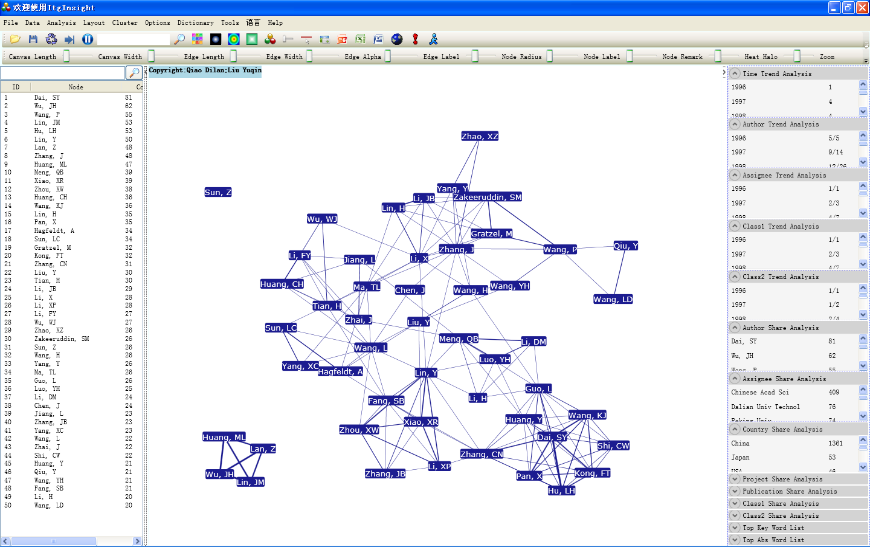
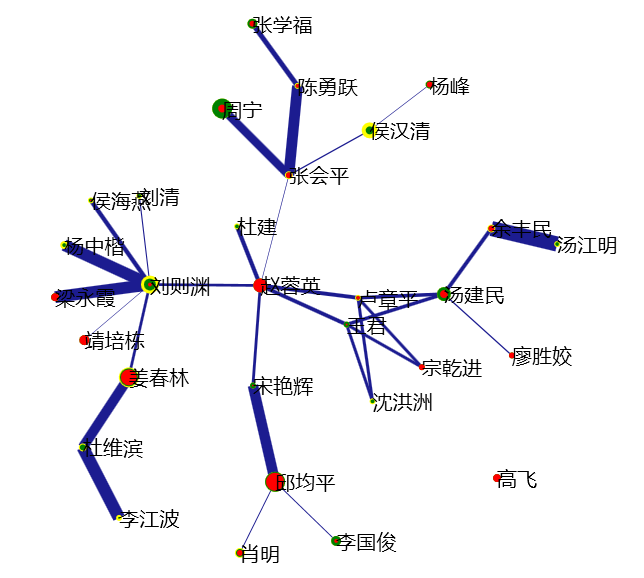
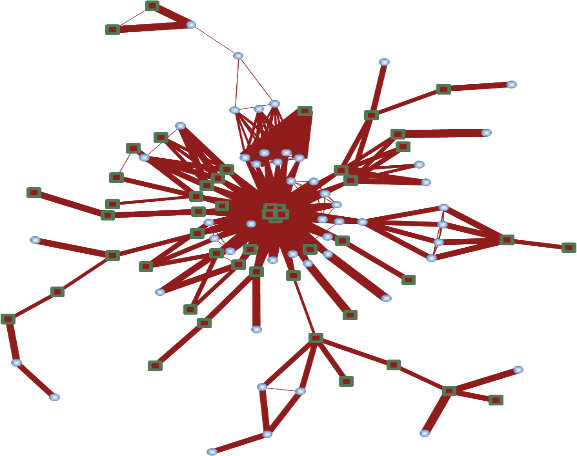
5)应用本手册后面的“图形样式设置”、“滑块设置”进行图形的个性化设计,下图为合著关系的典型可视化结果。
揭示主题关联性: 通过分析文献中主题词的共现关系,可以揭示不同主题之间的关联性。这有助于研究者了解不同主题领域之间的交叉点,发现新的研究方向。
发现研究热点: 主题词共现分析有助于发现文献中的研究热点。当某些主题词在同一文献中频繁共现时,这可能表示这些主题目前在学术界受到关注,是研究的热点。
追踪学科演变: 通过分析主题词的共现关系,可以追踪学科领域的演变过程。这有助于了解一个领域的发展路径,发现关键的发展节点和阶段。
理解知识结构: 主题词共现分析、学科共现有助于理解知识结构和主题之间的关系。研究者找到自己的位置、了解不同领域不同学科的相互关系。
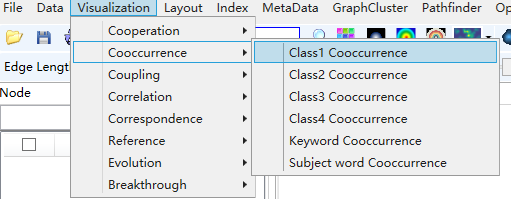
1)点击菜单栏“Visualization/可视化”——>“Cooccurrence /同现网络”——>“类别1同现/类别2同现/关键词同现/摘要词同现”,如下图。
2)点击菜单栏“Layout/布局”——>“CR布局/EV布局/RF布局//UP布局/SP布局/KK布局/FR布局/LL布局/VS布局/TS ”,如下图。
3)其余步骤与合著分析相同。下图为同现分析的典型可视化结果。
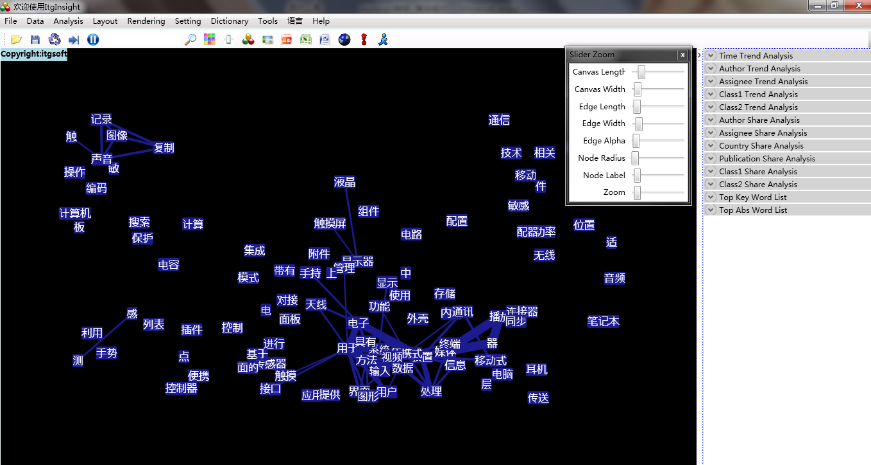
揭示研究领域结构: 耦合分析可以帮助揭示一个研究领域内不同元素(如期刊、作者、机构等)之间的关联和相互影响。通过分析这些关系,可以了解研究领域的结构,识别主导力量和关键节点。
评估学科发展: 耦合分析有助于评估学科的发展情况,识别学科内的主要研究方向、研究热点和发展趋势。这有助于科研人员、政策制定者和机构更好地了解学科的动态,为未来的研究方向提供参考。
科研政策制定: 通过耦合分析,可以了解科研政策对不同研究元素的影响程度,为科研政策的制定提供依据。这有助于合理配置科研资源,促进科研体系的健康发展。
发现潜在合作机会: 耦合分析可以揭示不同研究者、机构或国家之间的潜在合作机会。通过了解彼此之间的关系,科研人员可以寻找合作伙伴,加强科研网络,提高科研水平。
识别研究热点: 耦合分析可以帮助识别当前研究领域的热点问题和关键议题,为研究者提供选择研究方向的参考依据。
1)点击菜单栏“Visualization/可视化”——>“Coupling /耦合网络”——>“文献耦合/作者耦合/机构耦合/国家耦合/省份耦合/出版物耦合”,如下图。
2)点击菜单栏“Layout/布局”——>“CR布局/EV布局/RF布局//UP布局/SP布局/KK布局/FR布局/LL布局/VS布局/TS ”,如下图。

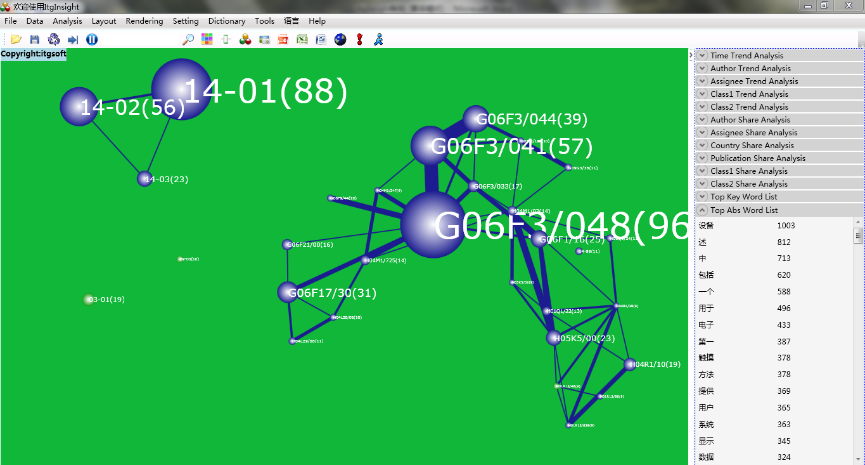
3)其余步骤与合著分析相同。下图为耦合分析的典型可视化结果。
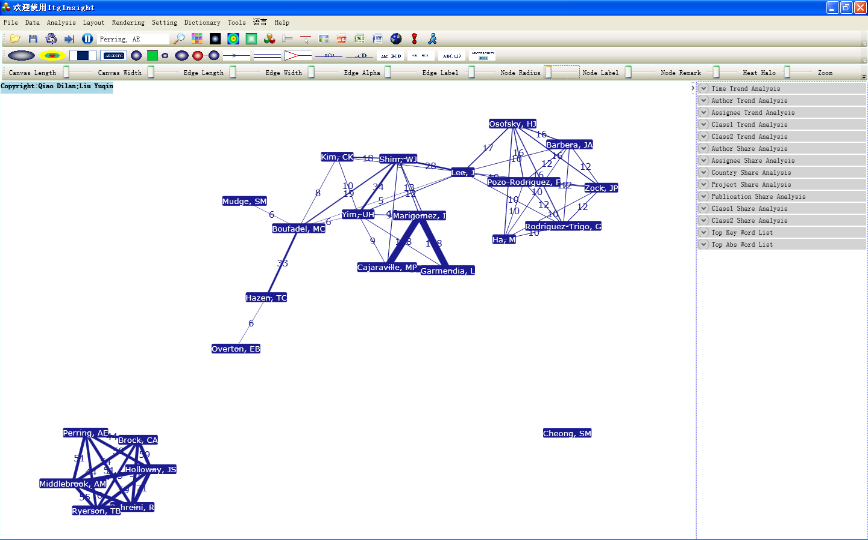
文献或者研究主体A与B之间没有合作,也没有共同引用或共同被引用,但是A与B所用的关键词或者主题词相同或相似,相同或相似的越多,关联关系越强,可以用来发现潜在合作伙伴或者竞争对手。
1)点击菜单栏“Visualization/可视化”——>“Correlation /关联分析”——>“作者关联/机构关联/国家关联/省份关联/出版物关联/年代关联”——>“作者BY类别1/作者BY类别2/作者BY关键词/作者 BY 主题词”;“机构BY类别1/机构BY类别2/机构BY关键词/机构 BY 主题词”;“国家BY类别1/国家BY类别2/国家BY关键词/国家 BY 主题词”;“省份BY类别1/省份BY类别2/省份BY关键词/省份 BY 主题词”;“出版物BY类别1/出版物BY类别2/出版物BY关键词/出版物 BY 主题词”;“年代 BY 类别1/年代BY类别2/年代BY关键词/年代 BY 主题词”,如下图。
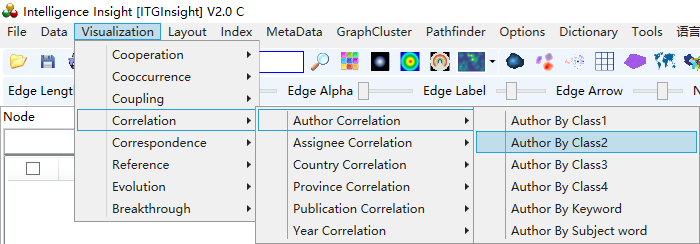
2)点击菜单栏“Layout/布局”——>“CR布局/EV布局/RF布局//UP布局/SP布局/KK布局/FR布局/LL布局/VS布局/TS ”,如下图。

