本手册用于指导用户在 SciMetrics 中完成 AI 主题竞争力指数计算、AI 主题竞争分布图生成、地形图观察、热力矩阵辅助分析与结果导出。
图1:SciMetrics “指数”和“AI”菜单
一、操作方法
1. 功能适用场景
AI 主题竞争力指数与分布图适合回答以下问题:
- 哪些作者、机构或国家在某些 AI 主题上具有更强竞争贡献?
- 某个主题的主要竞争主体是谁?
- 高竞争贡献论文在主题空间中集中在哪里?
- 不同 AI 主题之间是否形成相近的竞争格局?
- 能否同时用指数表、分布图、地形图和热力矩阵支撑报告结论?
该功能包含两个层次:
| 层次 | 功能 | 主要用途 |
| 指数层 | AI 主题竞争力指数 | 导出作者、机构、国家在各 AI 主题上的竞争力矩阵 |
| 可视化层 | AI 主题竞争分布图 | 用论文节点、主题空间、地形峰值和热力矩阵展示竞争格局 |
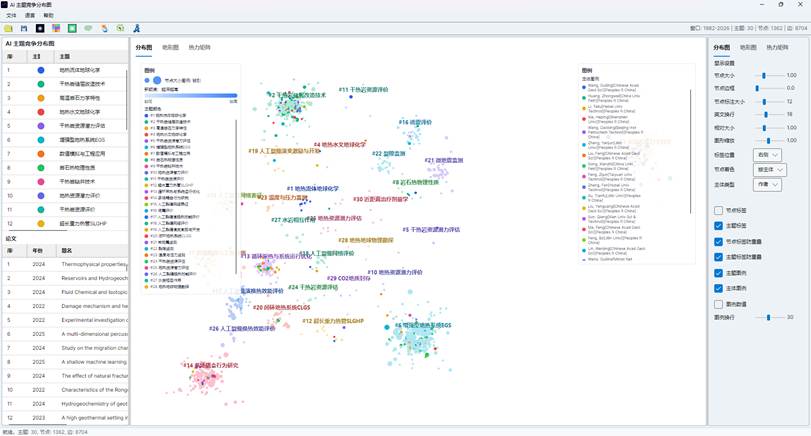
图2:AI 主题竞争分布图窗口
2. 准备数据
2.1 打开或导入数据集
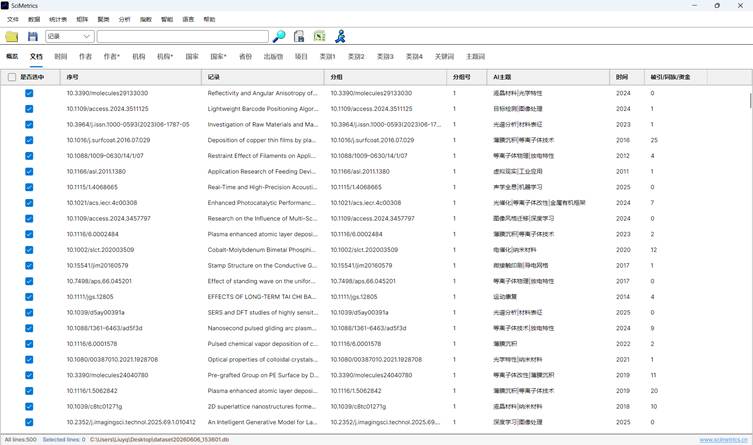
首先打开 SciMetrics,并导入已经整理好的文献数据。建议数据中至少包含:
| 数据字段 | 用途 |
| 题名 | 显示论文节点和论文列表 |
| 年份 | 支持分布图模型的年份信息 |
| 被引次数 | 参与竞争贡献计算,并决定节点大小 |
| AI 主题 | 决定论文所属主题和竞争力矩阵列 |