3)其余步骤与合著分析相同。下图为关联分析分析的典型可视化结果。
当进行时间关联分析时,RF布局,关联图形按如下形式进行显示。
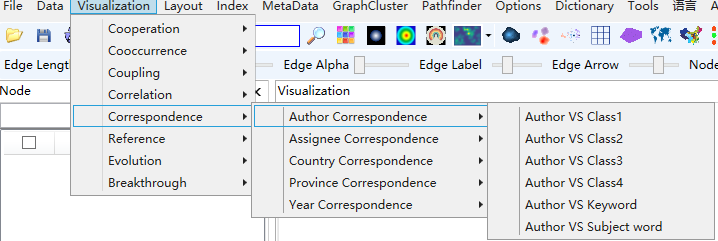
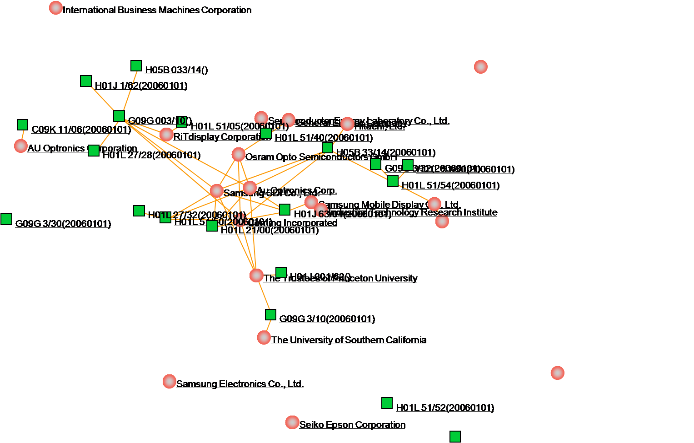
对应分析可以理解为二维或二模关联分析,同时分析研究主体之间的关联,研究内容之间的关联,以及研究主体与研究内容之间的关联,从而了解各个机构研究内容的关联性,明晰研究主体的研究重点、技术优势,发现研究主体、研究内容的进展以及相互之间的推动、促进、依存、演化关系,有利于科技发展战略的制定,研究机构的科技管理,研究者个人研究能力的提升。
1)点击菜单栏“Visualization/可视化”——>“Correspondence /对应分析”——>“作者对应/机构对应/国家对应/省份对应/年代对应”——>“作者VS类别1/作者VS类别2/作者VS关键词/作者 VS 主题词”;“机构VS类别1/机构VS类别2/机构VS关键词/机构 VS 主题词”;“国家VS类别1/国家VS类别2/国家VS关键词/国家 VS 主题词”;“省份VS类别1/省份VS类别2/省份VS关键词/省份 VS 主题词”;“年代 VS 类别1/年代VS类别2/年代VS关键词/年代 VS 主题词”,如下图。
2)点击菜单栏“Layout/布局”——>“CR布局/EV布局/RF布局//UP布局/SP布局/KK布局/FR布局/LL布局/VS布局/TS ”,如下图。
3)其余步骤与合著分析相同。下图为对应分析分析的典型可视化结果。
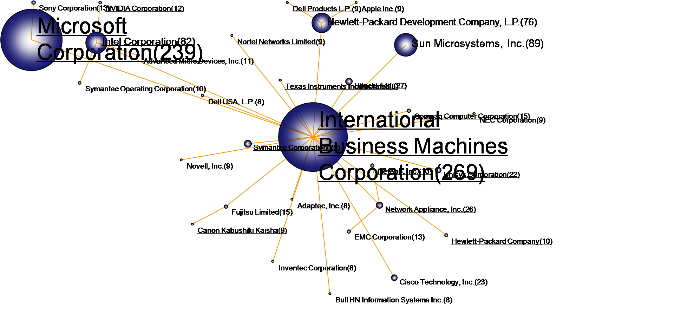
文献引证信息的分析在所有的情报分析方法中占有非常重要的地位,除了依据引文进行学术主体关联关系揭示外,在情报分析领域中有诸多其它方面的应用。
通过文献的被引证数量统计可以发现特定技术领域中重要核心文献的分布,进而开展科技成果评价;
通过跟踪文献的被引证信息可以发现竞争对手和潜在竞争对手及其技术研发策略;
通过回溯文献的引证信息可以揭示文献的初始思想来源;通过文献间引证与被引证信息的综合可以揭示文献间相互联系、相互影响与相互促进的关系;
通过分析引证文献和被引证文献所解决的科学问题与创新性可以揭示特定技术或主题内的知识流动、扩散与融合的路径。
1)点击菜单栏“Visualization/可视化”——>“Reference /引证分析”——>“领域文献引证/所有文献引证/作者引证/机构引证/国家引证/省份引证/出版物引证/年代引证”,如下图。
2)点击菜单栏“Layout/布局”——>“CR布局/EV布局/RF布局//UP布局/SP布局/KK布局/FR布局/LL布局/VS布局/TS ”,如下图。
3)其余步骤与合著分析相同,下图为引证分析的典型可视化结果。
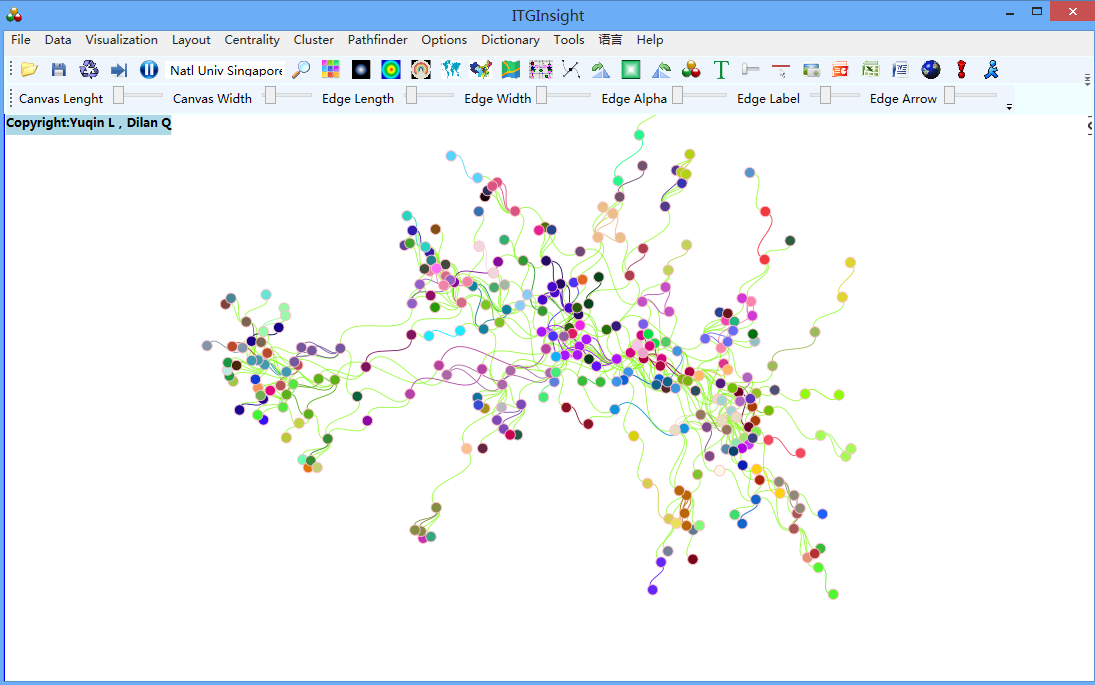
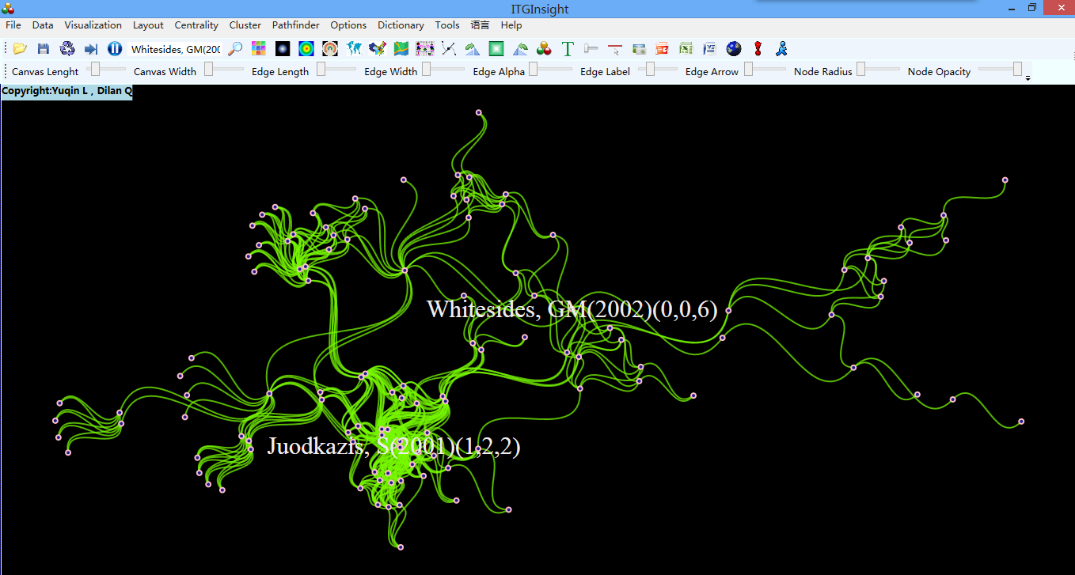
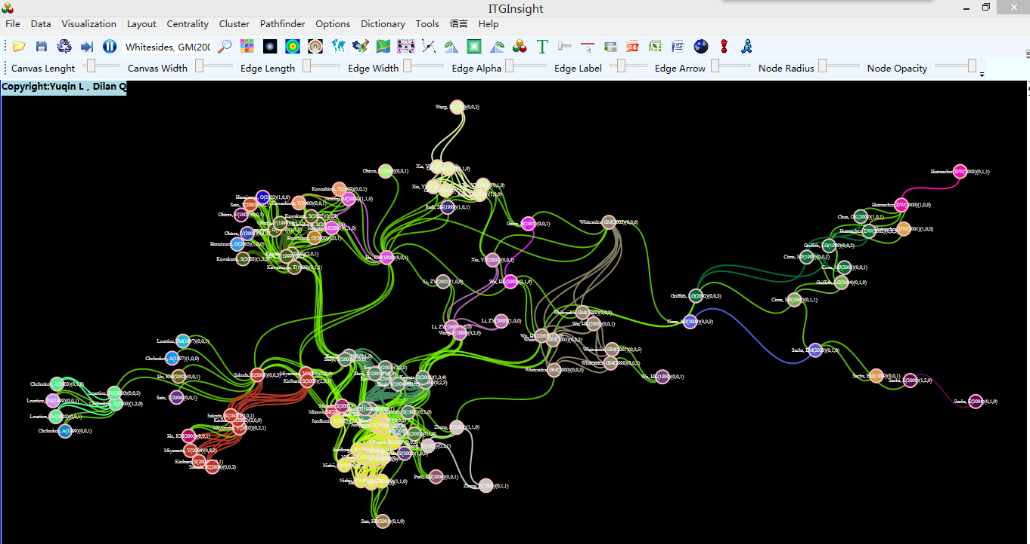
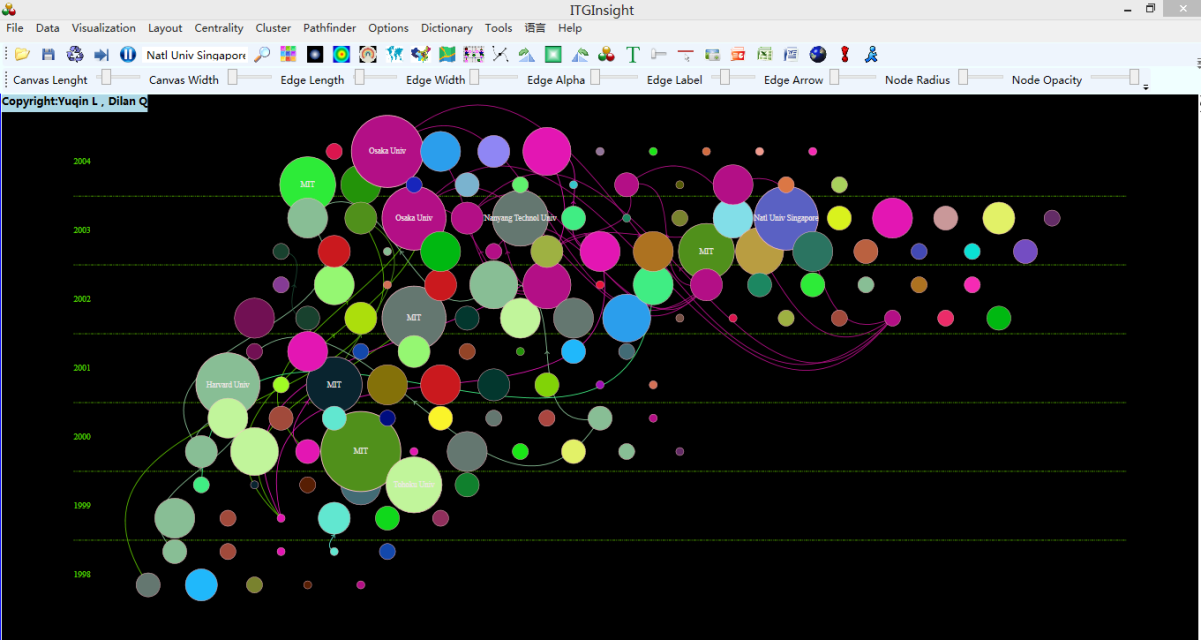
引证关系可视化,除了网络图以外,可以采用时间线进行可视化,点击工具栏的RF布局,后可视化结果如下:
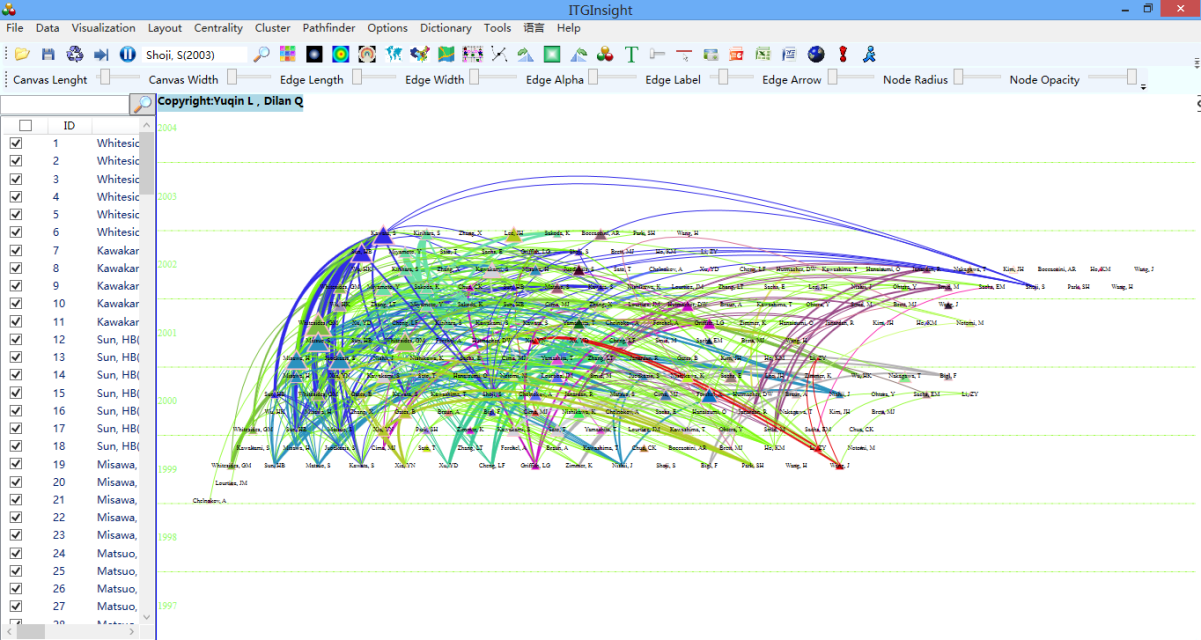
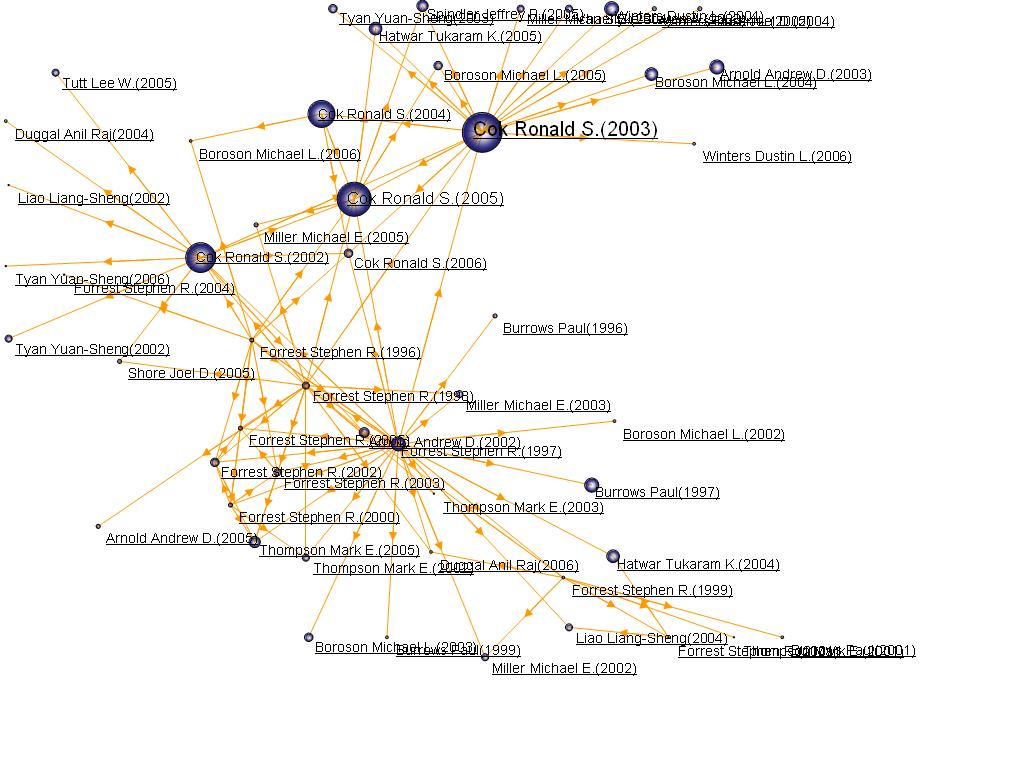
科学技术不断发展与更新迭代,新的科学成果与创新技术不断涌现,与此同时一些旧的领域研究也处于不断演进、融合、分裂等动态变化的过程中。当前科学变革局势较为复杂,科学技术新旧交替、迭代创新的步伐持续不断且呈现加速趋势。在当前背景下,学科主题演化分析成为科技情报研究的一项重要工作。
对于国家来说,主题演化研究能够全面了解学科主题发展的变化及演化脉络,及时跟踪最新研究动向,从而有效制定学科发展策略,主攻科学研究的创新点与突破口。
对于科研管理层,把握学科发展动向能够为科学决策提供支撑,实现科研资源的优化配置和有效利用。
主题演化分析作为新兴趋势探测方法之一,有助于了解领域主题产生、消亡、增强、减弱、聚合和裂变的过程。
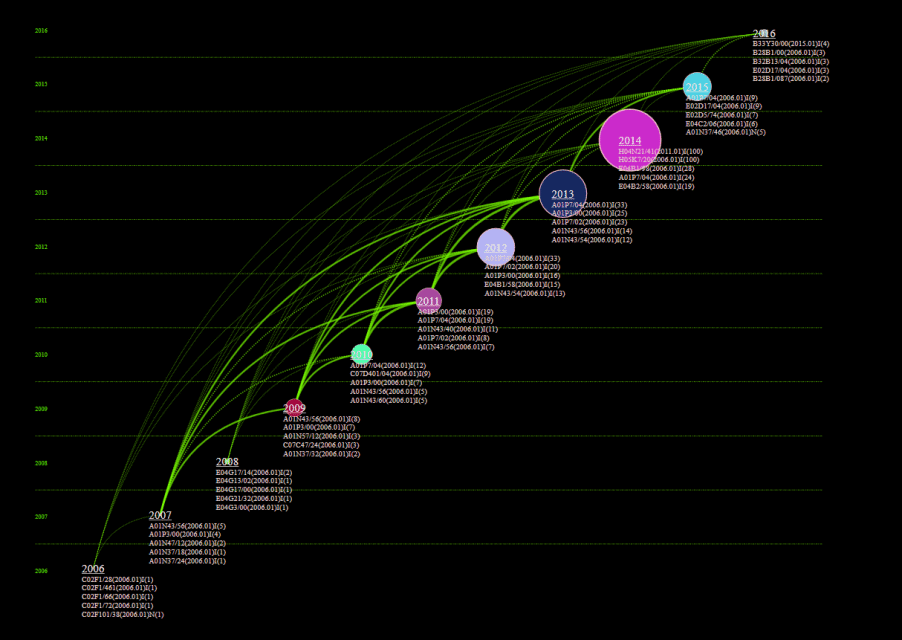
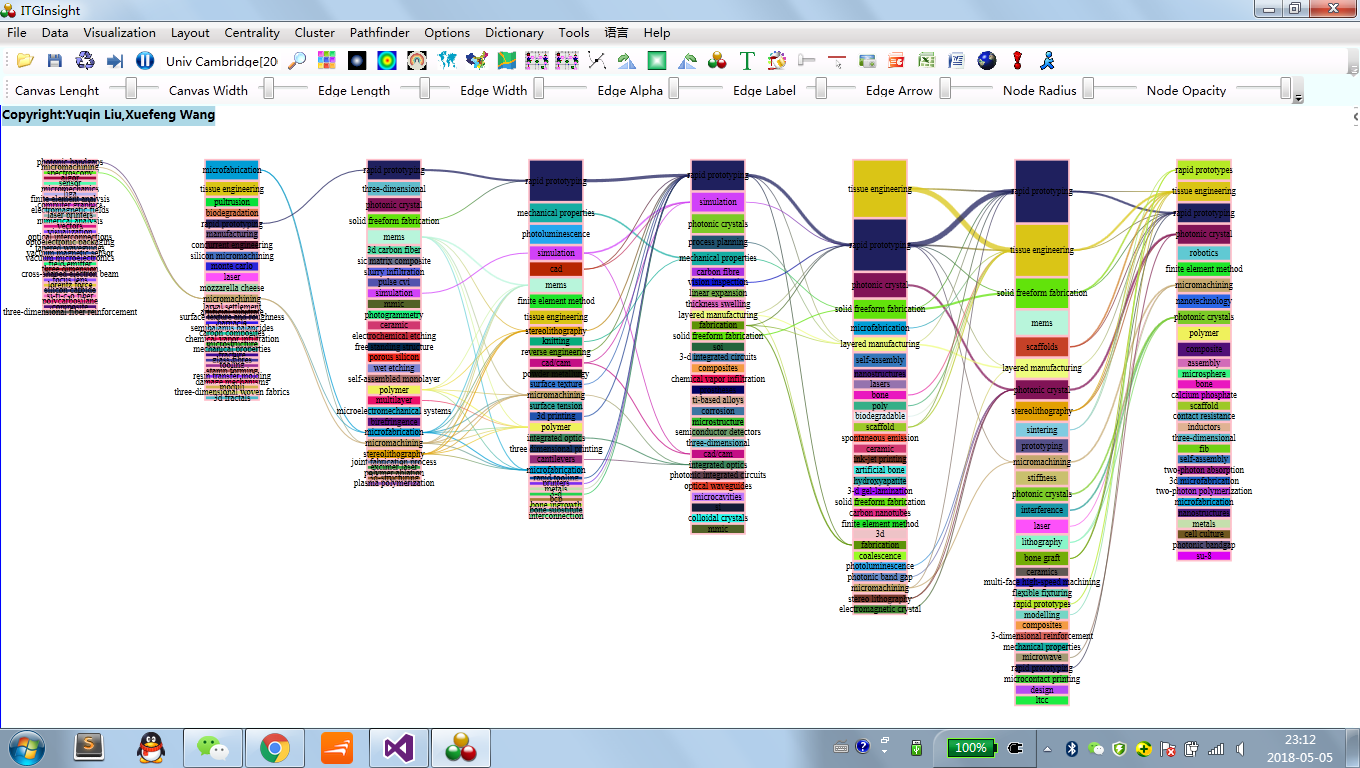
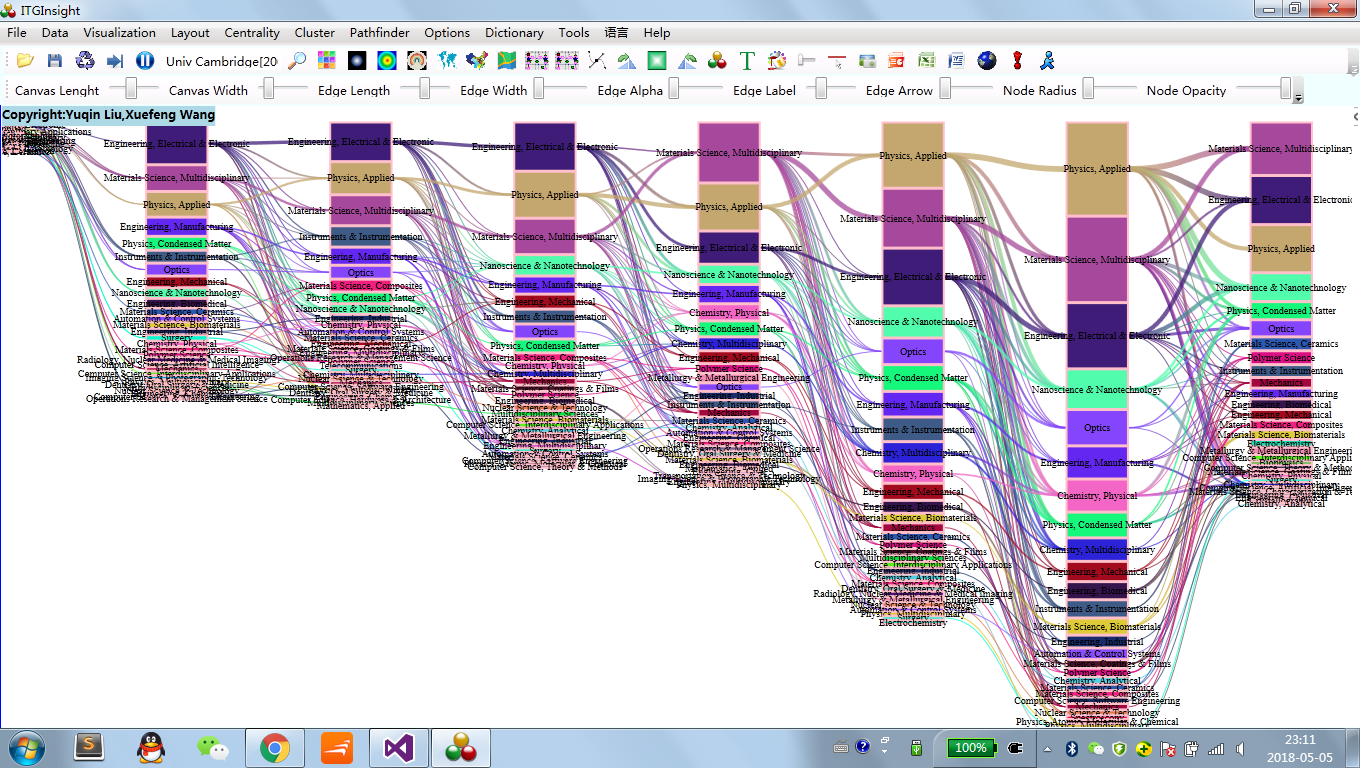
点击菜单栏“Visualization/可视化”——>“Evolution/演化分析”——>“作者演化/机构演化/国家演化/省份演化/出版物演化/类别1演化/类别2演化/类别3演化/类别4演化/关键词演化/主题词演化”,如下图。
可视化区域显示演化图如下:
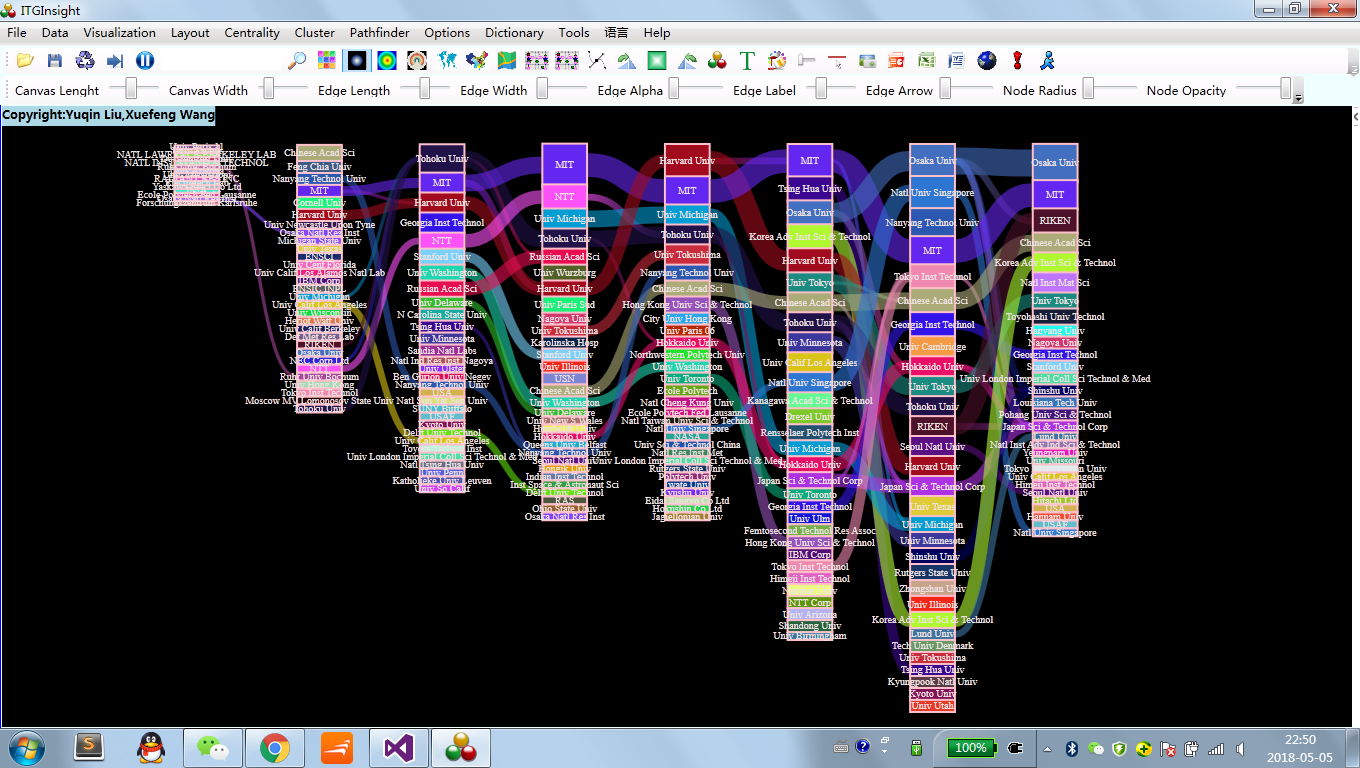
突现词是探测特定时间段内的高频关键词,在某种程度上能够反映该领域内某研究方向的热度以及前沿观点。突现率考察的是词频变化率,考察某段时间内频次变化率高低的标准。
1)点击菜单栏“Visualization/可视化”——>“Breakthrough /突破分析”——>“作者突破/机构突破/国家突破/省份突破/出版物突破/类别1突破/类别2突破/类别3突破/类别4突破/关键词突破/主题词突破”,如下图。
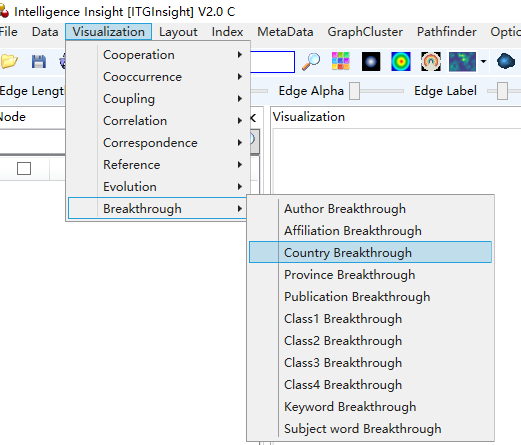
可视化区域显示演化图如下,其中“[]”数值为突破率,红色线条为当年出现与否,宽带可设置为与频数成正比,也可设为相同宽带,默认为相同宽带。
突破分析的基本原理:提取每一年首次出现的主题词或关键词或研究主体,用当年首次出现该主题词或关键词或研究主体的文献数量/当年的文献总数量,为其突破值,突破值在[0,1]之间。首次出现后,之后每年计算出现的频率,用红色线条来显示,线条默认宽度一致,但宽度可调整与其出现频数成比例的样式,通过Graph Render的线条形状来调整。该图默认显示每年突破排序第1的结果,最多可显示每年排序前10的结果,通过Slider面板的Breakthrough来调整,调整方式分别如下图。
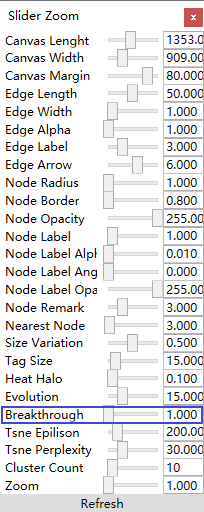
3.11 网络布局算法/选择合适的网络布局算法使网络图尽可能美观
在3.3-3.9的分析步骤中,均涉及到布局算法的选择,默认情况下,布局算法针对整个可视化区域的网络图进行计算;如果希望算法仅对网络图某一局部内的网络节点有效,右键按住ctrl,同时鼠标左键按下、移动,选择局部网络节点,这时对网络图的操作进行对被选中的局部有效。这种操作方式可以使同一网络图不同部分采用不同的布局算法,以便整体网络图更加清晰、可阅读。取消局部选择,放开ctrl键,任意点击鼠标左键即可。
在各种布局算法中,LL(LinLog)\VS(VosMapping)布局算法与其它算法的不同之处在于,通过这两种算法布局节点,节点距离与节点之间的关系数量或强度成反比,也就是说距离具有实际意义。
建议用户使用LL(LinLog Layout),该算法满足绝大数的网络布局,其次采用FR(Frucherman Reingold Layout)布局(特别适用于引证网络),再次采用SP(Spring Layout)布局(特别适用于合著网络)。高级布局建议采用子图布局方法,几个布局算法进行叠加。参考视频https://www.bilibili.com/video/BV1qW4y1v7HB/
在关联关系分析过程中,可以通过路径压缩技术对网络图的关键信息进行过滤,也就是删除不重要的连接线,保留相对重要的连接线。具体操作,点击工具栏的PathFinder/压缩,如下图:
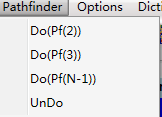
Pf(2)、Pf(3)、Pf(N-1)三种压缩操作,压缩强度逐渐增加。如果取消压缩按Undo/撤销按钮。如果连续两次压缩,撤销仅能恢复最后一次的压缩操作。
图形区默认图形效果如下:
点击工具栏上
![]()
,或菜单栏“Options/选项”——>“Graph Render/图形渲染”,弹出图形渲染设置工具栏或面板如下图:


点击图形样式面板上的
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
,切换节点的显示样式,如下图所示。

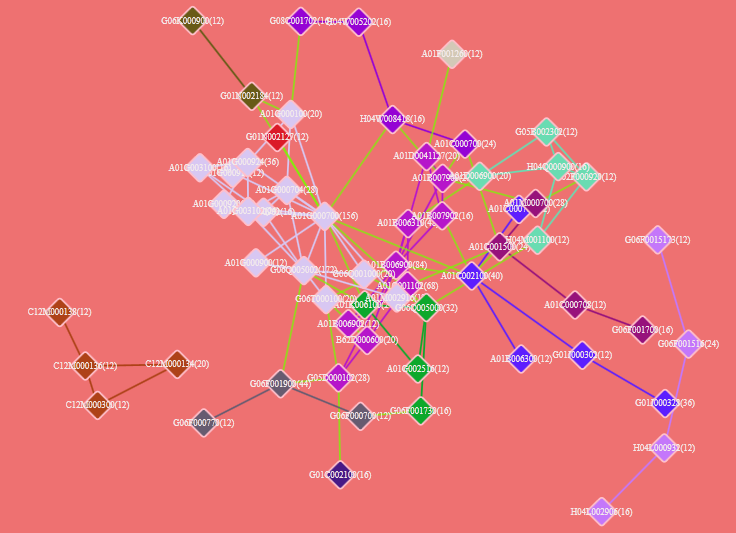
单击图形面板中的
![]()
,表示所有节点大小一致,在各种分析中均可使用。再次单击表示所有节点大小不一致,与节点所代表的数量成比例。
单击图形面板中的
![]()
,表示用两种颜色区分被选中过节点(一个或多个) 和未被选中的节点,选中的方式为鼠标单击,点击之后,再次点击图形节点,被点击过的节 点会变成绿色(一个或多个)。最后一个被点击节点颜色始终为红色(一个)。
软件左侧选中部分节点后,右键点击shape,如下截图:
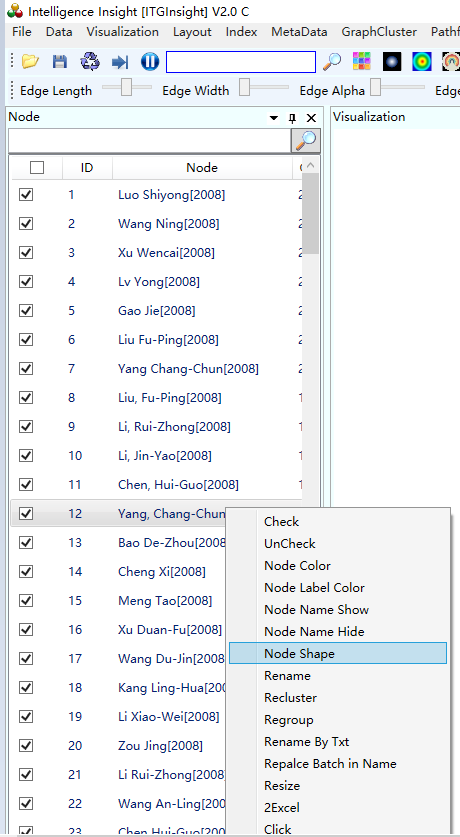
即可对部分节点的形状进行修改;也可以在图形区,用鼠标+ctrl键,选中多个节点进行节点形状的修改,如下图。
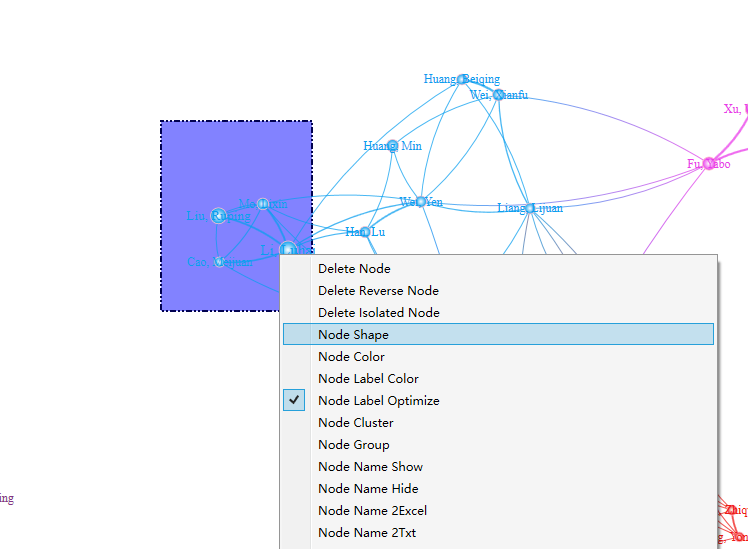
在上一操作中双击样式面板中的样式选项,弹出颜色对话框,选择不同的颜色,图形区域中的节点颜色将随之改变。
也可以在主页面左侧的节点内容面板中进行操作,先左键选择一个或多个节点,然后右键点击color,如下图,进行节点颜色的个性化设置。
也可以在图形中去用鼠标+shift键,一次选择多个节点进行颜色修改。
点击工具栏的
![]()
,弹出节点着色选项,如下:
分别表示按节点之间的关系强度、节点分组、节点名称、节点形状、节点大小对节点染色,单机选中即可。
点击样式面板
![]()
,切换节点边框显示与否,双击则更改节点边框颜色。
单击图形样式面板中的
![]()
,表示所有节点连线宽度一致,在各种分析中均可使用。再次单击表示所有节点连线宽度不一致,带有数量比较,在合著关系分析、同现关系分析时使用,表示数量,在关联关系分析时使用表示关系的强度。
![]()
表示连线的两个节点有初始结束关系,在引证关系分析时使用。单击图形样式面板中的
![]()
表示在连线上注明连接的数量,再次单击隐藏数量,在各种关系分析中均可使用。
![]()
表示连线为直线或是曲线,连续点击会在直线和曲线之间进行切换,切换单曲线时,会有多种曲线风格,如下。
单击图形面板中的
![]()
,表示被选中节点所拥有的连线颜色是否与其它连线进行区别,默认为区别,第一次单击不区别显示,第二次单击区别显示,第三次单击区别显示,并且与被选节点间相连的连线也进行区别显示。
如果边是统一的单一颜色,那么在上一操作中双击样式面板中的样式选项,弹出颜色对话框,选择不同的颜色,图形区域中的连线颜色将随之改变。
如果边是统一的单一颜色,双击
![]()
更改边的文字颜色。
当连线颜色为渐变色时,修改边的颜色需要先选中边,然后点击右键修改边的文字颜色。选择边的三种方法:1)按住ctrl+鼠标左键单击2)按住ctrl+鼠标左键拖拽形成子图3)在可视化区域远离节点的任意位置,右键点击修改边的颜色,这种修改所有边的文字颜色。
系统提供三种显示节点注释的模式:1、鼠标点击节点,显示被点击节点的注释;2、显示所有节点的注释;3、所有节点注释均不显示。
通过点击
![]()
或
![]()
进行三种模式的切换,默认条件下为第1种模式。
![]()
与
![]()
的区别在于节点注释的字体大小是否按照节点所表示的数量进行比例化处理,其效果如下。


当点击
![]()
时,节点文字如果具有时间信息,则节点文字在显示节点文字信息与否之间进行切换。
点击
![]()
节点文字按照如下顺序进行切换显示:1)不显示;2)显示论文数量;3)显示第一二三作者论文数量;4)显示Doi关系计算Reference字段引文数量;5)显示Doi计算Referenced的被引用数量;6)同时显示4和5;7)显示Number1的数量,如论文被引用数量,专利同族数量
除了一般情况下显示节点名称的注释方式外,系统还提供了2种备选方式:显示节点数量,显示节点的备注。如下图。


其中数量表示该节点所代表的数量,文字分别代表节点的名称和备注信息。通过单击图形样式面板中的
![]()
![]()
进行切换。
在上一操作中双击样式面板中的样式选项,弹出颜色对话框,选择不同的颜色,图形区域中的连线颜色将随之改变。
点击工具栏上的
![]()
,弹出节点字体设置窗体,如下图,可对节点文字的字体进行设置。
在节点列表区域选中节点,鼠标右键切换节点文字大小写,如下图。
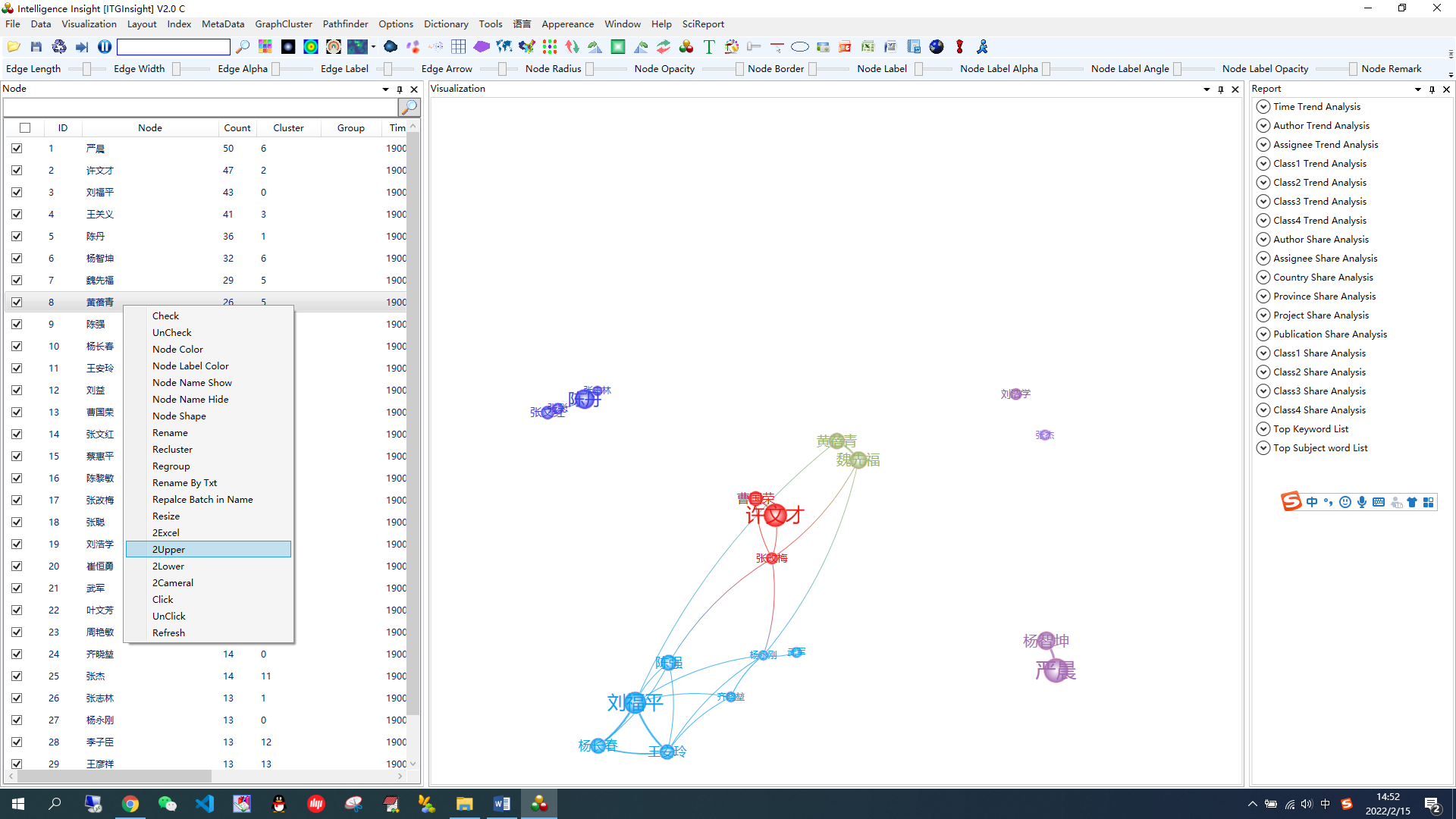
主页面左侧的节点内容面板中进行操作,先左键选择一个或多个节点,然后右键点击Rename(更改节点名称)或者Rename By Txt(通过ID对应Txt文本中每一行,进行节点名称的批量修改)或者Replace Batch In Name(批量替换节点名称里的某些文字,如空格等)进行节点名称修改,如下图,进行节点名称的个性化设置。
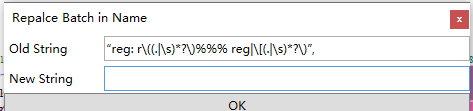
Replace Batch In Name批量替换支持一次替换多个词,用%%%进行分割,同时支持正则表达式替换,例如希望批量删除节点名称里“()”和“[]”中的内容,可以输入“reg: \((.|\s)*?\)%%% reg|\[(.|\s)*?\)”,替换后的字符串为空
点击样式面板
![]()
,使节点文字的位置显示在节点中央或者节点右侧,多次点击,则在以上两种情况下进行切换。
在可视化区域右键点击 Node Label Optimize,如下图,节点标签根据算法进行选择,隐藏部分节点文字。
在节点内容面板右键点击Resize/更改节点大小,如下图:

指定节点大小文件,一般为txt文件,参考example\txt目录下的nodesize.txt,第一列为节点id,第二列为更改后的节点大小,如果可视化区域的节点id与txt文件中的第一列id相等,节点大小更改。
当节点按照大小进行显示时,通过滑块设置的Size Variation进行节点大小对比度调整,如下图。例如一个节点数量为1,一个节点数量为10000,为了节点大小看起来均衡,设置此参数。
在可视化区域点击鼠标右键,点击“聚类颜色/Cluster Color,弹出类别颜色调整面板,如下图。选择对应的类别颜色进行修改,修改后的颜色存储在软件目录下colors/clustercolors.txt文件中,之后再使用聚类,类别颜色将按照新的设置进行显示。
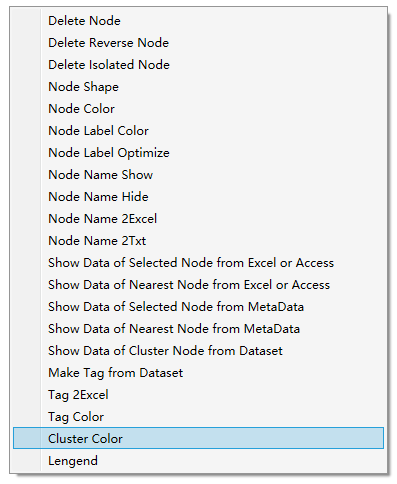

1)点击工具栏上的
![]()
,或菜单栏的“Options/选项”——>“Slider Zoom/滑块缩放”,弹出滑块设置工具栏目或面板,如下图。

2)通过设置滑块值进行“画布长”、“画布宽”、“边长度”、“边宽度”、“边阀值”、“边标注”、“边箭头”、“节点半径”、“节点边框”、“节点透明度”、“节点标注”、“节点标注阈值”、“节点标注角度”、“节点标注透明度”、“节点备注”、“最近N个节点”、“标签大小”、“热力光圈”、“演化分析”、“图形缩放”的大小、长短、多少、比例设置、突破数量等。
通过滑块设置可以对图形进行缩放;通过鼠标拖动可以对优化过程中的图形节点进行位置的移动;通过鼠标拖动并按下shift键,可以实现图形的移动;通过鼠标滑轮+“左或右箭头”实现图形的横向拉伸;通过鼠标滚轮+“上或下箭头”实现图形上下拉伸。
通过工具栏
![]()
![]()
实现图形顺时针或逆时针旋转。
通过工具栏
![]()
![]()
实现图形的上下或左右翻转。
系统默认提供中英文操作,点击菜单栏上的Lans/语言,进行语言选择,每次更改后,下一次启动将以更改后的语言进行启动,如下图:
如果希望用日文、韩文或其它任意语言进行操作,与开发者进行联系,我们将提供任何语言的软件版本。通过上面“其它”进行非中英文语言的设置。
点击工具栏上的
![]()
,弹出颜色对话框,选择颜色进行图形区域背景色的设置。如果想在黑白两种颜色间快速切换背景色,点击工具栏上的
![]()
按钮即可。单击工具栏上的
![]()
,背景显示网格,再次单击,背景不显示网格;双击则弹出颜色对话框,选择颜色,确定网格的颜色。
在工具栏的
![]()
中输入要查找的节点名称,点击
![]()
,图形显示区域将突出显示被查找节点的名称。
主页面左侧显示可视化图形节点的名称、数量、聚类结果、节点的连接边数量等信息。可以通过
![]()
控制节点的显示与否。如果希望对多个节点同时进行显示与否控制,按住shift键,在屏幕左侧依次点击节点的名称,然后右键点击。
右键点击弹出菜单如下:
通过check/uncheck批量控制节点显示与否。在此需要注意,当去除某个节点后,又要恢复这个节点显示,这个过程不能更换布局算法。
如果需要删除图形中没有连接线的节点,在图形区域右键点击
![]()
即可。
也可以在图形区域,按住Ctrl键的同时用鼠标选择一个区域,然后针对这个区域内的节点进行删除,或针对这个区域外的节点进行删除。分别点击
![]()
和
![]()
即可。
(1)点击菜单栏的Index/指标->Density/密度,计算网络密度,如下图。
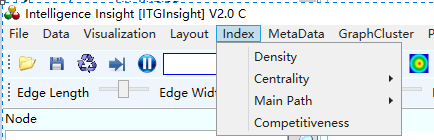
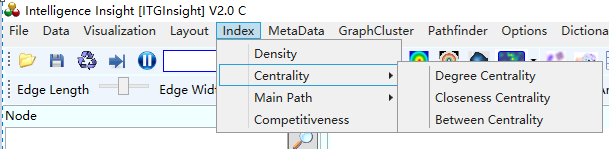
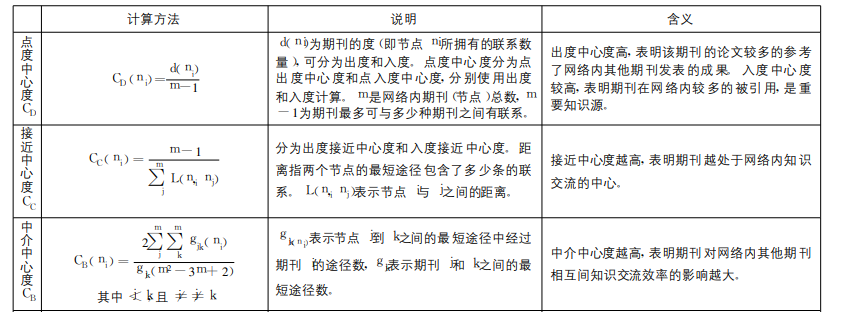
(2)点击菜单栏的Index/指标->Centrality/中心度,分别计算网络图中节点的点度中心度、接近中心度和中介中心度,操作如下图。相关中心度的概念和应用官网学术论文“网络中心度用于期刊引文评价的有效性研究”。
计算结果显示在软件左侧的节点明细,如下图。
(3) 点击菜单栏的Index/指标->Main Path/主路径,分别计算网络图中节点的SPC值,操作如下图。主路径概念和应用官网学术论文“专利引用网络主路径方法研究述评与展望_张娴”。计算结果查看方法与中心度查看方法一致。
(4)技术竞争力计算相对复杂,对网络图进行聚类后,可进行竞争力计算,基本操作:点击菜单栏的Index/指标->Competiveness/竞争力,技术竞争力指标,操作如下图。
计算完成后结果将输入到Txt文件中。详细的操作过程参见官网视频教程——竞争力计算。
网络密度含义如下:

中心度含义如下:
点击工具栏上的
![]()
,先后弹出截图设置和图形文件保存对话框,按提示保存分析的图形,如下图。
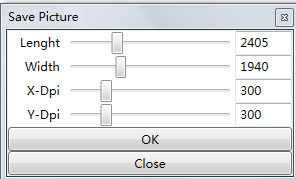
上图提示截图的大小和分辨率,xdpi与ydpi越大,图像越清晰,大小越大,默认值300可满足打印需求。设置后,继续按下图保存截图后的文件。

打开一个itgn文件后,直接点击工具栏上的
![]()
,系统会输出各种统计数据,输出内容与输出的word报表内容相同,同时增加了报表目录到第一个sheet中。
打开一个mode文件,或者打开itgn文件进行合著、同现、关联、引证分析,有图形在图形区显示后,直接点击工具栏上的
![]()
,系统将把图形中的节点数据打印到微软Excel表格中,效果图如下。
此功能需安装微软的office 2007或以上的版本。如果未安装office,点击

,直接存储excel结果即可。
默认情况下,系统的Excel报表仅仅输出趋势、份额等一维统计报表,如果希望输出更多内容,可在“Options/选项”——>“Excel Table/报表输出”中进行更细致的设置,如下图。


输出内容越多,打印报表时间越长,并且保证在3.1进行数据转换时,生成的itgn文件进行了有关的分析。以SCI论文为例,全部分析报表多达130个,此时建议采用EXCEL输出。
ItgInsight提供计算机自动写报告功能,首先打开一个itgn文件,点击工具栏上的
![]()
,弹出智能报告对话框如下。
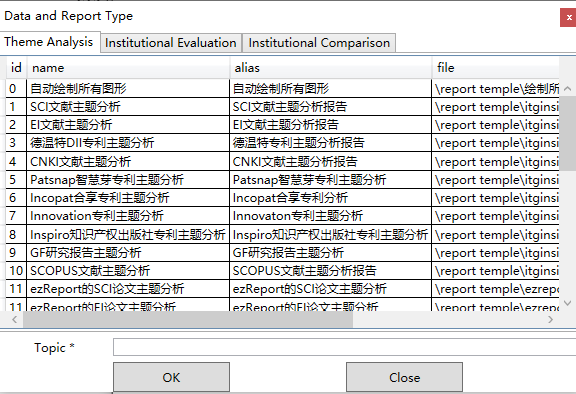
选中一个适合的报告模板,在topic/主题部分填写技术领域,点击确定,软件自动输出相对完整的报告,根据提示对报告做适当修改。
注释:系统针对企业版顶级用户提供默认的两个报告模板,普通用户无法使用该功能。如果想针对其他数据源或者其他报告的模式,ItgInsight提供更多的模板,需要技术服务费。
点击工具栏上的
![]()
,系统将把图形直接在微软Power Point上打印出来,效果图如下:

此功能需安装微软Office 2007或以上的版本。
每次分析,为了保存当前的分析结果,点击工具栏上的
![]()
,或菜单栏的“File/文件”——>“Save/保存”,将当前分析结果保存为*.mod格式文件。在下次使用时,只要点击工具栏上的
![]()
,或菜单栏的“File/文件”——>“Open/打开”,导航到*.mod文件进行打开即可。Mod文件保存内容包含三方面:1、节点位置信息,2、图形样式信息(颜色、阈值、大小、长短、粗细等相关设置等),3、节点内容信息(节点文字,备注、数量、时间等)。
3.27 打开保存layout位置信息文件(位置信息的重复利用)
每次分析,为了保存当前的分析结果中的位置信息,即mod文件中的第一类信息,使得相同名称的节点位置不变,点击工具栏上的
![]()
,或菜单栏的“File/文件”——>“Save/保存”,将当前分析结果保存为*.layout文件。在下次使用时,只要点击工具栏上的
![]()
,或菜单栏的“File/文件”——>“Open/打开”,导航到*.layout文件,即可使相同名称的节点位置不变。
3.28 打开保存graph style样式信息文件(样式信息的重复利用)
每次分析,为了保存当前的调整后的样式信息,即mod文件中的第二类信息,使得样式能够重复利用,点击工具栏上的
![]()
,或菜单栏的“File/文件”——>“Save/保存”,将当前分析结果保存为*.graphstyle文件。在下次使用时,只要点击工具栏上的
![]()
,或菜单栏的“File/文件”——>“Open/打开”,导航到*.graphstyle文件进行打开即可。
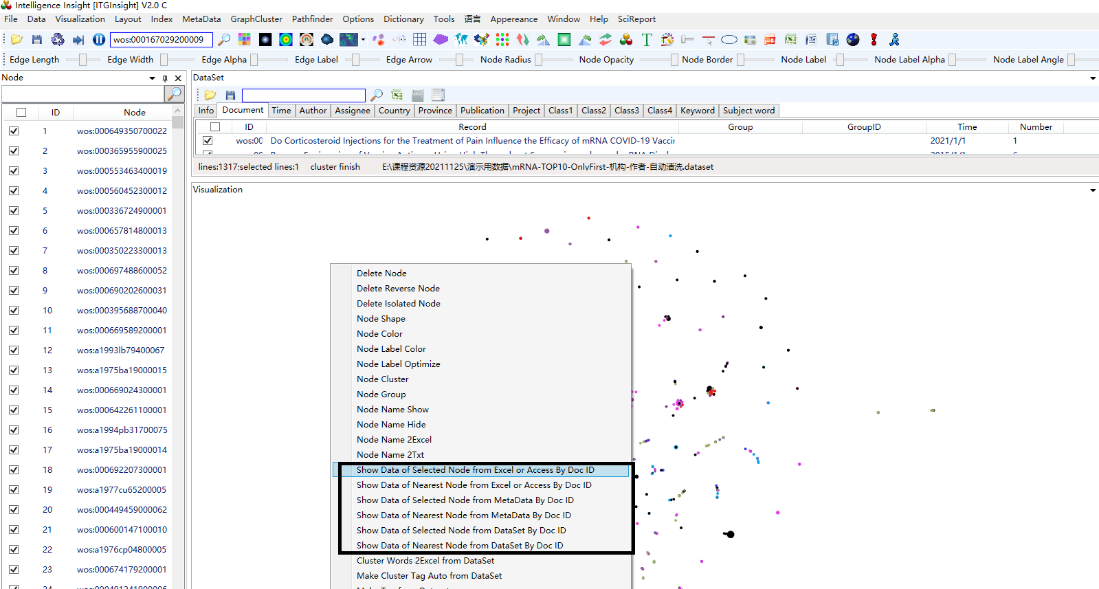
每一张可视化图形一定对应一个原始的数据源,如果这个数据源存储在access或excel中,则可以通过图形与原始数据进行交互,首先指定可视化图形的数据源,点击option/选项下data link/数据连接,如下图:
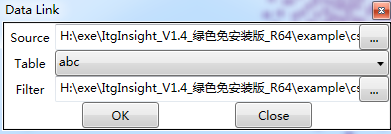
导航到可视化图形所使用的access或excel数据源,并指定应用了数据源中的哪个表,分析时采用的过滤器,设定之后,可以通过图形调取原始数据。
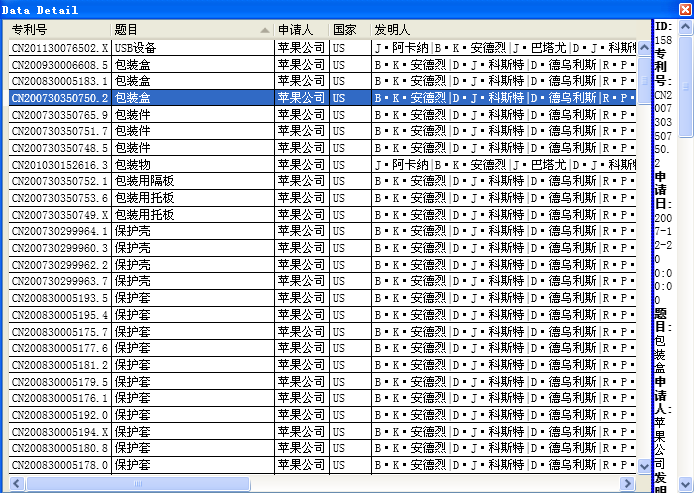
在可视化图形输出中,双击节点或连线弹出可视化元素对应的文献数据列表,如下图。默认情况只会弹出节点对应的文献数据,如果希望弹出连线对应的文献数据,点击工具栏上的进行连线数据的显示。(该功能仅限于access、excel数据文件,对存储在txt中的数据文件不适用)
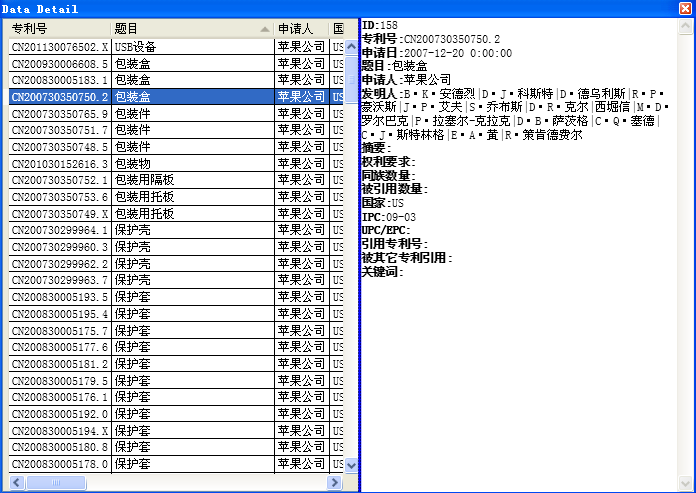
![]()
将鼠标置于蓝色线条处调整显示屏的内容,双击左侧表中任意一行,右侧显示该行的更进一步信息,如下图。
如果图形是采用6.8节聚类分析得到的聚类图,则需要鼠标右键,如下图解中的方式,连接到原始数据。
按如下操作导出坐标,坐标文件格式为tsv格式。
在可视化区域,鼠标右键点击Lengend/图例,图例会导出到PPT中,在PPT中对图例进行修改。
打开*.itgn文件后,点击工具栏DrawingRobot/绘图机器人,软件自动绘制所有图形到Word中,包括各种条形图、线形图、饼图、演化图、聚类图、热力图等,如下是绘制的SCI论文分析图形目录。

同时,Word中所有图形的mod矢量图和png截图都可以在软件report temple目录下找到,用户可以对mod矢量图进行再加工。
软件提供了部分快捷键操作,如下表:
| 快捷键操作 | |
| 功能 | 快捷键 |
| 以矩形的方式选择多个节点作为子图 | 鼠标左键按下+Ctrl键,移动鼠标 |
| 选择边,修改边的颜色,边的文字颜色 | Ctrl键+鼠标左键单击 |
| 选择与某个节点连通的节点作为子图 | Ctrl+Shift键,鼠标左键点击某一个节点 |
| 平移整个图形 | 鼠标左键按下+Shift,移动鼠标 |
| 平移子图 | 选择子图,鼠标左键按下+Shift,移动鼠标 |
| 孤立节点平均分布在页面边缘 | 按键C或c |
| 图形优化开始/暂停 | Enter |
| 平移标签或者演化分析的年代标签 | 鼠标左键按下+Alt,移动鼠标 |
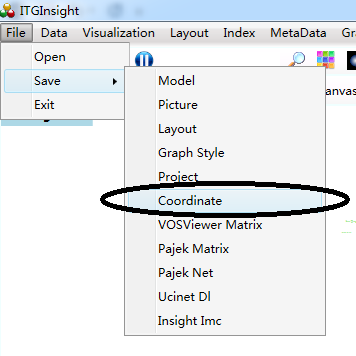
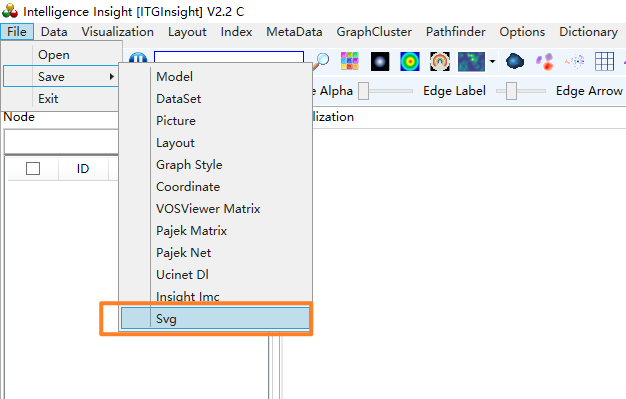
尽管本软件提供了mod格式矢量图,但该格式只能用本软件打开编辑。由于期刊论文多数需要SVG格式矢量图,为此V2.3版本后增加了SVG格式矢量图存储,打开mod文件后,点击菜单栏“Save/保存”——>“Svg/矢量图”保存矢量图格式的图片,如下图。SVG矢量图的优点是图片放大缩小图片质量无变化,可以使用浏览器打开矢量图。SVG矢量图不支持热力图、聚类图、密度图。支持网络图、矩阵图、演化图。
点击工具栏上的
![]()
,或菜单栏的“File/文件”——>“Exit/退出”,系统安全退出。
第四章:聚类分析、热力图/地形图/密度图、世界地图、气象图、矩阵图可视化
在进行合著、同现、耦合、关联、引证分析时,如果按照3.3-3.8的网络图进行显示,可以进一步对网络图进行二次聚类,二次聚类在网络图节点数量较多的情况下,能够更加清晰的表示网络结构。具体操作如下:
1)点击菜单栏“GraphCluster/图聚类” ——>“Vosviewer Algorithm”或“LinLog Algorithm”或“Kmeans(N)”或“Kemans(CalculateSilhouetteCoefficient)”——>“Do/执行”或“UnDo/撤销“对网路进行聚类或取消聚类,如下图。前两种聚类数量由算法确定,不能调整,Kmeans(N)聚类数量默认为5,可通过slider面板进行调整。

Kemans(CalculateSilhouetteCoefficient)根据轮廓系数选择最优聚类数量,但最多聚类数量不超过100。
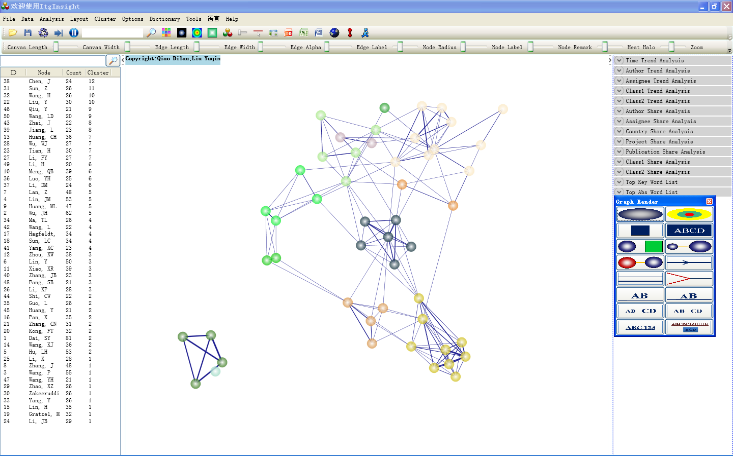
2)在主页面左侧的节点内容面板中查看聚类结果,图形显示区的节点颜色区别节点所属类别,如下图。
点击工具栏的
![]()
按钮,网络聚类图显示模式如下图效果。