| 作者 | 生成作者维度竞争力指数和主体着色 |
| 机构 | 生成机构维度竞争力指数和主体着色 |
| 国家 | 生成国家维度竞争力指数和主体着色 |
| 关键词、主题词、引用、分类 | 用于构建论文间混合关系和空间布局 |
如果只希望分析部分文献,可先在文献列表中勾选目标论文。后续指数和分布图窗口中的“仅使用勾选文献”会读取这些勾选状态。
图3:数据集后的文献列表
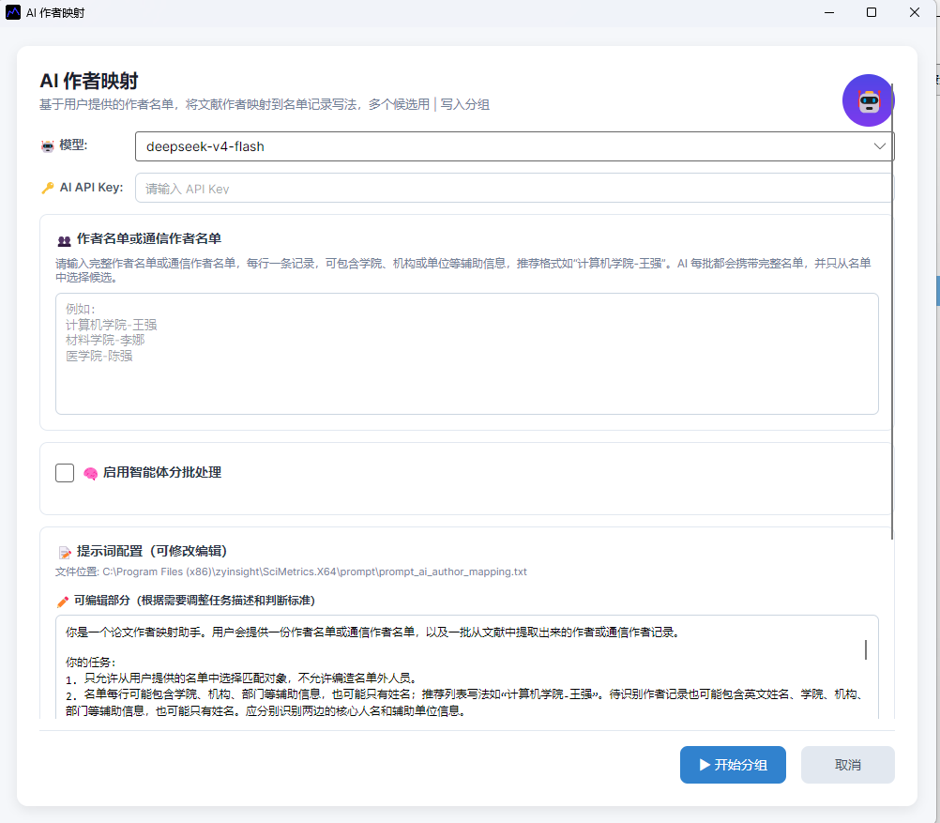
2.2 生成或检查 AI 主题
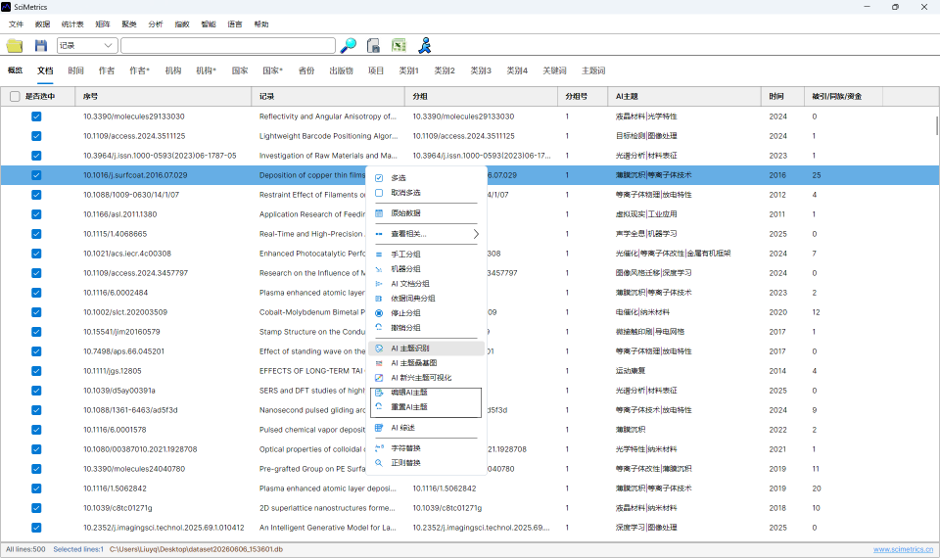
进入:
AI → 文档 → AI 主题识别
系统会为文献生成 AI 主题。AI 主题是竞争力指数和分布图的共同基础,没有 AI 主题时无法计算。
生成后建议检查:
- 文献是否已经写入 AI 主题;
- 主题名称是否清晰、可解释;
- 同义或近义主题是否需要合并;
- 明显错误的主题是否需要修改。
如需调整,可使用:
AI → 文档 → 编辑 AI 主题
AI → 文档 → 替换 AI 主题
AI → 文档 → 重置 AI 主题
图4:AI 主题识别菜单
2.3 检查作者、机构和国家数据
竞争力指数支持三个主体维度:
| 维度 | 使用的数据 |
| 作者 | 作者表和文献-作者关系 |
| 机构 | 机构表和文献-机构关系 |
| 国家 | 国家表和文献-国家关系 |
建议在计算前检查作者、机构、国家标签页:
- 是否存在明显重复或错误名称;
- 是否已经完成必要的作者消歧、机构规范化或国家规范化;
- 如果只分析部分主体,是否已经勾选目标主体;
- 文献与主体的关联是否完整。
3. 导出 AI 主题竞争力指数
进入:
指数 → AI 主题竞争力指数
系统会弹出指数计算选项窗口。
| 选项 | 含义 | 建议 |
| 仅使用勾选文献 | 只计算当前勾选的文献 | 做专题子集分析时勾选 |
| 仅使用勾选主体 | 只计算勾选的作者、机构、国家 | 做重点主体比较时勾选 |
如果取消勾选,系统会使用全部文献或全部主体。数据量较大时计算可能耗时较长,软件会在后台执行。
图5:AI主题竞争力指数入口
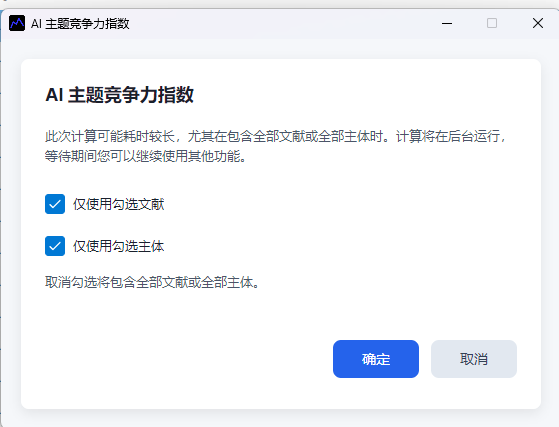
图6:AI 主题竞争力指数选项窗口
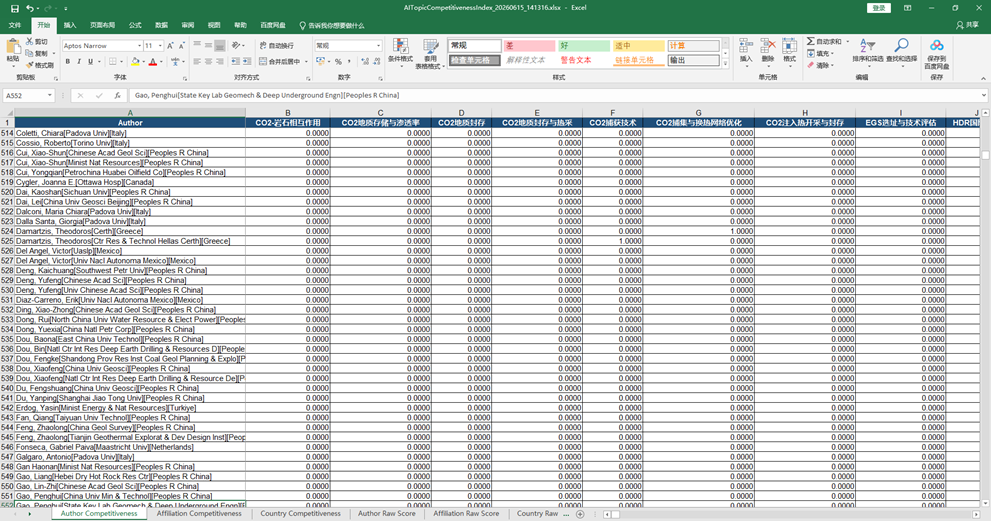
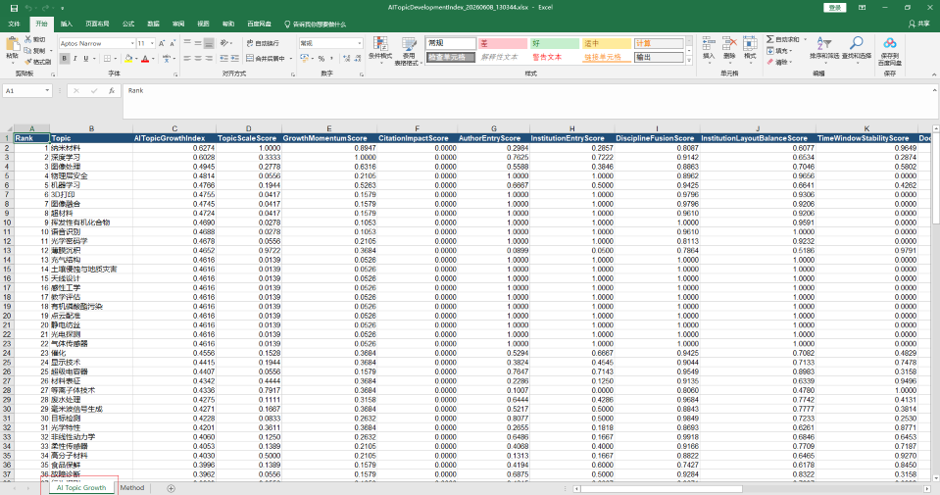
点击“确定”后选择保存位置。系统会导出 Excel 文件,默认文件名类似:
AITopicCompetitivenessIndex_yyyyMMdd_HHmmss.xlsx
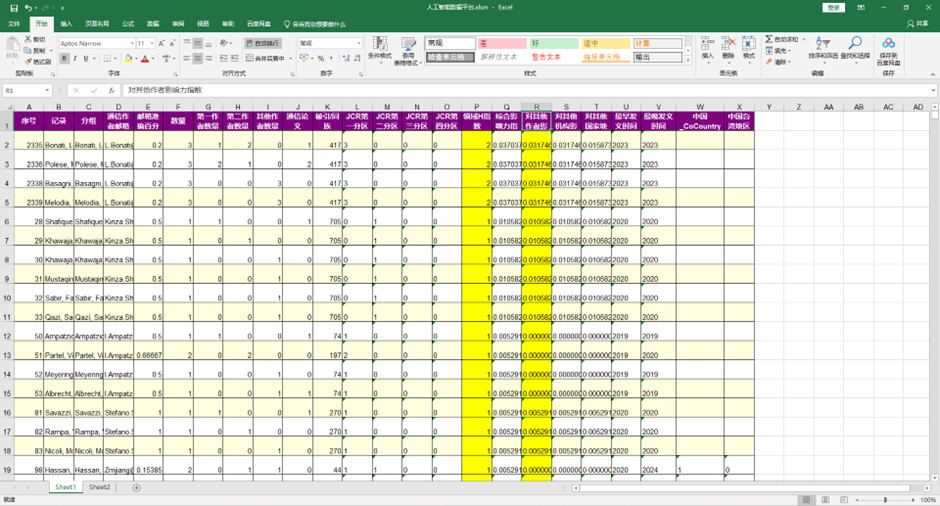
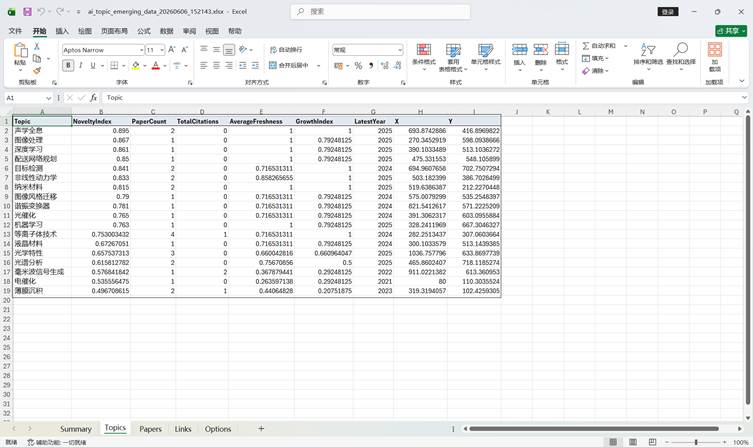
Excel 中主要包含:
| 工作表 | 内容 |
| Content | 工作表目录 |
| Author Competitiveness | 作者-主题归一化竞争力矩阵 |
| Affiliation Competitiveness | 机构-主题归一化竞争力矩阵 |