点击工具栏的
![]()
按钮,网络聚类图显示模式如下图效果。
系统可视化结果以网络图为主,同时提供热力图/地形图/密度图可视化。热力图是对自然界的热力成像原理的计算机模拟,通过红黄绿蓝四种颜色的深浅来区别数据的大小,颜色块区别数据的密集程度,参考下图。
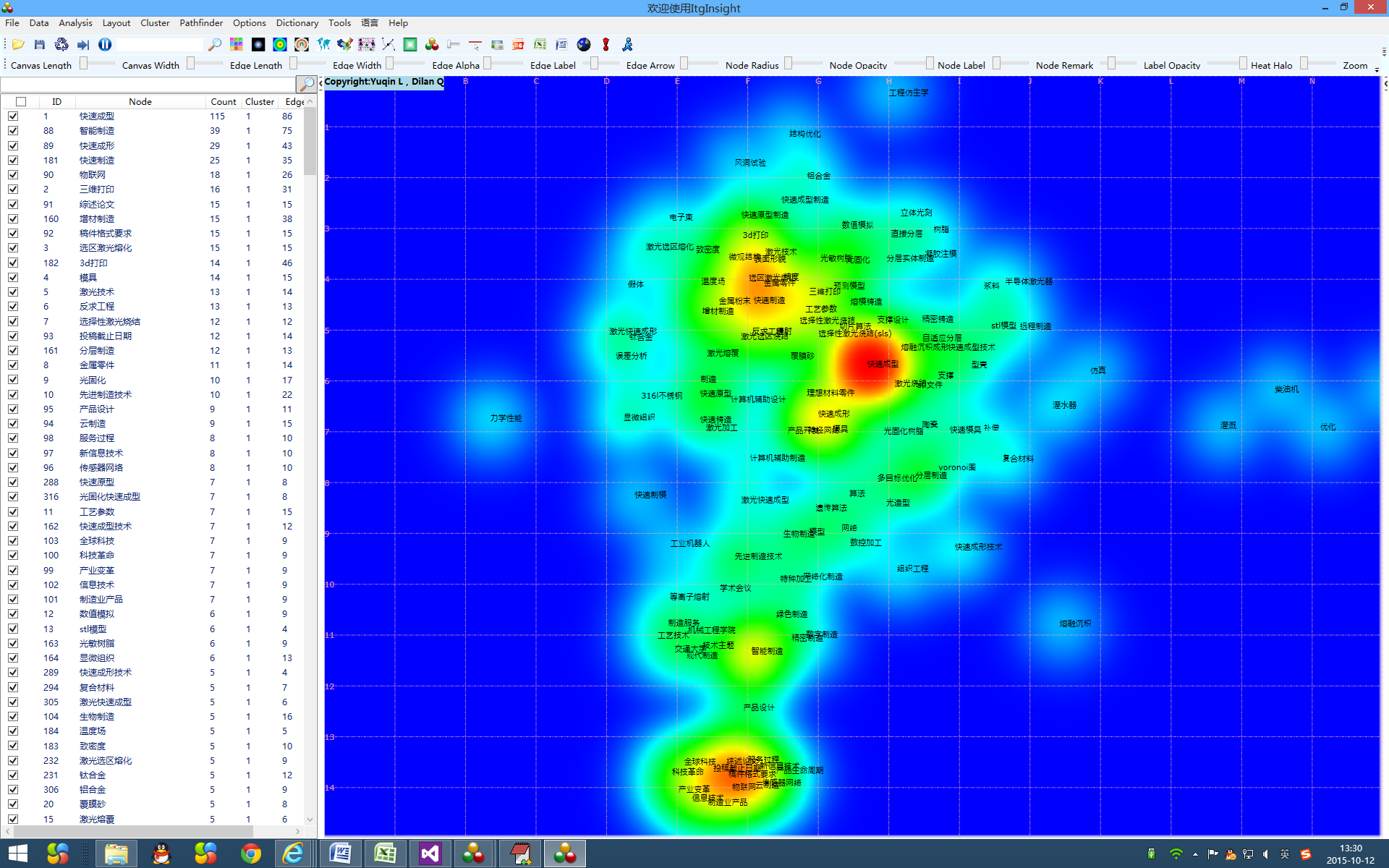
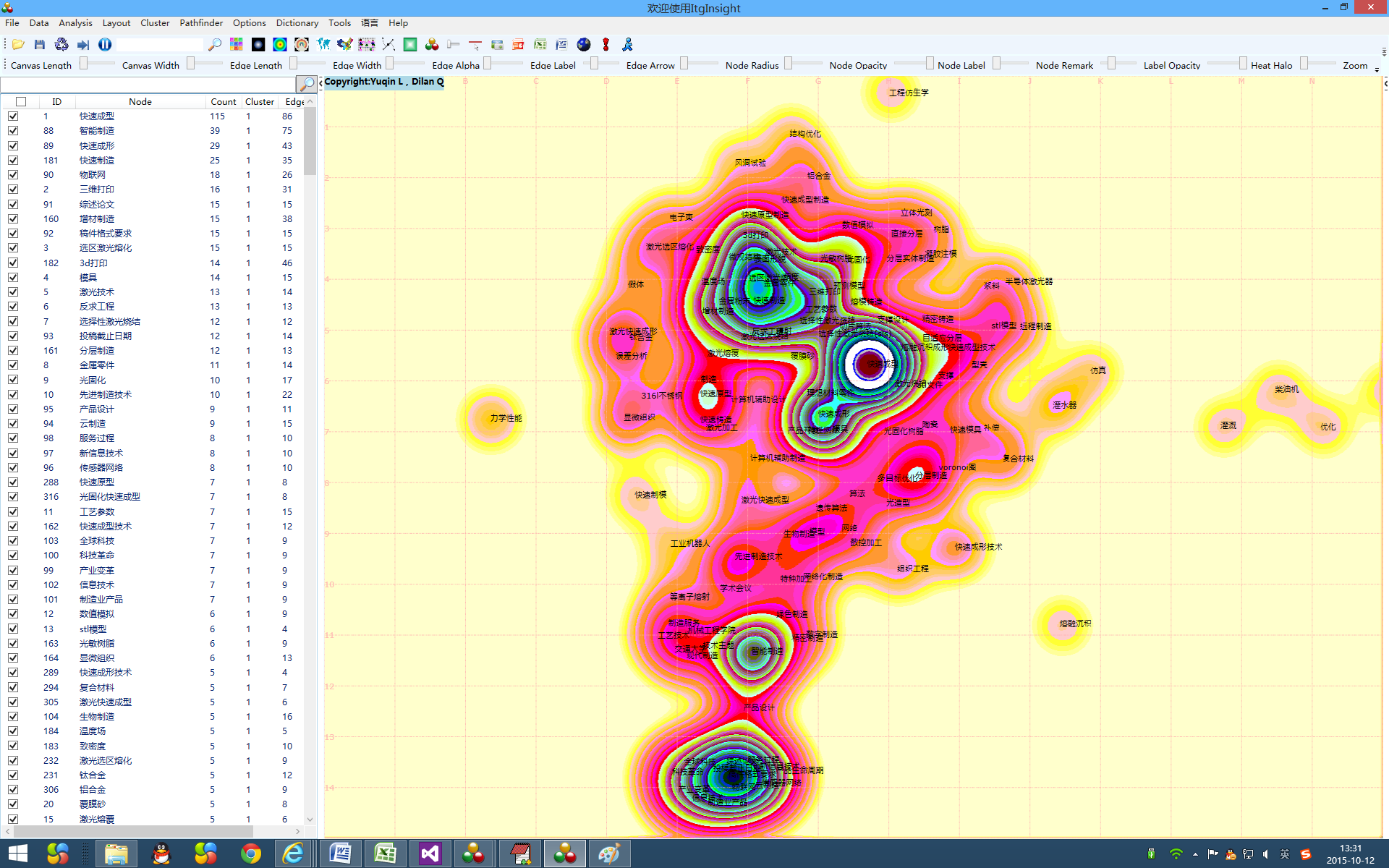
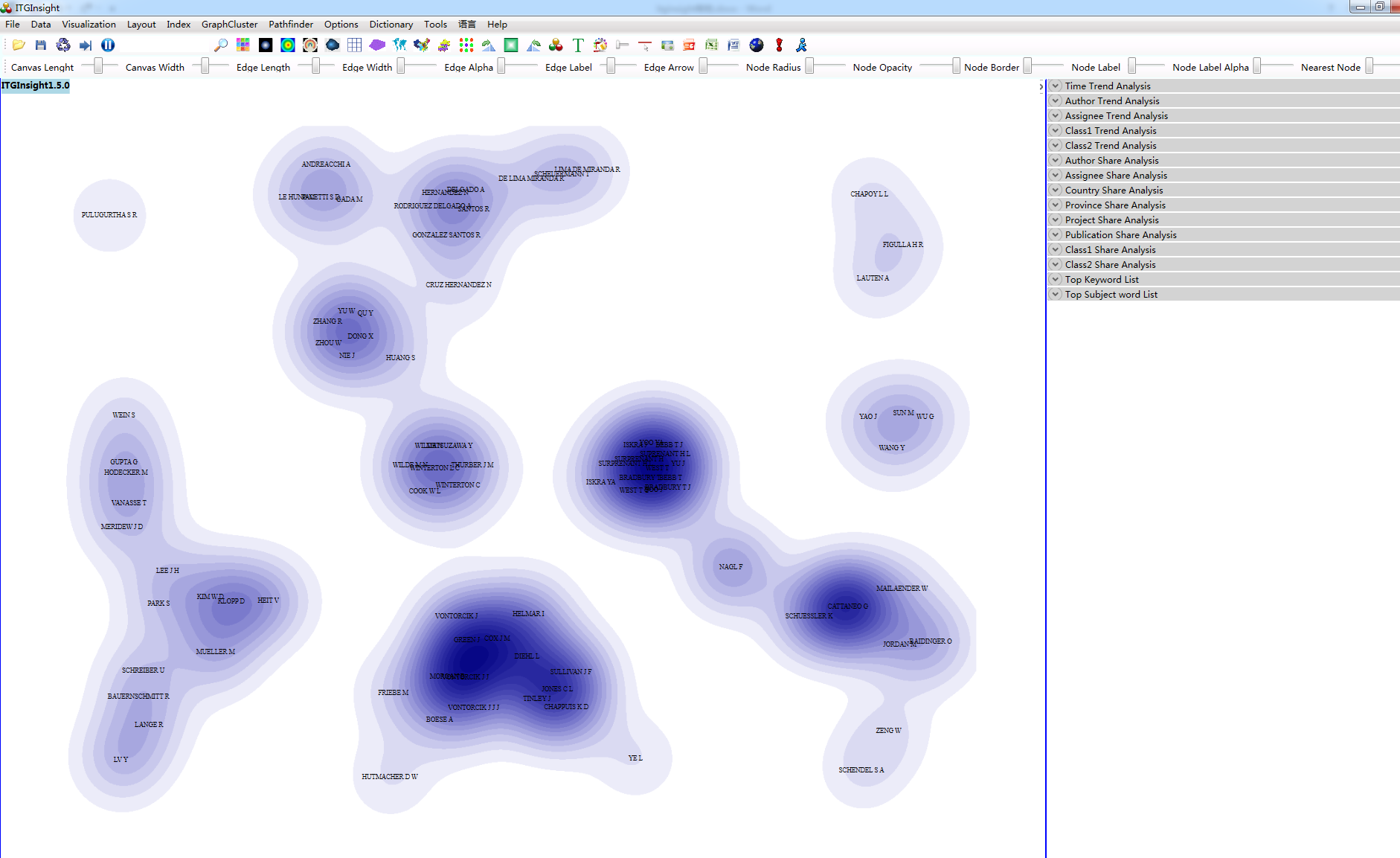
1)点击菜单栏“Layout/布局”——>“VS布局或FS布局”。
2)对经过布局的网络图,再次点击菜单栏的
![]()
或
![]()
或
![]()
按钮,系统提示后台操作状态条,待状态条消失后,图形区即可呈现热力图结果。
3)按照3.9-3.15的操作方法,在热力图/地形图/密度图上进行相关内容的显示控制。
4)V1.6版本以后增加了类似VOSViewer的主题图形式,点击工具栏如下图:
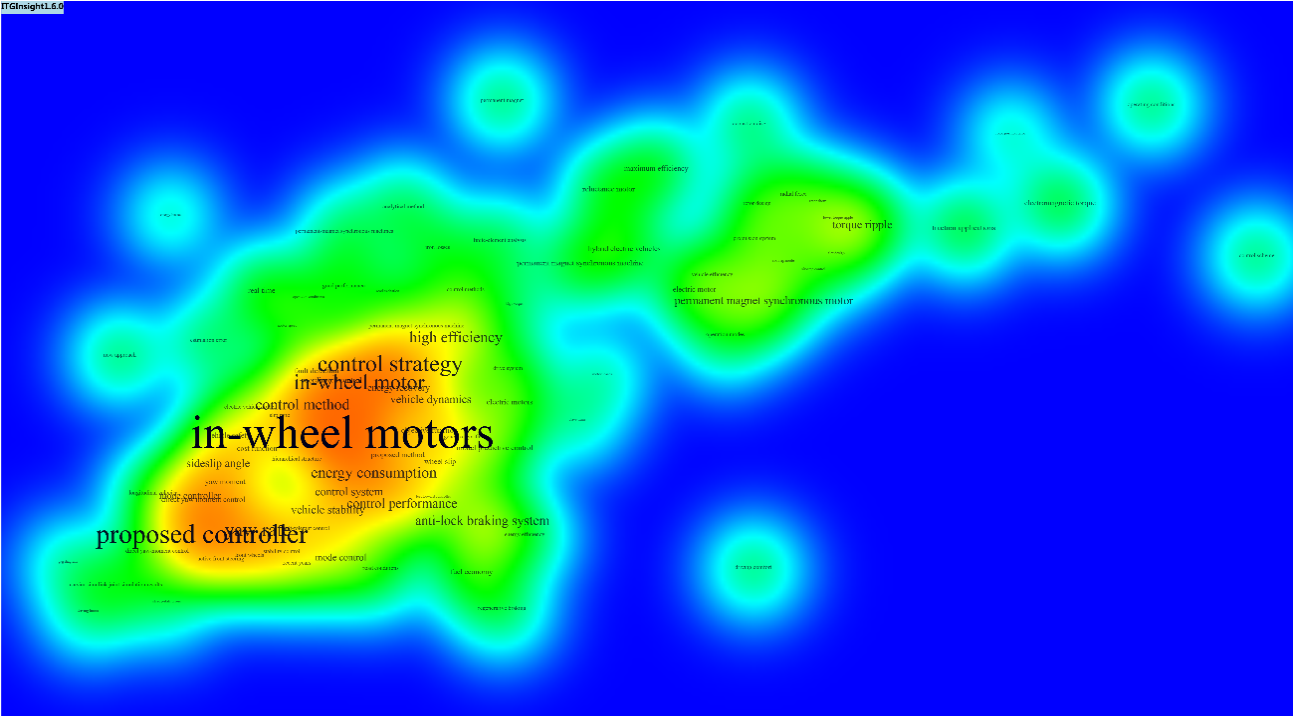
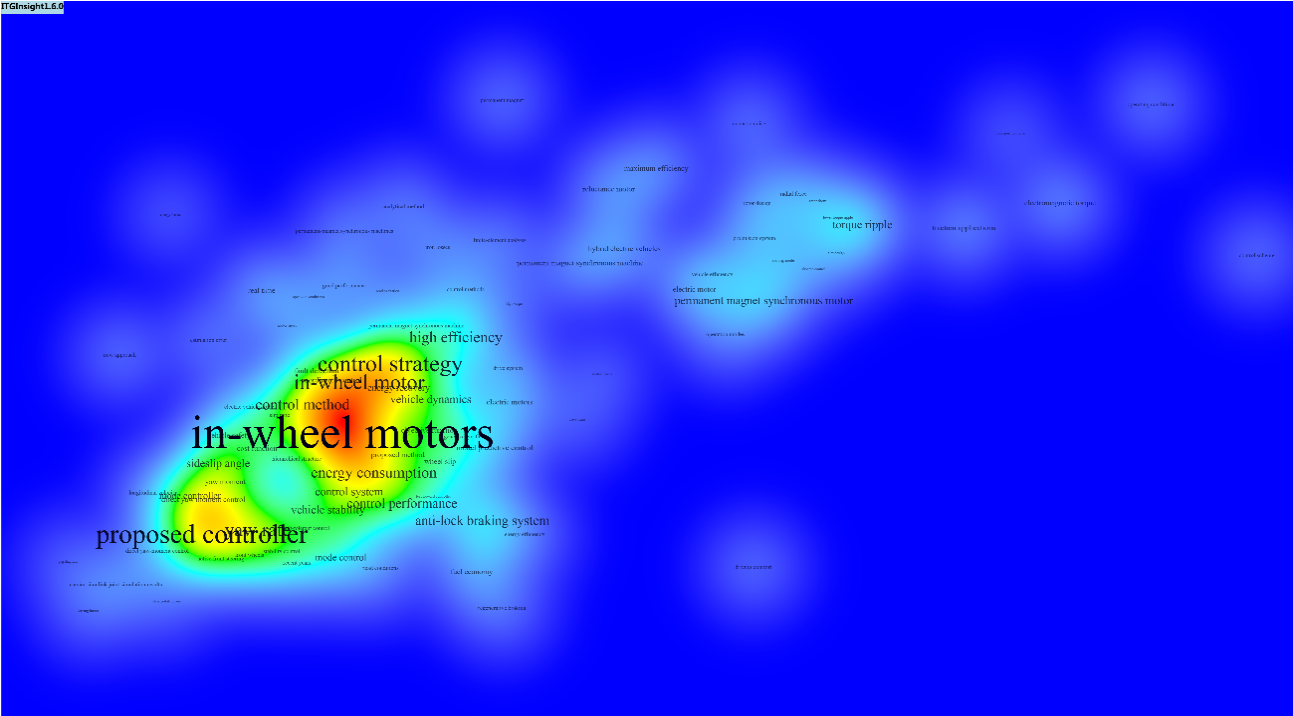
可以修改主题图的样式,也可以通过导入、导出功能自定义主题图的颜色,自定义颜色格式参考可以选择一种颜色模式后,导出,观察颜色格式进行修改。以下为同一张图的不同效果:



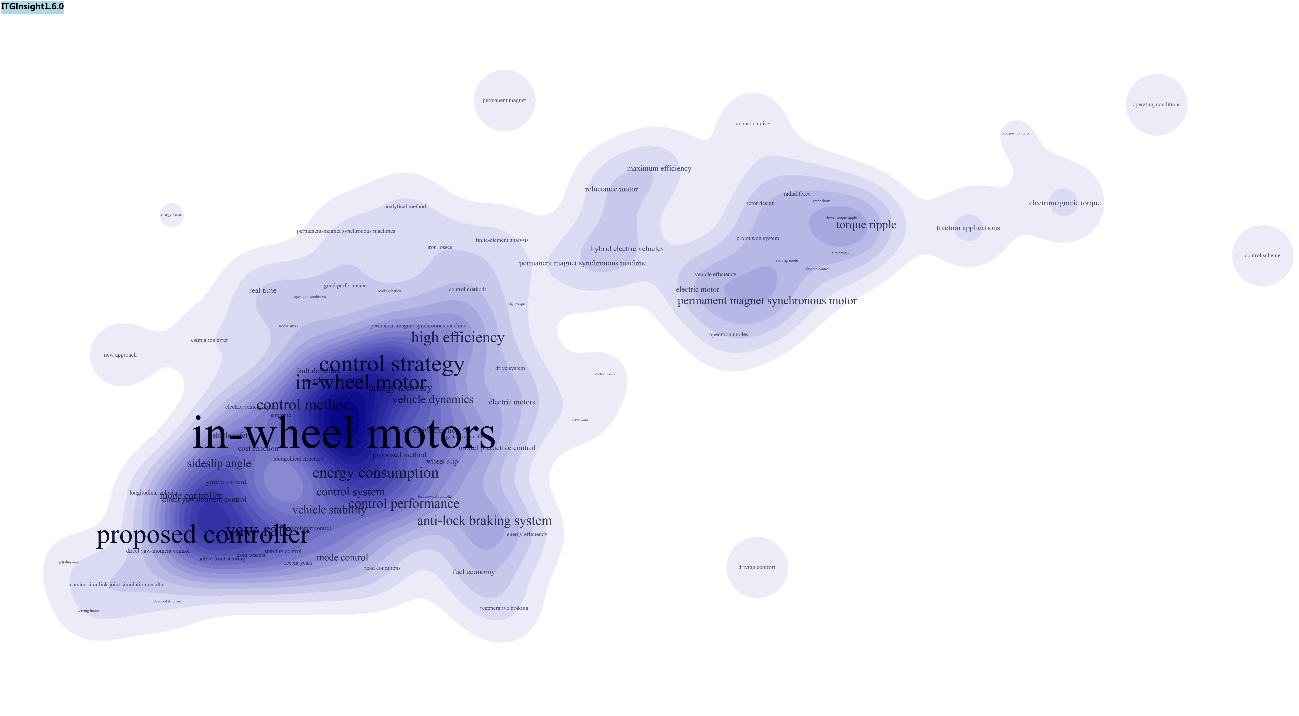
系统提供世界地图可视化。在系统安装目录下的lalo_world.txt文件中(坐标信息可增加、修改,参考文件中已有的坐标格式即可),保存有世界主要国家的经纬度信息,当网络图中的节点名称出现在lalo_world.txt中时,点击工具栏的
![]()
,采用世界地图布局进行可视化输出,也就是每个节点按照地理位置进行坐标确定。
系统提供中国地图可视化。在系统安装目录下的lalo_china.txt文件中(坐标信息可增加、修改,参考文件中已有的坐标格式即可),保存有中国部分省市的经纬度信息,当网络图中的节点名称出现在lalo_china.txt中时,点击工具栏的
![]()
,采用中国地图进行可视化输出,也就是每个节点按照地理位置进行坐标确定。对于中国地图,建议用户仅仅使用节点布局,不要使用背景。
对于以网络图形式输出的可视化样式,通过点击工具栏的
![]()
,使网络图的节点转化为矩阵的行或列,网络图的连接线转化为矩阵行列交叉部分的节点,图形转化为矩阵形式,如下图。其中,鼠标单击行的名称,再次点击
![]()
,行变为列;反之,亦然。对于节点文字、节点文字(仅是数字)的大小、颜色调整,与网络图的操作相同。
注意:网络图能够转化为矩阵图的条件是,网络图中的节点分为两个颜色,即选中状态和非选中状态。可以在软件左侧,选中若干节点,右键点击click,然后再点击矩阵按钮,即可出现矩阵效果,如下图。
ItgInsight分析对象为中英文的专利、论文、报告,并定义过滤器进行分析对象的切换。系统预先设计了经常分析的SCI、CNKI论文,德温特专利、各国专利数据的过滤器,以下两幅图均为分析由Web Of Science下载的SCI数据所使用的过滤器。