| Country Competitiveness | 国家-主题归一化竞争力矩阵 |
| Author Raw Score | 作者-主题下论文原始贡献的累计值 |
| Affiliation Raw Score | 机构-主题下论文原始贡献的累计值 |
| Country Raw Score | 国家-主题下论文原始贡献的累计值 |
| Method | 指标公式、归一化方式和数据范围说明 |
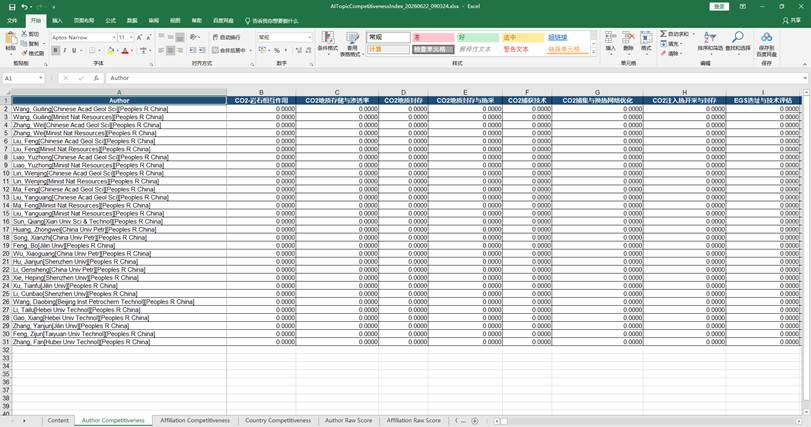
图7:AI主题竞争力指数 Excel
4. 生成 AI 主题竞争分布图
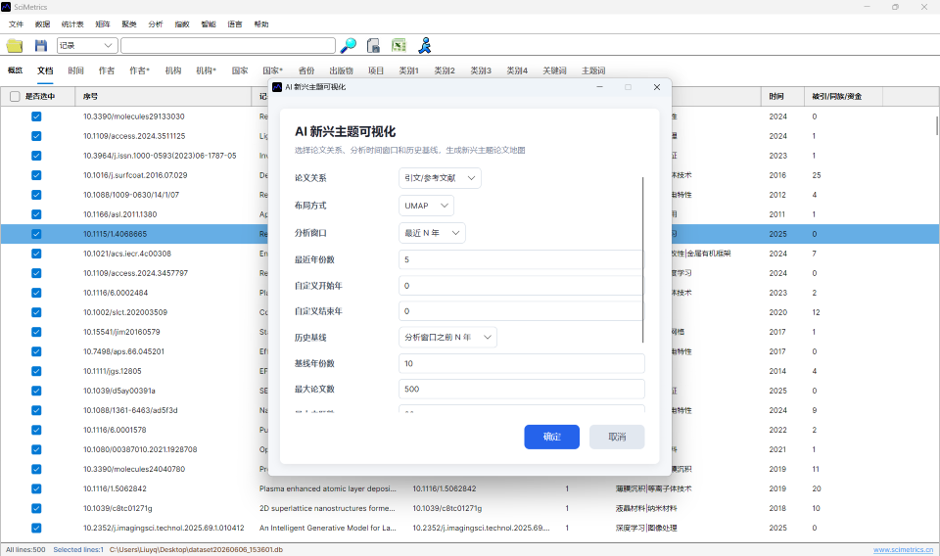
完成 AI 主题识别并确认主体数据后,进入:
AI → AI主题 → AI 主题竞争分布图
也可以在文献数据集的右键菜单中选择“AI 主题竞争分布图”。
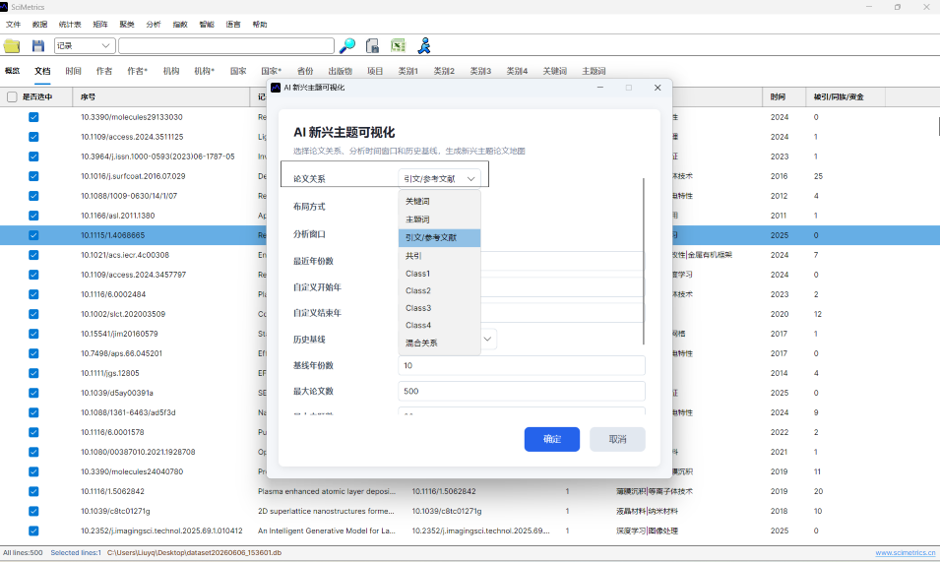
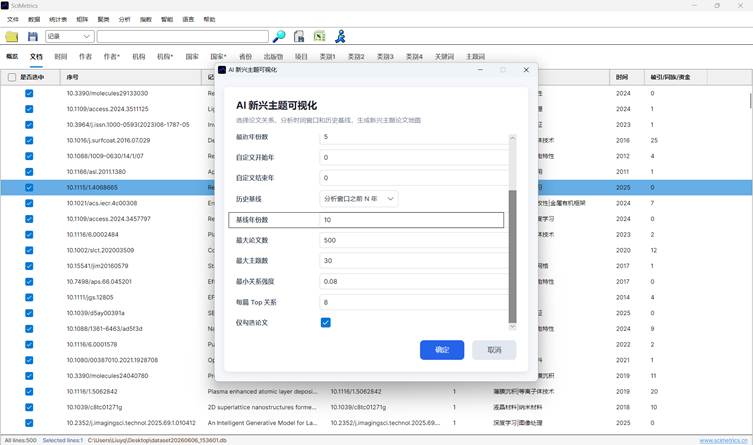
系统会弹出维度选择窗口,用于确定本次分布图以哪类主体作为竞争维度:
| 维度 | 适合问题 |
| 作者 | 哪些学者在不同 AI 主题中贡献突出 |
| 机构 | 哪些高校、科研院所或企业在不同主题中占优 |
| 国家 | 哪些国家或地区在不同 AI 主题中表现更强 |
窗口中同样提供“仅使用勾选文献”和“仅使用勾选主体”。确认后,系统会计算竞争力指数,并生成分布图模型。
图8:AI 主题竞争分布图` 菜单入口
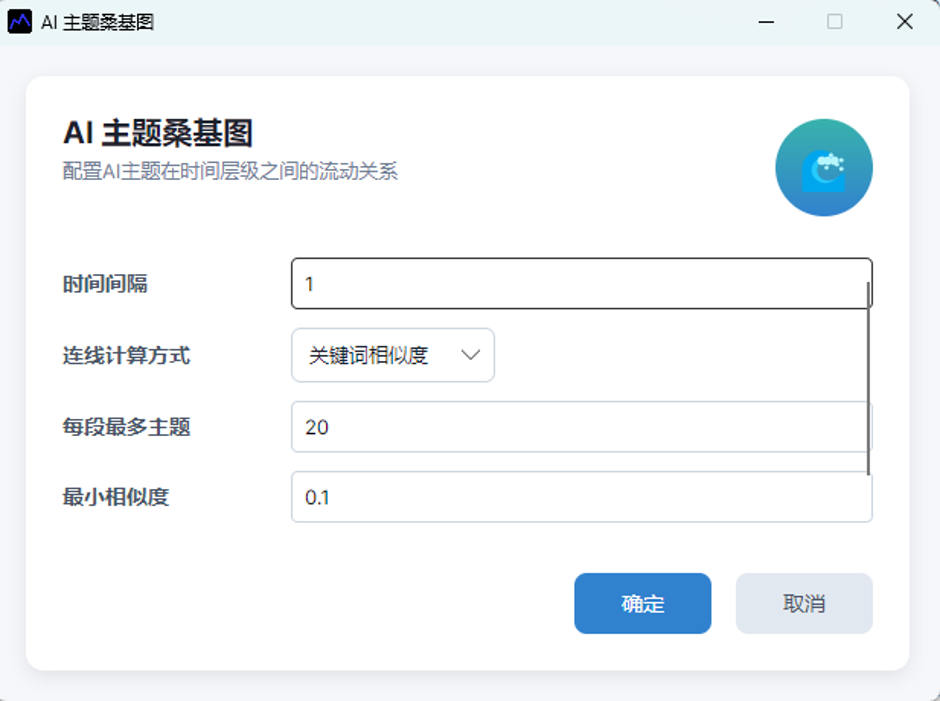
图9:AI 主题竞争分布图维度选择窗口
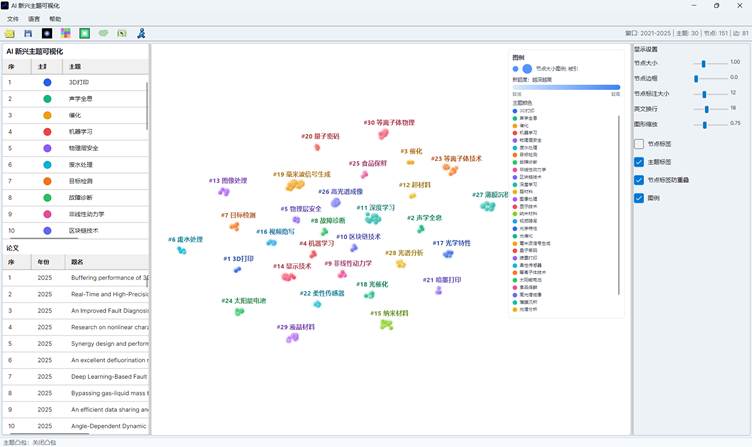
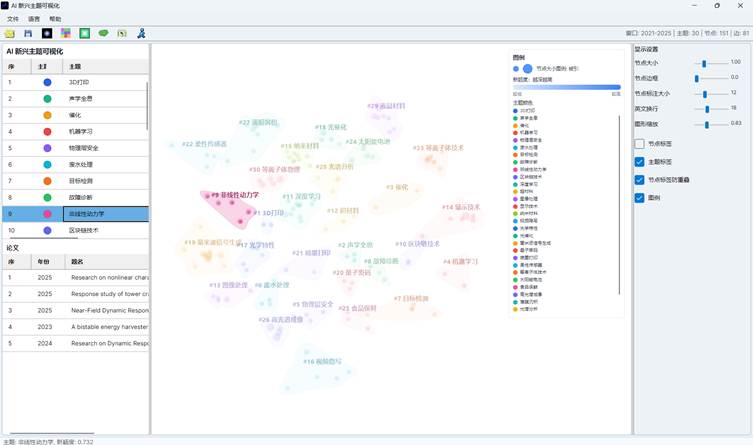
5. 认识分布图窗口
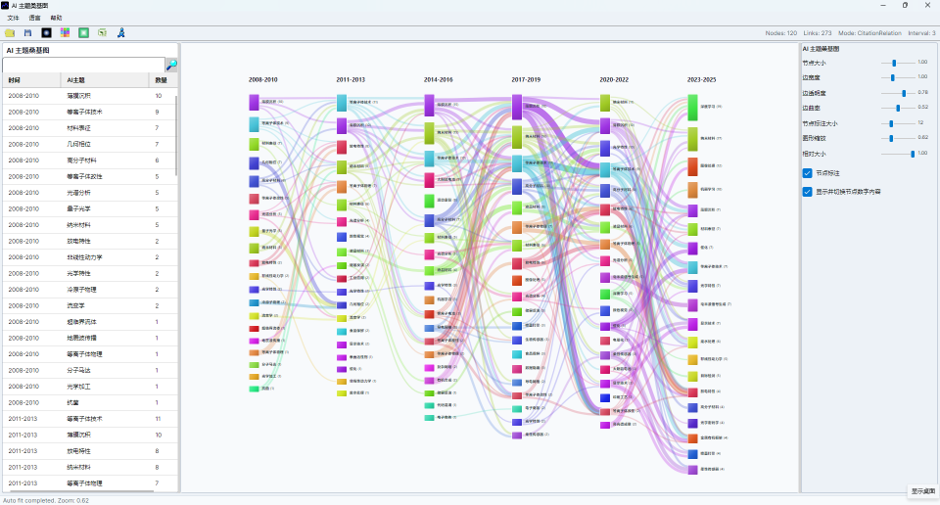
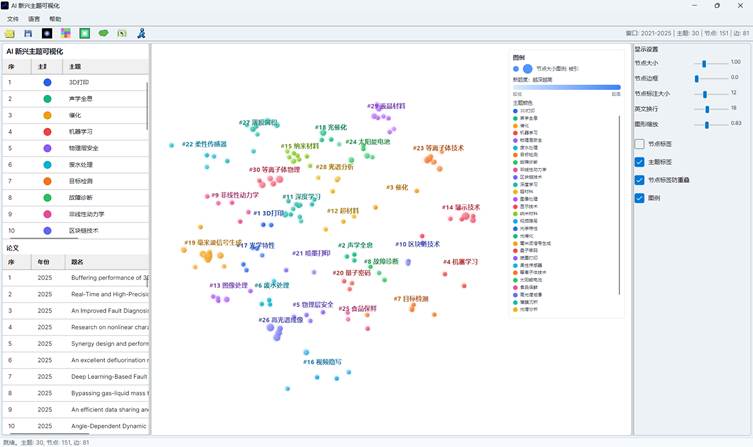
生成完成后会打开 AI 主题竞争分布图窗口。窗口主要分为五个区域:
| 区域 | 功能 |
| 顶部菜单 | 打开、保存、语言、帮助等 |
| 顶部工具栏 | 打开、保存、背景、重置、主题凸包、同主题选择、导出 Excel、退出 |
| 左侧主题与论文列表 | 查看主题竞争贡献、论文竞争贡献、论文数量和被引次数 |
| 中央可视化页签 | 在“分布图”“地形图”“热力矩阵”之间切换 |
| 右侧设置页签 | 分别调整分布图、地形图和热力矩阵参数 |
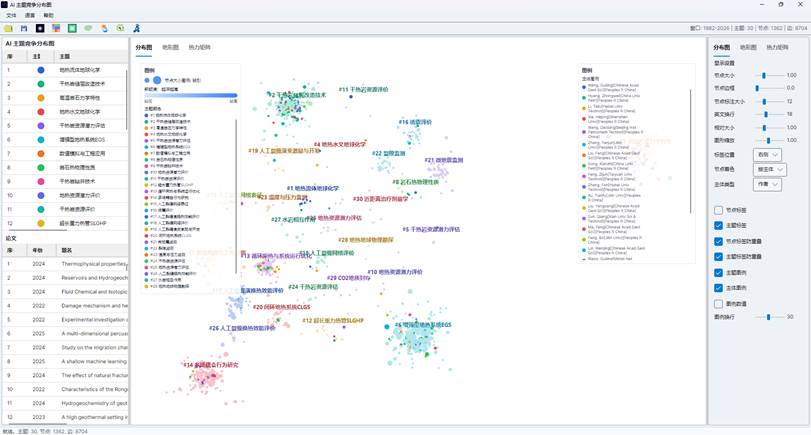
图10:AI 主题竞争分布图窗口
中央区域包含三个页签:
| 页签 | 说明 |
| 分布图 | 以论文为节点展示竞争贡献在主题空间中的分布 |
| 地形图 | 将主题竞争贡献转为山峰和地形表面 |
| 热力矩阵 | 以主体-主题矩阵补充展示竞争力数值 |