其中<FileMap></FileMap>节点下的<ID><Abstract>….<Title>分别用来设置access(excel或txt)数据库中的对应字段名,只要设置这些节点对应的专利、报告、论文所存储的数据对应字段即可。
<Source>数据来源,可以是wos,cnki,或者任意其它来源default;
<ID>对应唯一标准字段;
<Abstract>对应摘要字段;可对应多个字段;
<Authors>对应作者字段;
<AuthorsCorres>对应通信作者字段,该字段可选,如上图第一幅截图;
<Affiliation>对应机构字段;
<AffiliationCorres>对应通信机构字段,该字段可选,如上图第一幅截图;
<Class1>对应类别字段;
<Class2>对应类别字段;
<Class3>对应类别字段;
<Class4>对应类别字段;
<Keyword>对应关键词字段,对应多个字段;
<Countries>对应国家/地区字段;
<CountriesCorres>对应通信/国家地区字段,该字段可选,如上图第一幅截图;
<Publication>对应期刊字段;
<Description>对应正文字段;
<Reference>对应引用文献ID字段
<ReferencedBy>对应被引文献ID字段
<Time>对应时间字段
<Title>对应题目字段
<Number1>对应被引用数量字段
<Number2>
<Number3>
—————–以下均为可选字段,仅个别过滤器有相关字段,主要用于将文献转为参考文献格式—————————–
<Cities></Cities>城市
<PublicationTime>DT</PublicationTime>出版时间
<PublicationType>DT</PublicationType>出版类型
<PublicationArea>CL</PublicationArea>出版地区
<Publisher>PU</Publisher>出版单位
<Volume>VL</Volume>卷
<Period>IS</Period>期
<PageStart>BP</PageStart>开始页码
<PageEnd>EP</PageEnd>结束页码
如果对应字段不存在,对应部分不填写任何内容,如本例中的<Description>节点。
在sysset.xml中<System></System>节点下的内容用来设置与系统或分析有关的参数。
<SoftName>用于更改软件启动后的界面显示名称;
<SoftCopyRight>用于设置软件启动后页面左上角的版权信息;
<VSMwordMax>用于指定进行语义计算时最多采用的词语数量,越多,对系统的硬件要求越高、计算时间越长;
<StopWordFile>用于设定停用词文件路径,默认为stopwords.txt;
<ThesaurusFile>用于设定主题词文件路径,默认为thesaurus.txt;
<DataFile>用于设定被分析数据文件路径;
<CoThreshold>用于指定合著分析的阀值,如果超过该值,才认为进行合著计算,在图形上表示为存在“连线”;
<CoreThreshold>用于指定在关联分析中关联的阀值,如果超过该值,才认为进行关联计算,在图形上表示为存在“连线”;
<OnlyEdgeCoauthor>用于指定在输出作者合著图形时是否只输出带有合著关系的节点;
<OnlyEdgeCoassignee>用于指定在输出机构合著图形时是否只输出带有合著关系的节点;
<OnlyEdgeCocountry>用于指定在输出区域合著图形时是否只输出带有合著关系的节点;
<OnlyEdgeCoclass1>用于指定在输出类别1同现图形时是否只输出带有同现关系的节点;
<OnlyEdgeCoclass2>用于指定在输出类别2同现图形时是否只输出带有同现关系的节点;
<OnlyEdgeCoclass3>用于指定在输出类别3同现图形时是否只输出带有同现关系的节点;
<OnlyEdgeCoclass4>用于指定在输出类别4同现图形时是否只输出带有同现关系的节点;
<OnlyEdgeCoword>用于指定在输出关键词同现图形时是否只输出带有同现关系的节点;
<OnlyEdgeDocumentReference>用于指定在输出文献引证图形时是否只输出带有引证关系的节点;
<OnlyEdgeAuthorReference>用于指定在输出作者引证同现图形时是否只输出带有引证关系的节点;
<OnlyEdgeAssigneeReference>用于指定在输出机构引证图形时是否只输出带有引证关系的节点;
<OnlyEdgePublicationReference>用于指定在输出期刊引证图形时是否只输出带有引证关系的节点;
<OnlyEdgeDocumentCoReference>用于指定在输出文献耦合图形时是否只输出带有耦合关系的节点;
<OnlyEdgeAuthorCoReference>用于指定在输出作者耦合图形时是否只输出带有耦合关系的节点;
<OnlyEdgeAssigneeCoReference>用于指定在输出机构耦合图形时是否只输出带有耦合关系的节点;
<OnlyEdgePublicationCoReference>用于指定在输出出版物耦合图形时是否只输出带有耦合关系的节点;
<OnlyEdgeCountryCoReference>用于指定在输出国家耦合图形时是否只输出带有耦合关系的节点;
<PFNET>用于设定是否由计算机完成网络图的压缩。
也可以通过“Options/选项”——>“System Setting/系统设置”进行有关参数的设置。或者在进行数据转换时指定以上参数的设置。
如果在与摘要词相关的分析中出现了没有意义的词,如“of、 in、on”“的、地、得”等,可以通过设置停用词的方式去掉这些词(系统默认情况下已经去除了大部分停用词)。停用词的设置在系统安装目录下dic/stopwords.txt文件中,每个停用词单独一行。设置后重新启动程序,停用词表才会发挥作用。可通过“Options/选项”——>“System Setting/系统设置”——>“Dictionary/字典”指定停用词文件所在路径,如下图。
或者在进行数据转换时指定使用的停用词文件所在路径。
也可以在“字典/Dictionary”——>“停用词/Stop Words”中进行停用词的添加、删除,如下图。
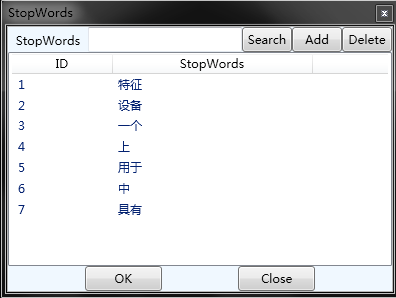
停用词不区分大小写。
如果希望在摘要词的分析中,按照用户指定的词进行词的拆分,这里称为主题词拆分。主题词的设置在系统安装目录下dic/thesaurus.txt文件中,设置格式为:
词A1|词A2|词A3|词A4|词A5|词A6|词A7|词A8——含义为用词A1替换词A2-A8
|词B1|词B2|词B3——含义为词B1、B2、B3为无意义词(类似于停用词)不在统计范围内
其设置后重新启动程序,主题词表才会发挥作用,并且对关键词的分析中同样发挥作用。也可以通过“Options/选项”——>“System Setting/系统设置”——>“Dictionary/字典”指定主题词文件所在路径。也可以在“字典/Dictionary”——>“主题词/Thesaurus”中进行主题词的添加、删除,具体方法和停用词的操作一致。对主题词的使用可设置为“主题词+分词”、“仅用主题词”“仅用分词”“分词+主题词”来设置主题词的使用方式。“分词+主题词”是本软件的推荐使用方案,其优势在于处理的数据量会成倍的增加,而且主题词更有实际意义。主题词表不区分大小写。
为了规范人名书写格式差异带来的统计结果不准确,提供人名词典文件进行人名的修正,存在软件目录dic/persondic.txt中。对于该文件的修改与主题词一致。设置格式相似:
人名A1|人名A2|人名A3——含义为用人名A1替换人名A2-A3
|人名B1|人名B2|人名B3——含义为人名B1、B2、B3为无意义人名不在统计范围内
+|A
+|B
+|C
+|A|B|C 只分析或筛选人名字段中含有A或B或C的数据,其他数据不分析
默认条件下,人名词典不区分大小写,第一行取值:0,不区分大小写,全部按小写处理、-1,不区分大小写,全部按照大写处理、1,区分大小写,按照原文大小写处理、2,第一个字母按照大写,其他按照小些,如果一个单词全部为大写,保留全部大写。
5.6 机构辞典设置
为了规范机构名称书写格式、名称修改、并购合并等带来的统计结果不准确,系统提供机构词典文件进行机构名称的修正,存在软件目录dic/corprationdic.txt中。对于该文件的修改与主题词、人名词典一致。设置格式相似:
机构A1|机构A2|机构A3——含义为用机构A1替换机构A2-A3
|机构B1|机构B2|机构B3——含义为机构B1、B2、B3为无意义机构不在统计范围内
+|A
+|B
+|C
+|A|B|C 只分析或筛选机构字段中含有A或B或C的数据,其他数据不分析
默认条件下,公司词典不区分大小写,第一行取值:0,不区分大小写,全部按小写处理、-1,不区分大小写,全部按照大写处理、1,区分大小写,按照原文大小写处理、2,第一个字母按照大写,其他按照小些,如果一个单词全部为大写,保留全部大写。
为了规范国家名称书写格式带来的统计结果不准确,系统提供国家词典文件进行地名名称的修正,存在软件目录dic/countrydic.txt中。对于该文件的修改与主题词、人名词典一致。设置格式相似:
地名A1|地名A2|地名A3——含义为用地名A1替换地名A2-A3
|地名B1|地名B2|地名B3——含义为地名B1、B2、B3为无意义地名不在统计范围内
+|A
+|B
+|C
+|A|B|C 只分析或筛选国家字段中含有A或B或C的数据,其他数据不分析
默认条件下,国家词典不区分大小写,第一行取值:0,不区分大小写,全部按小写处理、-1,不区分大小写,全部按照大写处理、1,区分大小写,按照原文大小写处理、2,第一个字母按照大写,其他按照小些,如果一个单词全部为大写,保留全部大写。
为了规范省份名称书写格式等带来的统计结果不准确,系统提供省份词典文件进行省份名称的修正,存在软件目录dic/province-chinese.txt中。对于该文件的修改与主题词、人名词典一致。设置格式相似:
地名A1|地名A2|地名A3——含义为用地名A1替换地名A2-A3
|地名B1|地名B2|地名B3——含义为地名B1、B2、B3为无意义地名不在统计范围内
+|A
+|B
+|C
+|A|B|C 只分析或筛选省份字段中含有A或B或C的数据,其他数据不分析
默认条件下,省份词典不区分大小写,第一行取值:0,不区分大小写,全部按小写处理、-1,不区分大小写,全部按照大写处理、1,区分大小写,按照原文大小写处理、2,第一个字母按照大写,其他按照小些,如果一个单词全部为大写,保留全部大写。
在对应的人名、机构、地名、类别、关键词典文本中,#开头行为注释行,第一个非注释行取值0,1,-1,2含义如下:
0,不区分大小写,全部按小写处理
-1,不区分大小写,全部按照大写处理
1,区分大小写,按照原文大小写处理
2,第一个字母按照大写,其他按照小些,如果一个单词全部为大写,保留全部大写
在人名、机构名、国家、省份、类别、项目等字典中可以使用正则表达式进行数据的高级替换和筛选,以CNKI论文为例,CNKI数据中机构名不规范经常会有邮政编码,省份、城市作为机构名称,例如:“有机复合温拌剂对沥青性能影响研究”这篇论文,机构信息如下:
![]()
未在数据清洗前不能穷尽这些信息,导致数据分析不准确,处理方式一:数据清洗或分析后发现异常数据,用字典逐个进行替换或删除,重新进行数据清洗或者分析;处理方式二:在数据未进行清洗或分析前,在机构词典中使用正则表达式进行处理,如下图为机构词典。
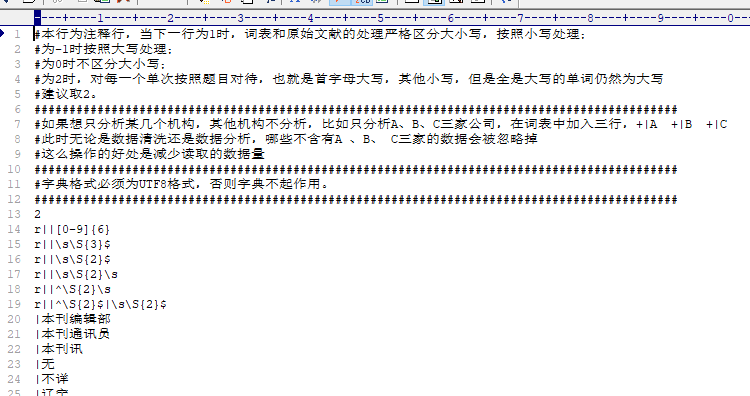
上图中以r开头的表示这一行是正则表达式替换,基本格式为“r|替换后的新的字符|正则表达式查找需要替换的字符”。替换后的新的字符为“”,替换变为删除。
例:r||[0-9]{6}表示将6位数字替换为空,也就是删除六位数字,六位的邮政编码r||\s\S{3}$、r||\s\S{2}$两个分别表示替换长度为3、2的机构名称变为空,也就是删除长度3、2的机构名称,以此类推,可以用正则表达式进行过滤高级删除和替换。正则表达式需要对相关规则有所了解。
第一次使用软件时,首先启动软件,按下图进行字典初始化后关闭软件,再重新启动,即可快速完成字典的设置。
也可以在数据分析和数据清洗的字典标签下进行设置,如下图所示。
ItgInsight提供数据清洗功能,通过对数据进行清洗,生成词典,把生成的词典用于数据分析和可视化中。ItgInsight对数据的清洗,并不改变原始数据,只是通过生成词典对分析过程进行人工干预。
点击工具栏“Data/数据”->“清洗/Cleaning”,进入数据清洗页面,如下图。
选择要进行数据清洗的内容,操作与3.1数据格式转换一致。该步骤也可以选择词典,但不建议使用。此处数据读取可以分批次读取,比如今天读取10个文件,第二天再读取10个文件,后续读取文件时,会提示用户操作行为,如下图:
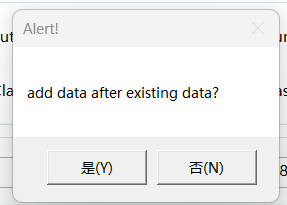
点击“是”在原有数据基础上增加,点击“否”不保留原有数据,形成新的数据集。
清洗后,软件主页面会显示数据清洗读取的基本情况,数据基本情况在“信息/Info”标签下,显示,如下图。
在V2.2版本后,数据一览页面增加了作者*、机构*、国家*,分别表示为通信作者、通信机构、通信国家,这个三个字段的操作、分析、聚类与其他字段完全一致。
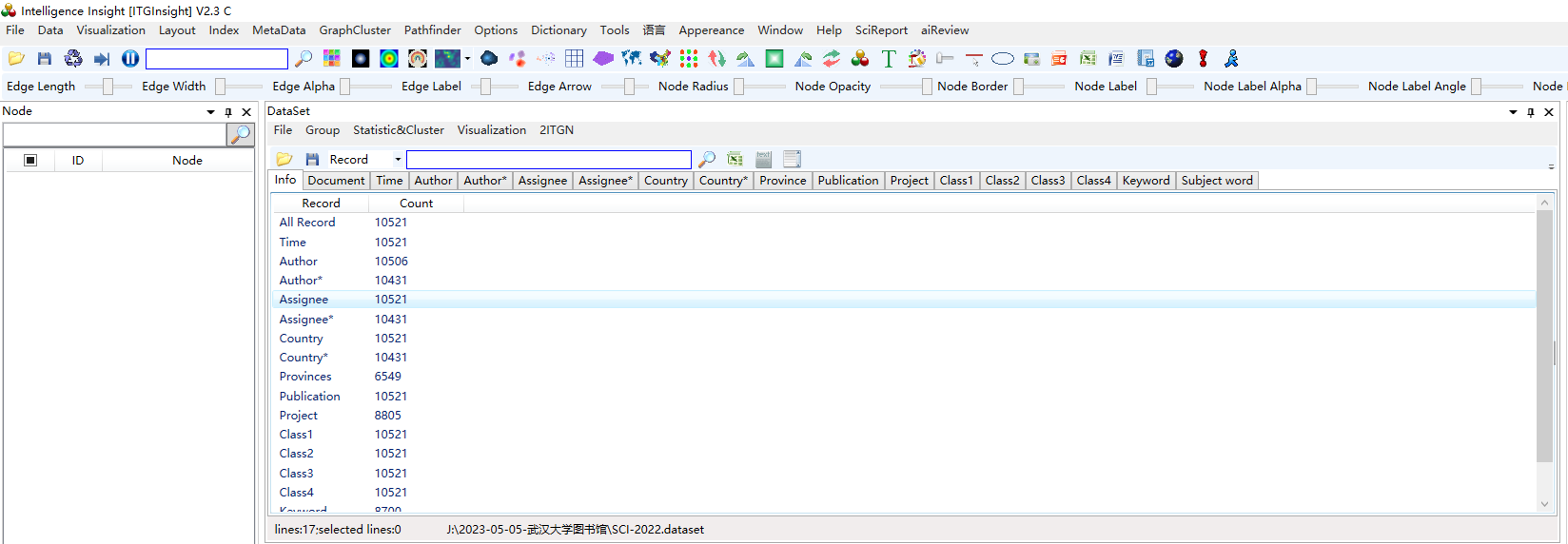
该页面显示了共有多少条记录,其中包括时间的记录有多少条,包括作者信息的记录有多少条,包括机构、国家、省份、出版物、类别1、类别2、类别3、类别4、关键词、主题词的记录分别是多少。
文本框支持在原始记录和分组中进行逻辑查询,
比如查询不包含A的结果,$not A
查询同时包含A BC的结果A $and B $and C
查询包含任意A BC的结果A $or B $or C
同时,支持与CheckBox选择框进行二次组合,CheckBox如下三种状态进行数据过滤



在人名、机构、国家、省份、类别、关键词、摘要词等标签下,通过鼠标左键+shift选择要进行数据清洗的记录,然后鼠标右键点击“Update Group Manu”,如下图。

弹出修改分组窗口,如下图,输出分组名称,即可。
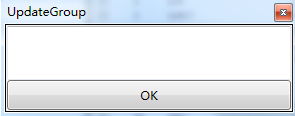
一般情况,输入分组后的名称,一个记录对应一个分组,如果希望一个记录分到多个组里,使用“|”或“$”例如记录A分到组G1、G2在此输入G1|G2,这时生成的词表会将A分到两个组里,以此类推,三个以上分组操作相同。主题词不支持多重分组,其他均支持多重分组。
在作者、机构、国家、省份、类别、关键词、摘要词等标签下,通过鼠标左键+shift选择要进行数据清洗的记录,然后鼠标右键点击“Update Group Auto”。弹出自动分组窗口,如下图。
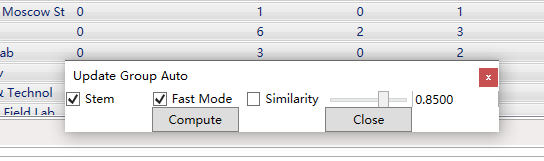
Stemming是针对数据进行词性还原,用于英文。Similarity是否按照相似度进行数据的合并,用滑块设置相似度大小。Fast Mode快速模式的含义与作者清洗的快速模式相同。
如果是人名标签,弹出的自动分组对话框略有不同,如下:
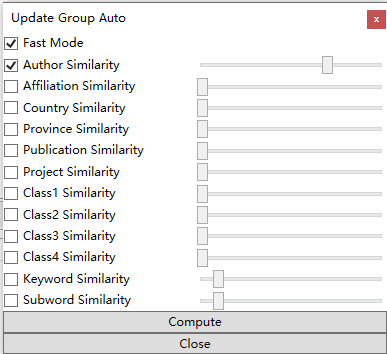
该窗口的意思是如何区分作者是否为相同作者或不同作者,依据作者名称相似度、所属机构相似度、所属国家相似度等等,该功能对于识别同名异指和异名同指具有重要的实用价值。其中Fast Mode快速模式的意思是说:在计算相似度时,根据人名的首字母判断,如果前N个首字母相同,才计算相似度,这样计算相似度的情况会少很多,计算速度明显提升,建议采用快速模式。
之后点击关闭,系统自动计算记录的相似性,计算后的结果如下形式:
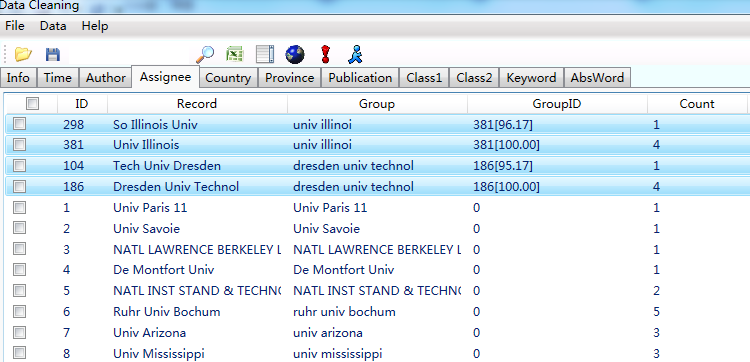
按照GroupID进行排序,如上图记录381和298为一组,其GroupID相同,中括号里的数字为相似度,分组之后的数据存储为词典后,认为是一个记录,在之后的分析中作为用户词典。如果认为计算机分组有误,可点击右键选择取消分组,分组恢复原始状态。
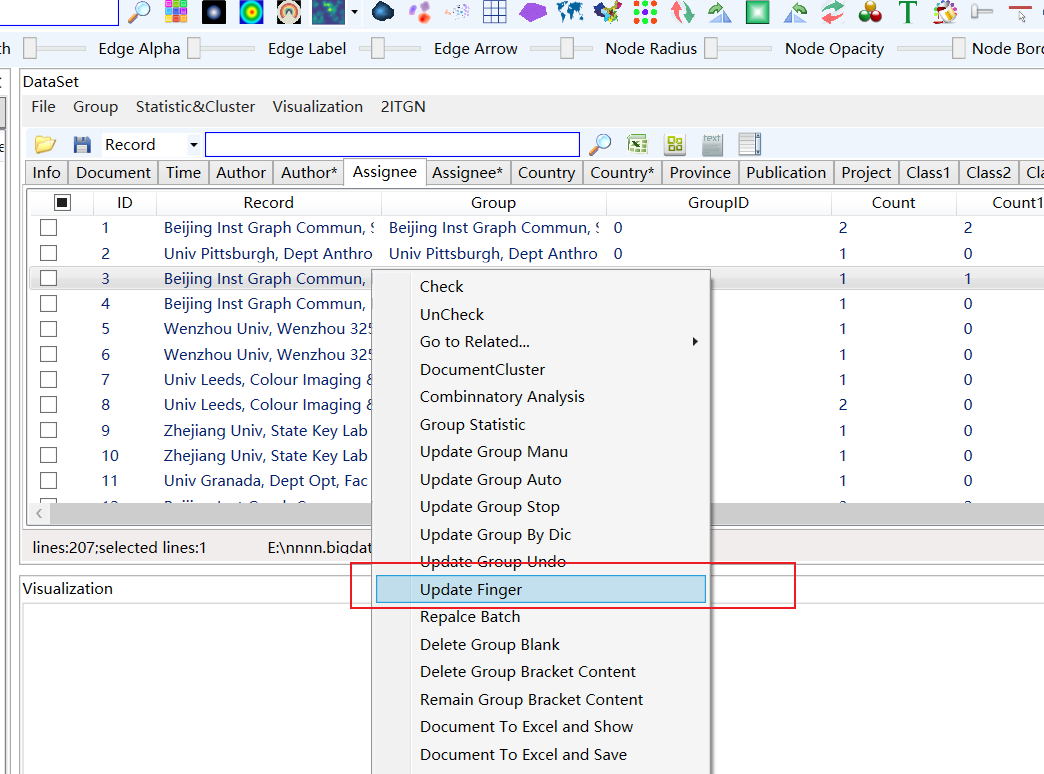
上面Fast Mode默认取单词的第一个字母,可以通过Update Finger/更新指纹,进行修改,如下图:

针对分组名称,也可以采用批量替换方式进行分组名称修改,右键如下图所示,支持字符串替换和正则表达式替换,方法与3.13节点名称替换操作相同。

在进行数据分析时,分组后的记录统一被新的分组代替。为此,需要将记录保存为字典。通过鼠标左键+shift选择要保存的记录,右键点击check,最后点击工具栏的
![]()
按钮,将结果输出为txt格式的字典。也可以将记录保存为excel文件,点击工具栏的
![]()
按钮即可。
保存后的字典可以在以后的数据清洗和数据分析中使用,只需要将其设定到字典目录即可。
如果想用字典进行分组,按如下截图进行操作,可以重复利用字典,避免重复工作。
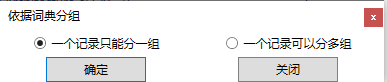
用词典分组,会提示用户是否允许将一个记录分到多个组,如下截图。

清洗后的结果,点击工具栏的保存按钮将结果保存,下次使用时通过工具栏的打开按钮打开即可,如下截图:

dataset格式,为默认的正常保存格式,适用于数据量不超过3万条的情况;Excel也可以用于保存数据量3万条以下的情况,并且可应用Office或WPS进行查看。
bigdataset格式,适用大数据量,一般超过5万条建议保存为bigdatset,超过10万条必须保存为bigdataset;bigdateset格式是Sqlite数据库文件,可以通过Sqlite Expert等第三方软件打开,如下图,该数据库文件支持各种自定义用户的扩展功能。