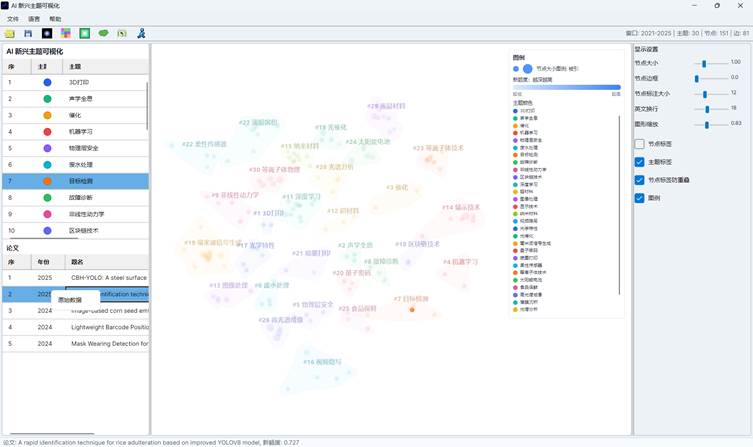
6. 阅读左侧主题列表和论文列表
左侧上半部分是主题列表。常见列包括:
| 列 | 含义 |
| 序号 | 主题在当前视图中的显示序号 |
| 主题样式 | 主题颜色和节点形状 |
| 主题 | AI 主题名称 |
| 竞争贡献 | 该主题归一化后的竞争贡献强度 |
| 论文 | 进入图中的论文数量 |
| 被引 | 该主题论文的总被引次数 |
点击某个主题后:
- 分布图会高亮该主题下的论文节点;
- 地形图会同步高亮相应主题;
- 论文列表会切换为该主题下的论文;
- 底部状态栏显示主题竞争贡献。
左侧下半部分是论文列表。常见列包括:
| 列 | 含义 |
| 序号 | 论文在当前列表中的排序 |
| 年份 | 论文发表年份 |
| 题名 | 论文题名 |
| 竞争贡献 | 该论文在所选维度下的竞争贡献 |
| 被引 | 论文被引次数 |
点击某篇论文后,分布图会高亮该论文及同主题论文组。
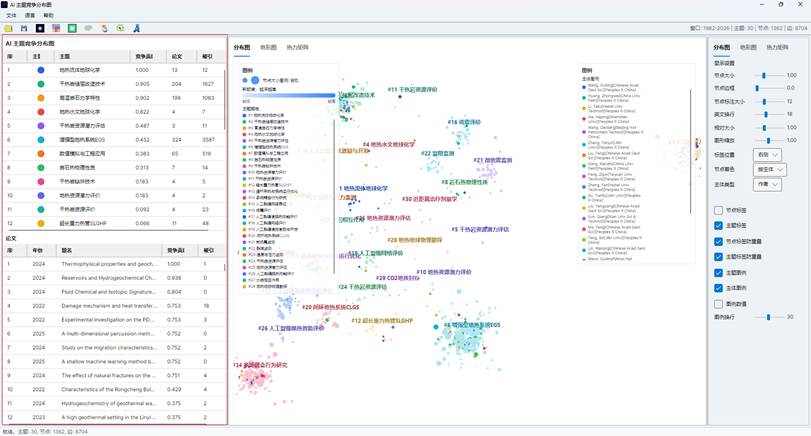
图11:AI 主题竞争分布图主题列表
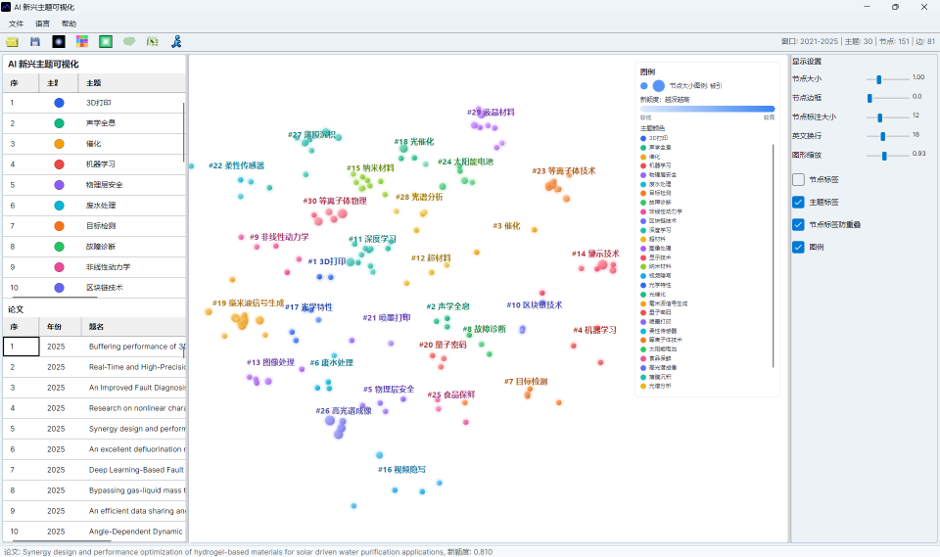
7. 阅读分布图视图
“分布图”页签是新版功能的核心视图。
基本含义如下:
| 图形元素 | 含义 |
| 论文节点 | 每个节点表示一篇进入模型的论文 |
| 节点大小 | 通常与被引次数相关,被引越高节点越大 |
| 节点颜色 | 可按竞争贡献着色,也可按作者、机构、国家主体着色 |
| 节点形状 | 用于区分主题,可自定义为圆形、方形、三角形、十字、菱形、星形 |
| 主题标签 | 显示主题编号和主题名称 |
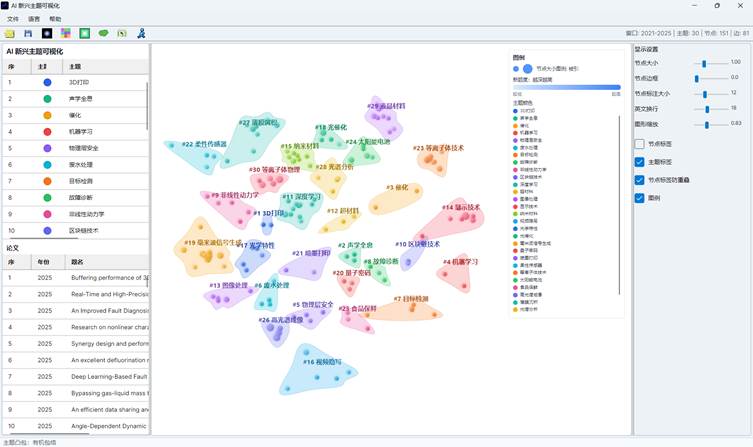
| 主题凸包 | 用半透明边界圈出同一主题论文的空间范围 |
| 图例 | 解释节点大小、竞争贡献颜色、主题颜色或主体颜色 |
图12:AI 主题竞争分布图可视化
7.1 分布图右侧设置
右侧“分布图”设置页签包含以下常用参数:
| 参数 | 作用 |
| 节点大小 | 整体放大或缩小论文节点 |
| 节点边框 | 调整论文节点边框粗细 |
| 主题文字大小 | 调整主题标签字号 |
| 英文换行长度 | 控制英文主题名称或图例文字的换行 |
| 大小差异 | 调整节点大小差异的明显程度 |
| 图形缩放 | 放大或缩小分布图 |
| 论文标签位置 | 控制论文标签显示在节点右侧、右上、上方或下方 |
| 节点着色 | 在“按竞争贡献”和“按主体”之间切换 |
| 主体类型 | 当按主体着色时,选择作者、机构或国家 |
| 论文标签 | 是否显示论文标签 |
| 主题标签 | 是否显示主题标签 |
| 避免标签重叠 | 自动减少论文标签重叠 |
| 主题图例 | 是否显示主题图例 |
| 主体图例 | 是否显示主体图例 |
| 图例数值 | 是否在图例中显示数量或贡献值 |
| 图例换行长度 | 控制图例文字换行 |
| 截图占位 18:分布图右侧设置面板,展示节点大小、节点着色、主体类型、标签和图例开关。 |
图13:AI 主题竞争分布图参数调整