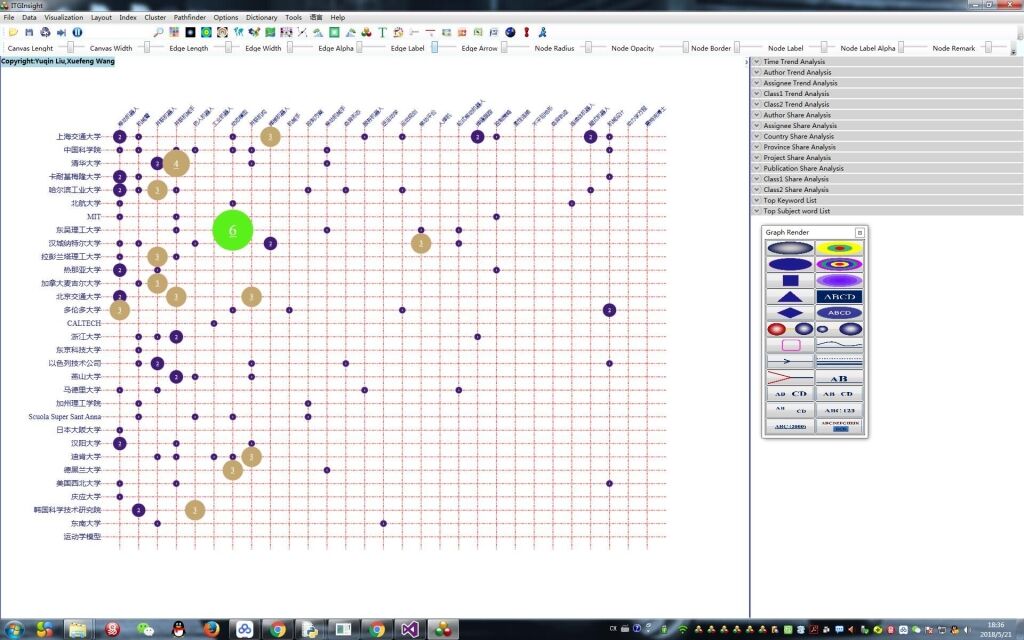
在时间、作者、机构、国家、省份、类别、关键词、摘要词中任意选择3个维度中的若干数据,勾选数据。点击菜单栏或鼠标右键按钮Combinatory Analysis/组合分析,如下图。
弹出组合分析对话框,选择要分析的行,列和统计的标准,类型,如下图:
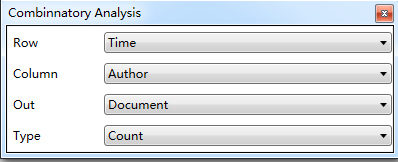
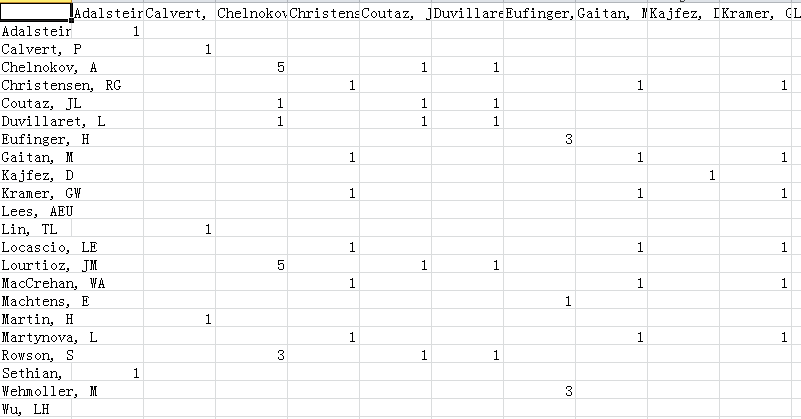
上图的含义是统计时间、作者两个维度交叉后的文献数量。

上图的含义是统计机构、作者两个维度交叉后的参考文献数量,也就是某个作者引用了某个机构的文献数量。

上图的含义是统计机构、作者两个维度交叉后的参考文献列表,也就是某个作者引用了某个机构的文献列表(文献的ID号)。
选择之后,关闭该窗口,系统调用Excel输出统计矩阵,如下格式:
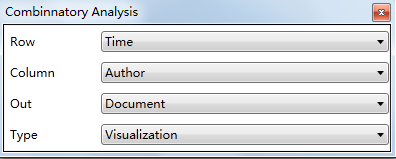
上图的含义是时间、作者两个维度交叉后的文献数量后,直接在软件的图形区域输出可视化图形。
组合分析是对数据进行二维、三维统计,如果在数据分组后,按照分组进行一维统计,勾选要统计的选项,菜单栏或鼠标右键点击分组统计/Group Stat进行一维的分组统计,如下图:
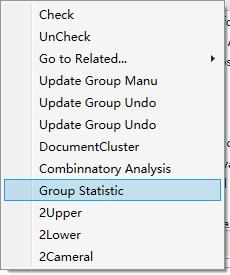
无论是分组统计还是组合分析,都是按照新的分组进行计算。
在数据清洗界面点击鼠标右键选择cluster/聚类,如下图:
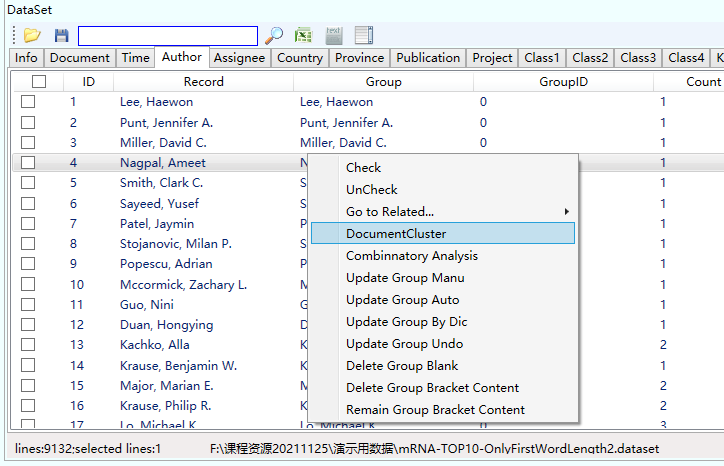
其中cluster为聚类对象,默认为对文档进行聚类。by为聚类采用的字段为,默认为关键字,可选择其他字段。how many为采用多少关键词进行文档关系的计算,这个数据越大,聚类时间越长。algorithm为降维算法,默认TSNE,效果最好,但是最慢,PCA最快,效果最差,KPCA介于二者之间。out为输出内容,默认为输出网络可视化图,也可以选择密度图。color制定聚类后的网络节点颜色区分,是按照哪个字段进行区分,比如按照文档所属机构或者所属国家进行颜色区分,默认为不区分颜色。注意:无论是哪个字段,必须勾选才起作用,不勾选的文档不聚类,不勾选的关键词字段或其它字段在聚类分析过程中不起作用。
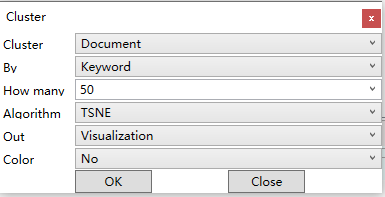
聚类计算完成后,在主窗体显示聚类结果的网络图,形式如下:
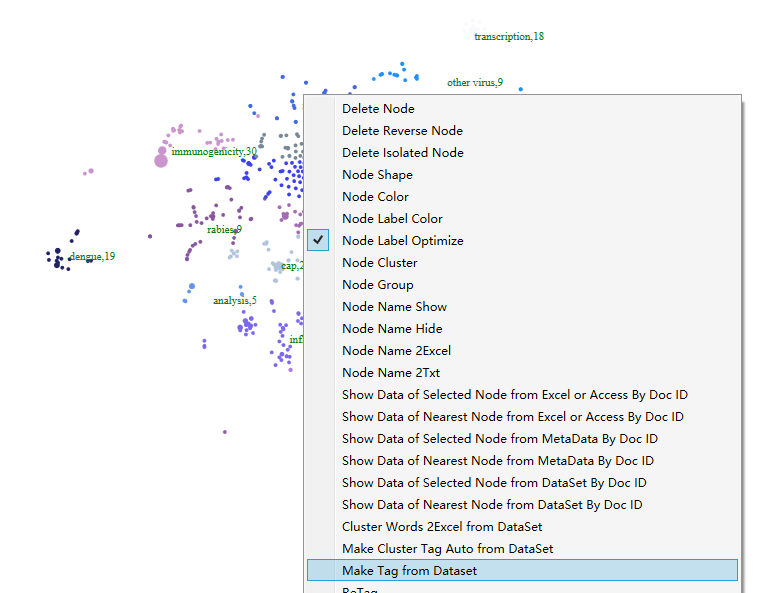
进一步对聚类图聚类结果打标签,点击鼠标右键,如下图:
弹出输入标签框:如下图:
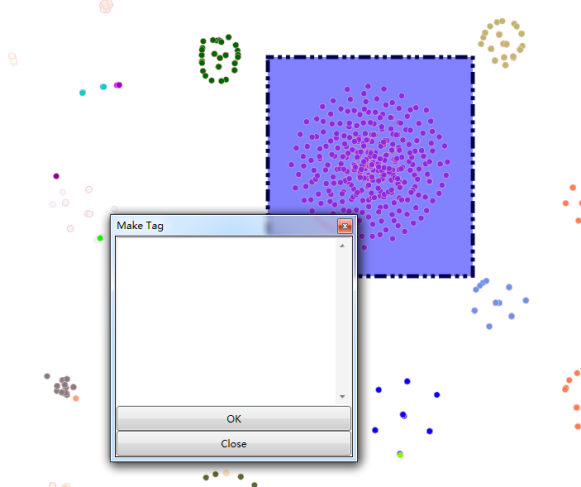
可手工输入标签,如对聚类进行命名,标注每个类别的主题词。同时,如果数据清洗界面打开了聚类图对应的dataset,软件会推荐类别标签内容。通过鼠标右键的Tag Color更改标签颜色,通过滑块设置tag滑块,更改标签大小。打过标签的聚类图如下:

手工打标签比较繁琐,可以在上图右键弹出菜单的Make Cluster Tag Auto from Dataset功能,为每个聚类结果自动打标签。
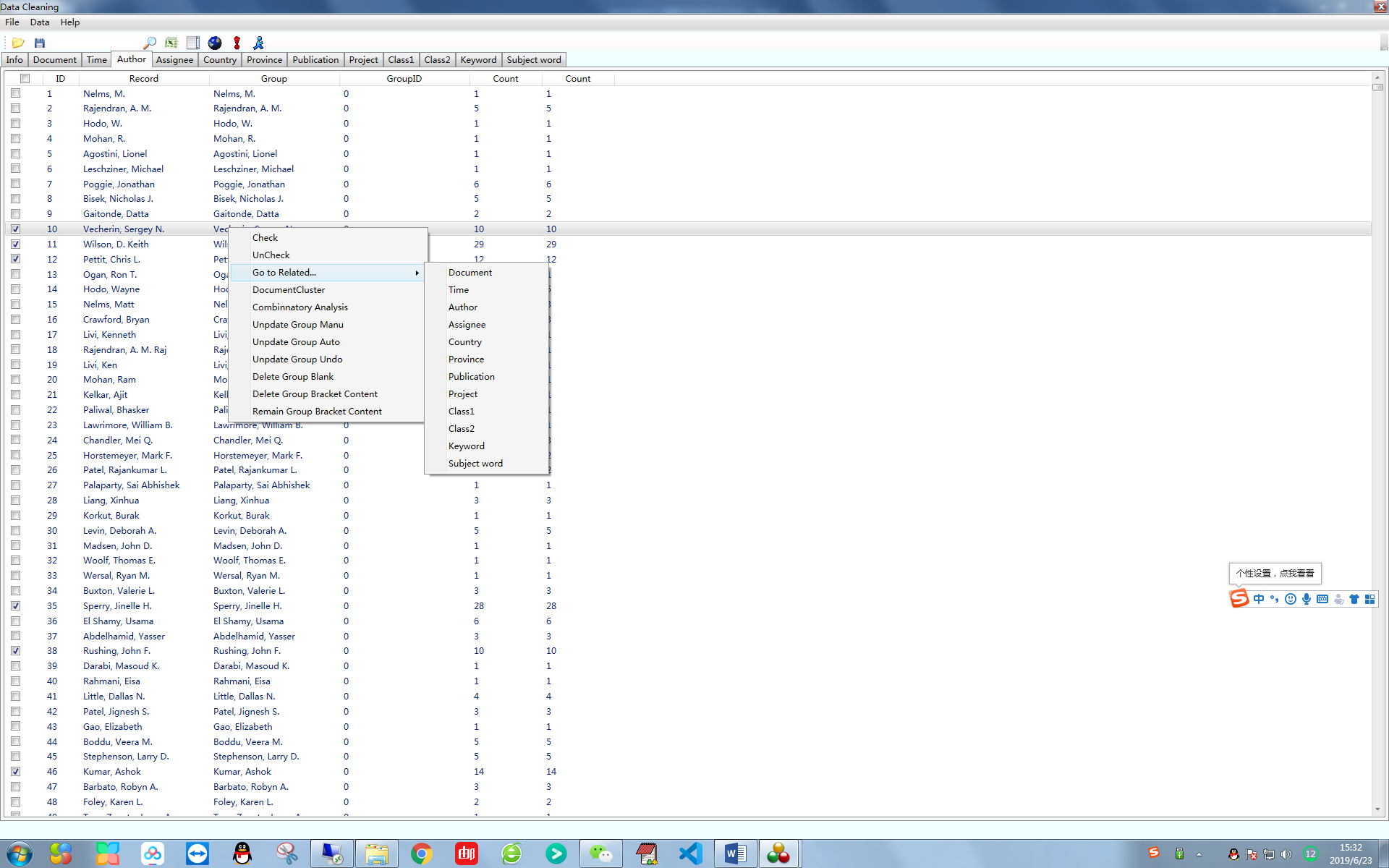
在数据一览,任何一个维度,选中几条数据,点击右键,如下图,导航到对应的数据。如选中任何一个作者,点击go to related->publication,则会导航这几个作者发表论文对应的期刊,以此类推,可进行任意维度数据的链接。
在Dataset页面右键点击Document to Excel and Show、Document to Excel and Save、Document to Txt,数据Dataset转存到Excel或Txt文件,如下图所示。
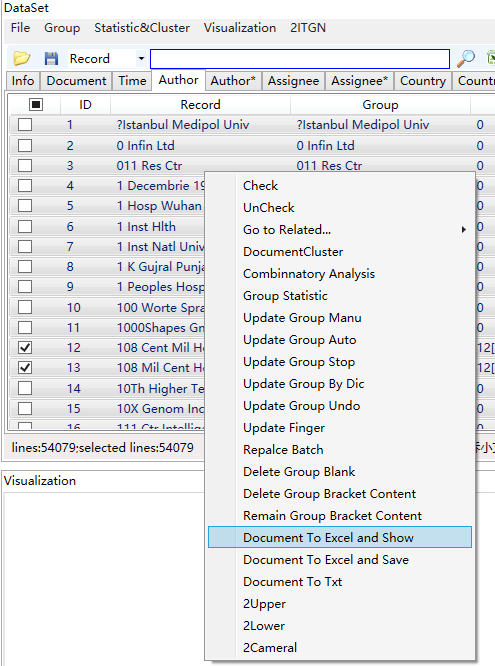
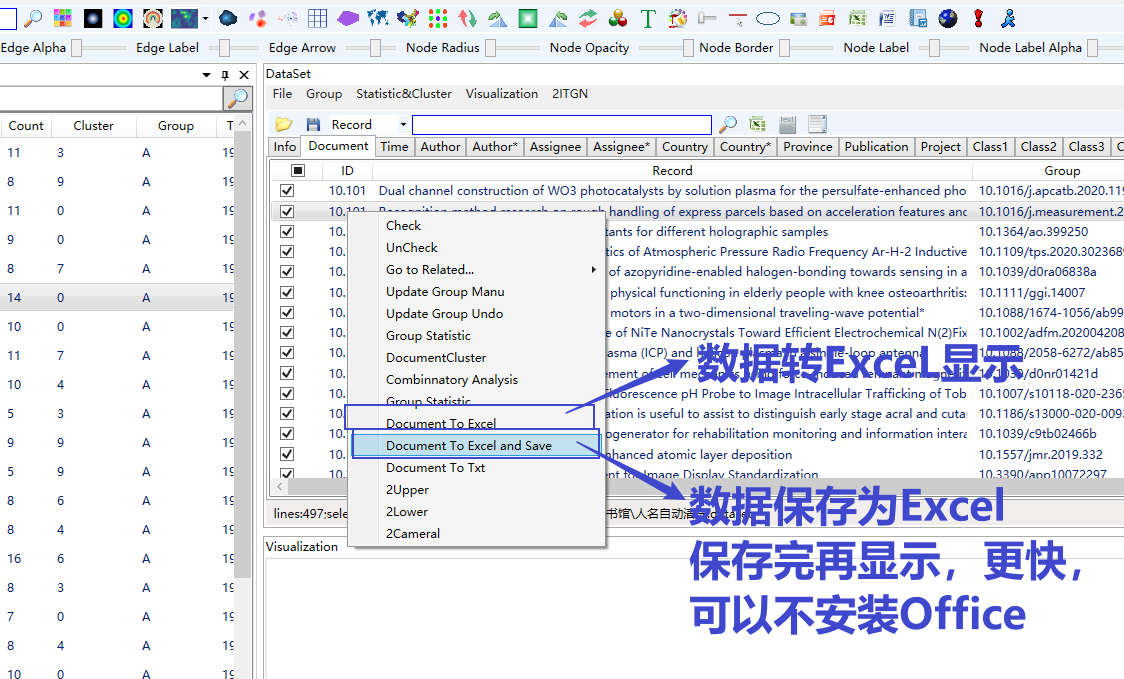
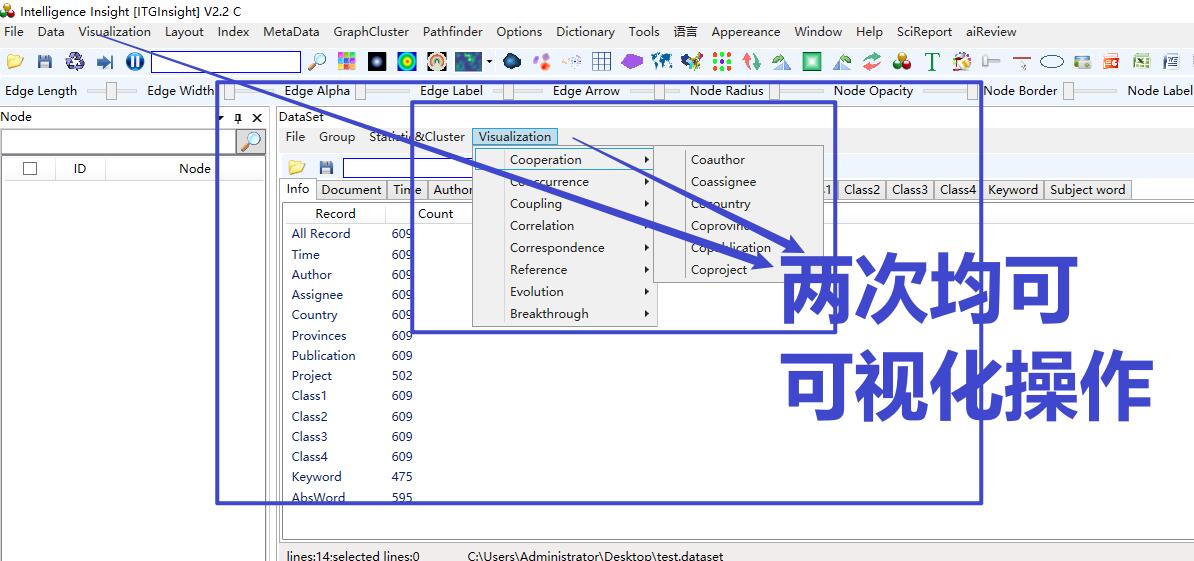
V2.2版本开始,数据清洗后的Datset页面提供了与数据分析页面类似的可视化操作,该操作如下截图。此处可视化,务必勾选对应的字段信息,才会显示结果。同时,此处的可视化,是对已经数据清洗后的结果进行的可视化,省略了词典的操作,与词典具有类似的效果。
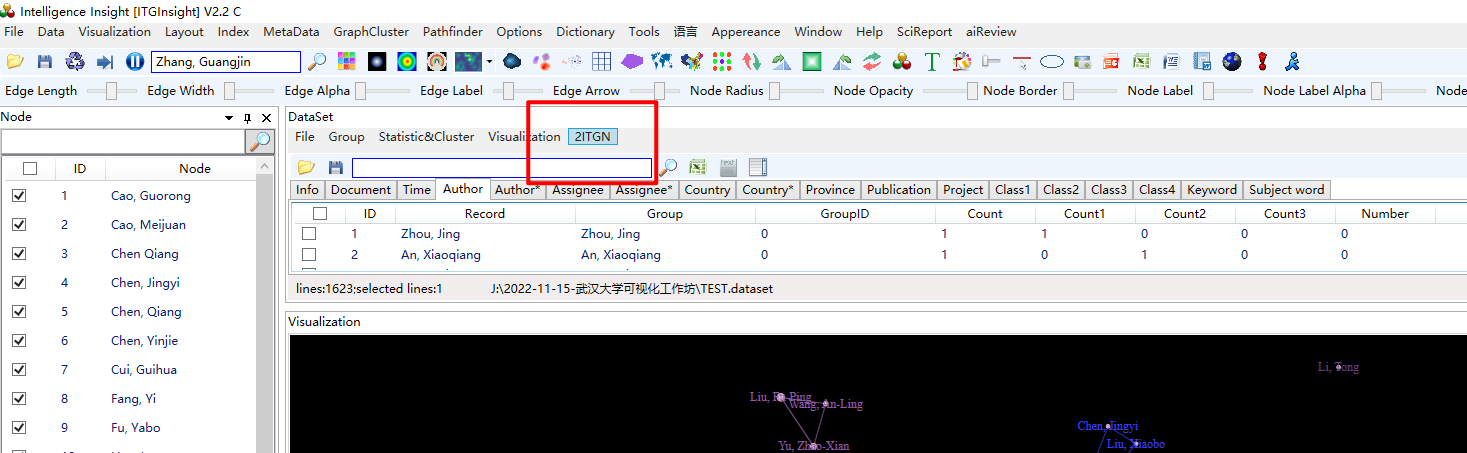
V2.2版本后在数据清洗后的Dataset页面,点击菜单栏的2ITGN按钮,将Dataset转化为itgn文件,此处生成的itgn文件与数据分析出生成的itgn文件基本相同,存储的各种维度统计和可视化结果,如下图。转化前必须在Dataset页面勾选需要分析的信息,否则itgn中无对应的结果,也就没有对应的维度统计和可视化内容。
本章所列工具在V2.3.8以后版本中删除,仅在V2.3.8以前版本中保留。
点击“Tools/工具”——>“ItgFamily/INPADOC同族分析”调取世界专利同族实时更新与分析系统ItgFamily,如下图:
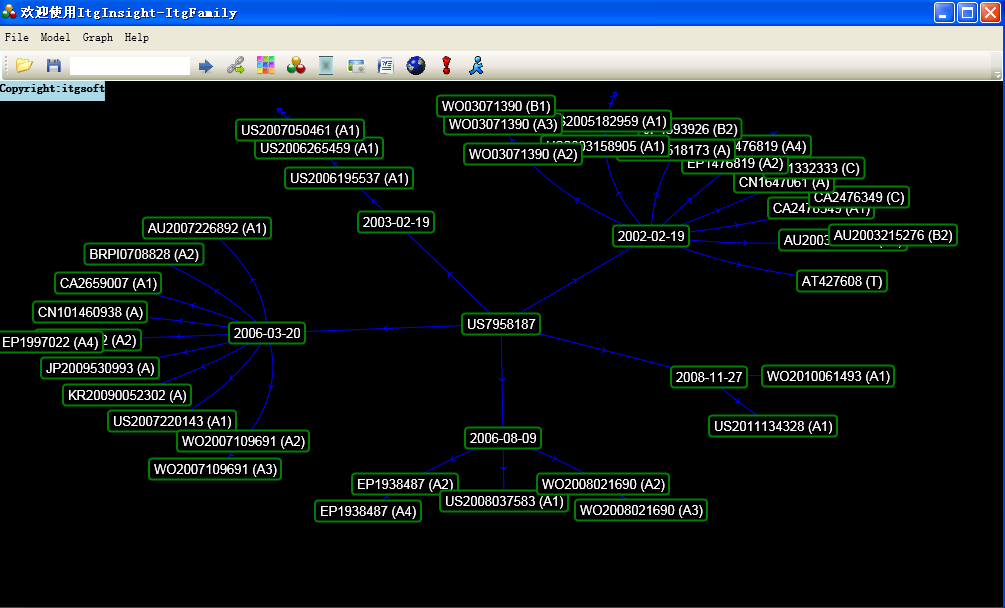
ItgFamily世界专利同族实时更新与分析系统是一款“企业专利战略决策”支持工具,该系统主要实现世界专利的同族数据采集以及树形呈现。其最大的特点是对于专利在不同时间,不同国家进行的同族申请进行实时更新,并以树形结构,按时间顺序排列同族专利,在屏幕上显示的专利个数没有限制。系统采用鼠标双击和拖动进行用户交互,分析图形简洁优美,结构清晰。关于该工具的使用查看其对应的帮助文件itgfamily帮助.pdf。
点击“Tools/工具”——>“ItgReference/美国授权专利引证分析”调取美国专利引证信息实时更新与分析系统ItgReference,如下图:

ItgReference美国专利引证实时更新与分析系统是一款“企业专利战略决策”支持工具,该系统主要实现美国单件专利的前引、后引数据采集以及树形呈现。其最大的特点是前引、后引的专利引证层级没有限制,在屏幕上显示的专利个数没有限制。系统采用鼠标双击和拖动进行用户交互,分析图形简洁优美,结构清晰,可以与Aureka的专利引证图谱相媲美。关于该工具的使用查看其对应的帮助文件itgreference帮助.pdf。
点击“Tools/工具”——>“ItgClaims/美国专利权利要求分析”调取美国专利权利要求系统ItgClaims,如下图:
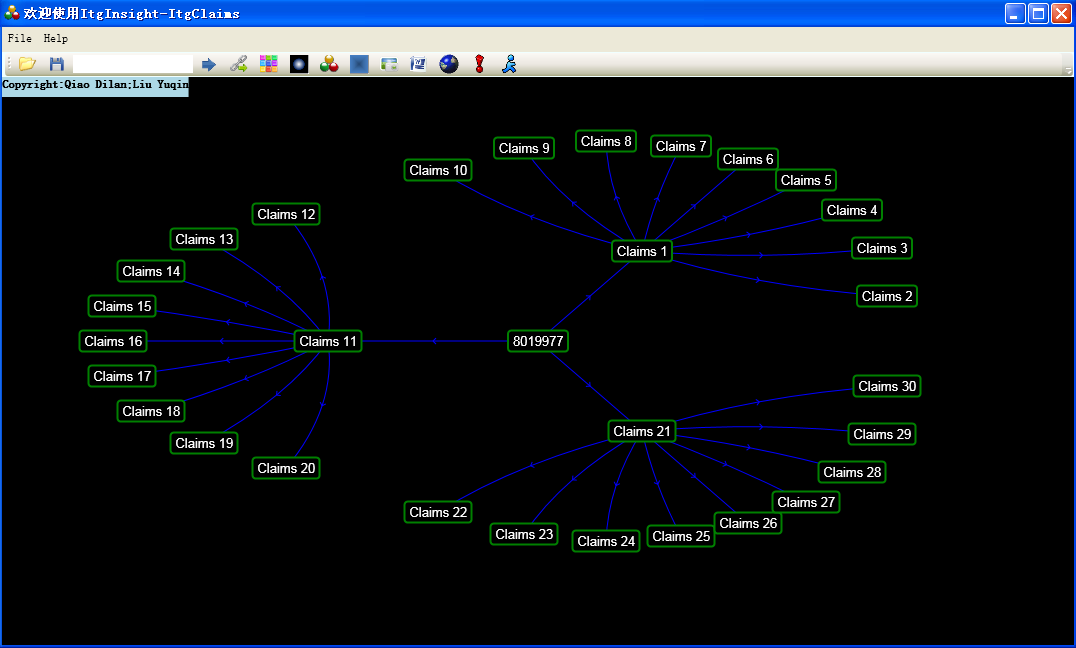
ItgClaims美国专利权利要求解析系统,作为通用科技文本可视化挖掘系统ItgInsight的子系统,主要实现美国单件专利权利要求中的独立权利要求和从属权利要求在线搜索、提取、结构解析与可视化呈现。其最大的特点是自动生成权利要求结构树,并以可视化的形式显示,在屏幕上显示的权利要求个数没有限制。系统采用鼠标双击和拖动进行用户交互,解析图形简洁优美,结构清晰。关于该工具的使用查看其对应的帮助文件itgclaims帮助.pdf。
ItgInsight系统支持5种类型的自定格式数据进行可视化,分别为.ima,.imb,.imc,imd和excel格式。
第一类:ima格式数据参考软件安装目录example\ima下的文件,格式如下:

ima格式数据是最简单的矩阵数据,数据以单个空格分隔,ima格式数据仅用于数据演示,方便用户理解不同layout算法的区别,一般不在实际的分析项目中进行应用。
第二类:imb格式数据参考安装目录example\imb下的文件,格式如下:
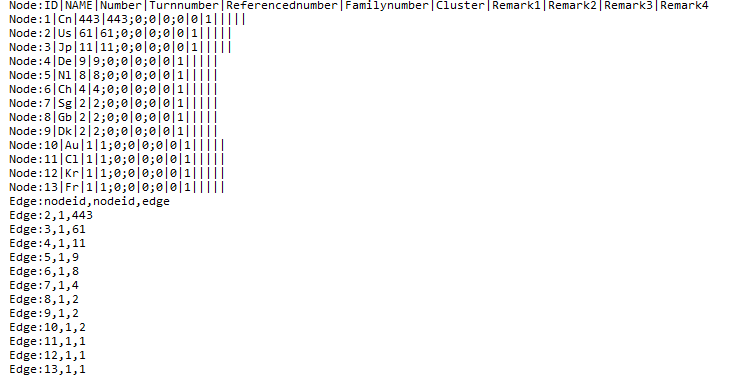
imb格式数据可以定义节点和连线,进行简单的可视化展示。
Node:ID|NAME|Number|Turnnumber|Referencednumber|Familynumber|Cluster|Remark1|Remark2|Remark3|Remark4
用以定义节点,其中ID为节点唯一标识,采用1、2、3…加以区分,不能重复;
Name为节点名称,会在可视化图形中进行显示;
Number为节点代表的数量;
TurnNumber为节点表示的第一、二、三作者数字,其和必须与Number相等;
Referencenumber为节点的引证和被引数量,两个数字,都可以为0;
FamilyNumber为节点的同族专利数量,一个数字,可以为0;
Cluster为节点所属的类别,类别采用1、2、3…进行编号,也可以都为0;
Remark1,Remark2,Remark3,Remar4为节点的备注文字,最多为4个,可以为空。
Edge:nodeid,nodeid,edge
用以定义连线,nodeid为连线起止节点的编号,该编号必须在节点定义进行了定义;
Edge为连线表示的数量。
第三类:imc格式数据文件为最灵活的格式,也是最强大的数据格式,如下:

Node:NAME|Number|Turnnumber|Referencednumber|Familynumber|Cluster|Remark1|Remark2|Remark3|Remark4|color|shape
用以定义节点,与imb格式不同,imc格式只需定义节点名称,不需定义节点编号,但节点名称不能重复。
color为节点颜色;
shape为节点形状,只能为1或0,分别对应圆形和矩形。
Edge:nodename|nodename|edge|label|color
用以定义连线,nodename为连线起止点的名称;
edge为连线的数量;
label为连线的文字标注;
color为连线的颜色。
第四类:imd格式数据文件也是较为灵活的格式,如下:
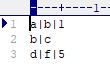
读取后会构建一个由 a b c d f五个节点,a到b连线为1,d到f连线为5的网络图。imc和imd格式适用于那些带有单个方向的网络数据,比如专利转移转化,也可以用于带有双向指向的数据。如上图,还可以增加f | d | 3,表示f到d连线为3,与d 到 f连线为5,一起构成双向图。
第五类:excel格式的数据文件,参考安装目录example\excel中的文件,格式如下:

或者如下:
用户打开excel格式文件后,系统会询问用户打开的数据是频数矩阵、相似矩阵、皮尔森矩阵中的哪一种;是否依据输入矩阵进行矩阵运算以便得到同现矩阵、关联矩阵、对应矩阵,如下图:

如果选择Similarity Matrix/相似矩阵、Pierson Matrix/皮尔森矩阵,系统默认不对矩阵进行任何计算,直接将矩阵转化为网络图。
如果选择Frequency Matrix/频数矩阵,不进行计算,如果频数矩阵行名和列明完全相同,输出网络图为1模网络图;如果不完全相同为2模网络图。
如果选择Frequency Matrix/频数矩阵,按照剩余三种模式进行计算,系统默认对矩阵进行计算,分别为同现分析,对应分析,关联分析,对数据进行计算后进行可视化输出。
在V1.2版本以后,ItgInsight将中英文术语识别正式嵌入到软件中,具体操作在数据清洗功能中,按照6.1节选择数据源,勾选Subject Word/主题词选项,如下图:
切换到Dictionary/字典标签下,选择字典(一般选择安装目录dic目录下的默认字典),分词选项选择Wordseg+Thesaurus/分词+词表,如下图:
切换到Alpha/阈值标签下,如下图:
C-Value/是否进行术语度计算,术语度计算耗时较长但是可以提供“该词是否为术语”的参考,词长度和词频的选择依据用户偏好进行设置,如果数据较多,建议相关阈值设大些。主题词的合并可以采用UpdateGroup_Auto(参见6.4数据自动分组实现数据清洗功能一节)进行。
第十章:与VosViewer,Pajek,Ucinet进行交互
系统支持将可视化图形导出为VosViewer,Pajek,Ucinet等可视化软件的输入格式文件,操作方法为点击:Sava/保存即可,如下图。保存后的文件可直接被VosViewer,Pajek,Ucinet使用。

同时,系统提供打开Pajek软件net格式的图形文件,如下图,点击打开,选择对应net文件即可。
本软件提供了net扩展格式netx格式的图形文件输入,netx与net格式的差别是netx可以指定网络节点的大小,具体格式参考example/netx/example.netx文件。
ItgInsight应用机器学习进行研究报告的自动化、智能化、模块化撰写,系统提供默认的报告撰写模板,也可以自定义报告模板。自动报告功能仅限于顶级企业级用户,由计算机进行报告的智能组织,用户仅做轻微的修改,具体操作如下。
打开.itgn文件,点击菜单栏的word图标,弹出如下界面:
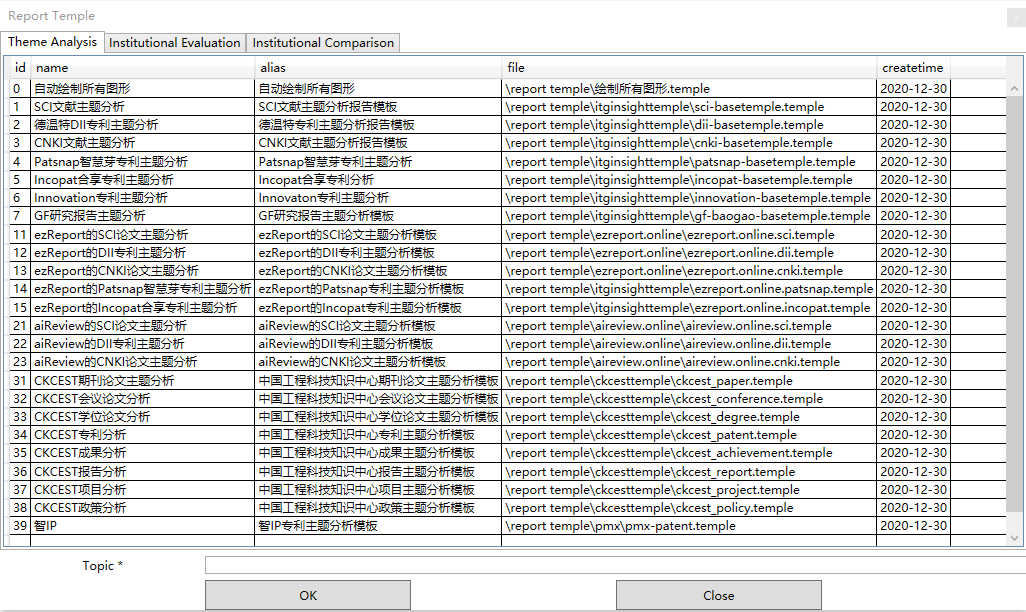
系统支持三类模板,主题分析模板,单个机构评价模板,多个机构对比模板。例如,选择一个报告模板,在Topic/主题文本框填写分析报告的技术领域,比如“纳米技术”,点击OK/确定按钮,软件自动撰写报告,用户根据需要进行修改,具体操作详见视频教程“智能报告撰写”。撰写报告的中间结果,包括各种矢量图、统计表格在软件安装目录report temple下。
自动报告对于企业版用户开放,个人用户使用时需要单独进行微信支付,每次支付会获得1小时授权,对1个itgn文件进行自动报告的输出,支付金额与itgn文件的数据量成正比,数据量越多,金额越大。
scireport.online\ aireview.online两个在线的自动报告系统生成的报告是ItgInsight自动报告的子集,ItgInsight生成的报告模板更多,处理的数据规模更大。
元数据是指在数据分析完成、图形绘制完成后,将图形数据与后期导入的数据进行一一对应,类似于GELPHI的增加列功能。具体操作如下:
任何绘制好的图形后,点击工具栏的元数据按钮,如下图,弹出元数据页面:
点击导入元数据,系统提示输入access、excel、txt格式的元数据文件,TXT格式的元数据文件格式如下:
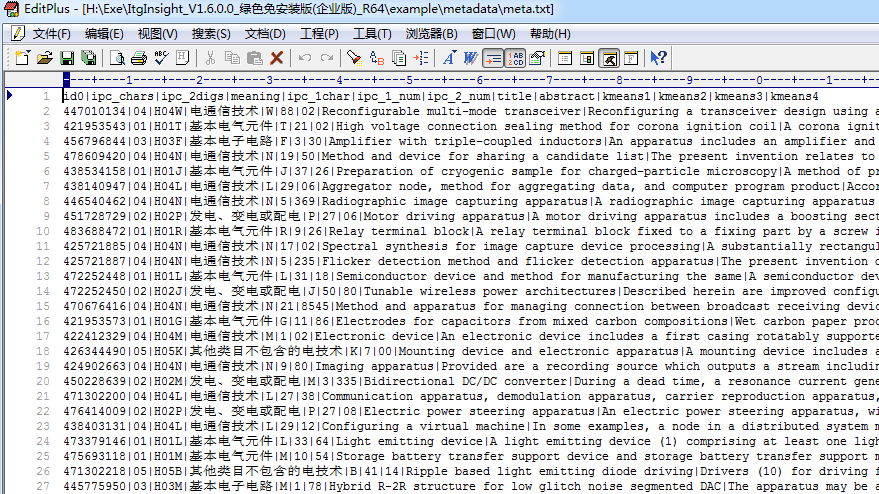
第一行为表头,之后为数据,“|”进行列分割。元数据与图形数据通过ID列进行对应,ID列必须为1、2、3、4…格式的数字。或者导入元数据不包括ID列,软件自动添加ID列。对于EXCE和ACCESS格式的元数据ID列的要求相同。
当导入的元数据列想以数字型导入,在表头加/double,比如上图设置为“ipc_chars/double”后ipc_chars列以数字型导入。
推荐以EXCEL格式进行元数据的导入。
如果导出原始,点击导出按钮,系统默认导出txt格式的元数据,点击工具栏的EXCEL图标,则会导出EXCEL格式的元数据。
导入元数据后,如果想增加列,点击“增加列”按钮,导入方式与元数据导入一致,只是在先前导入的元数据后面再增加列。
12.3 依据元数据对图形进行查找、更改节点大小、更改节点文字、绘制凸包
根据导入的元数据对图形进行操作,点击工具栏,选择操作的列名,如下图。通过工具栏的
![]()
对图形进行修改,分别对图形进行查找、更改节点大小、更改节点文字、绘制凸包。凸包效果类似于CiteSpace凸包可视化、DDA的Aduna Map聚类图。

导入元数据后点击保存按钮,提示保存为.metadata格式的元数据,即二进制元数据,之后可以直接打开,节省每次元数据导入时间。
点击菜单栏上的“Data/数据->Analysis/分析”,弹出数据转化页面,点击ToReference可将文献著录项目转化为word版本的参考文献格式。此处特别注意,选择的过滤器必须为filter目录下,标记为ToReference专用的过滤器,如图所示:

参考文献格式编辑器为软件目录下的Referenceformat.json文件,打开如下:

以第一个参考文献格式为例,含义如下,依据过滤器中的“PublicationType”的值,如果文献中“PublicationType”的字段值为“J”,采用ReferenceFormat的格式进行参考文献编辑,其中:
AuthorMeta$,的意思是在输出参考文献时,文献作者之间用逗号分隔;
+.$AuthorMeta的意思是如果存在文献作者字段,在作者后面加上符号“.”;
以此类推,可以自定义参考文献格式;
软件默认支持CNKI和SCI的文献著录项目转化为参考文献,也可以增加其他数据源的参考文献格式。
| 模型\图形元 | 节点大小 | 节点颜色 | 节点连线 | 节点文字 |
|
|
第一、二、三作者数量 | 红色第一作者数量、绿色第二作者数量、黄色第三作者数量 | 合著/同现/耦合数量多少,越多线越粗(如果选择VS和UP布局算法,那么连线的长度与连线所代表的数量呈反比) | 作者/机构/国家/出版物 |

|
数量 | 颜色由内向外逐渐变浅,颜色环与各年份数量成正比,红色表示最接近目前的时间 | 同上 | 同上 |

| 模型\图形元 | 节点大小 | 节点颜色 | 节点连线 | 节点文字 |
|
|
数量 | 无意义 | 关联性越大线越粗;反之、越细(如果选择VS和UP布局算法,那么连线的长度与连线所代表的数量呈反比) | 作者/机构/国家/年代 |

|
同上 | 颜色由内向外逐渐变浅,颜色环与各年份数量成正比,红色表示最接近目前的时间 | 同上 | 同上 |

| 模型\图形元 | 节点大小 | 节点颜色 | 节点形状 | 节点连线 | 节点文字 |
|
|
数量 | 无意义 | 圆表示作者或机构、矩形表示技术类别 | 关联性越大、线越粗;反之、越细(如果选择VS和UP布局算法,那么连线的长度与连线所代表的数量呈反比) | 作者/机构/国家/年代/类别 |
| 模型\图形元 | 节点大小 | 节点颜色 | 节点连线 | 节点文字 |
| 文献引证 | 无意义 | 无意义 | 引证关系 |
文献号
(文献唯一标识) |
| 作者/机构/期刊引证 | 被引用数量 | 无意义 | 引证关系 |
作者+年代/
机构+年代/ 出版物+年代 |