7.2 节点着色方式
分布图支持两种主要着色方式:
| 着色方式 | 解释 | 适用场景 |
| 按竞争贡献 | 颜色深浅表示论文竞争贡献高低 | 查找高贡献论文和高贡献区域 |
| 按主体 | 根据作者、机构或国家给节点分配颜色 | 观察主体在主题空间中的分布 |
如果选择“按主体”,需要数据集中存在文献与作者、机构或国家的关联。若当前图文件没有原始主体映射数据,或所选主体数据不可用,系统会回退为按竞争贡献着色。
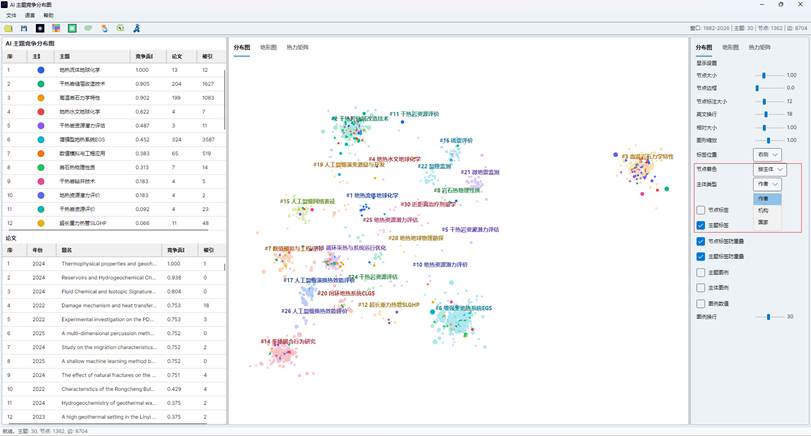
图14:AI 按竞争贡献着色的分布图
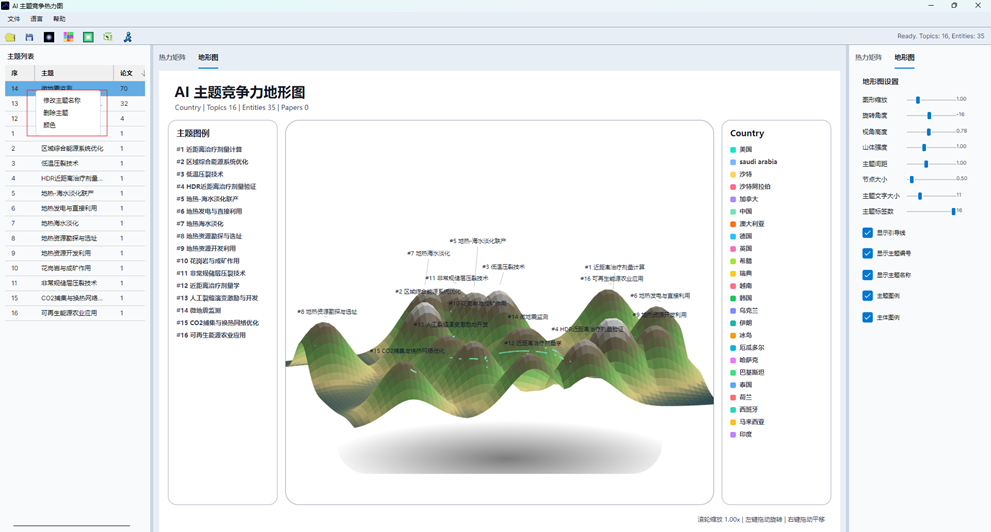
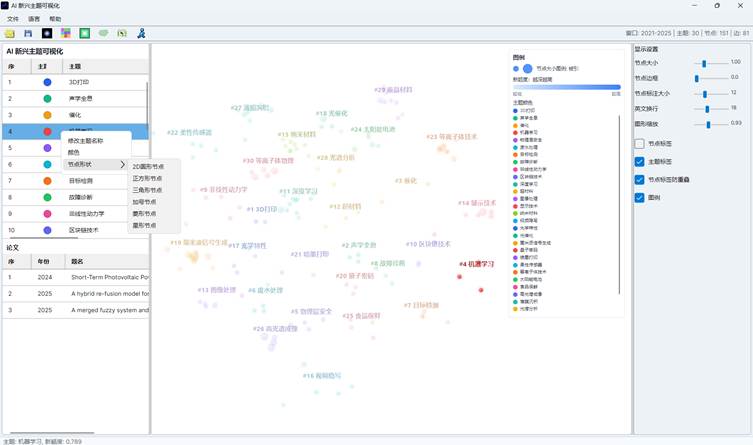
7.3 主题样式编辑
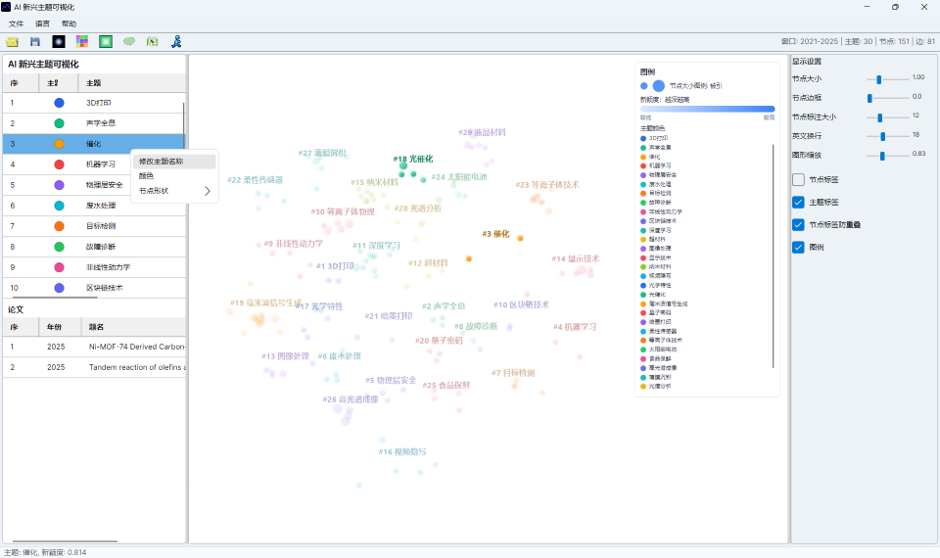
在左侧主题列表中右键某个主题,可以进行以下操作:
| 操作 | 作用 |
| 修改主题名称 | 修改当前分布图中的主题显示名称 |
| 删除主题 | 从当前视图中移除该主题及其论文节点和连线 |
| 颜色 | 修改该主题颜色 |
| 节点形状 | 设置该主题的节点形状 |
可选节点形状包括:
- 圆形;
- 方形;
- 三角形;
- 十字;
- 菱形;
- 星形。
这些设置会影响分布图中的节点显示,也会影响图例和保存后的图文件。
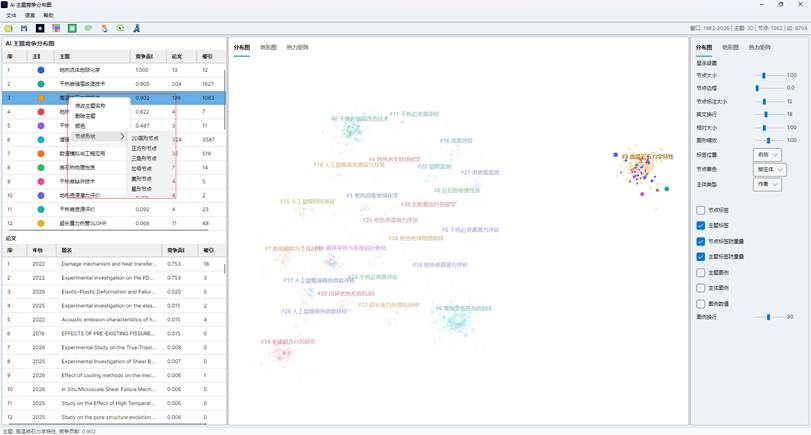
图15:AI 主题列表右键菜单
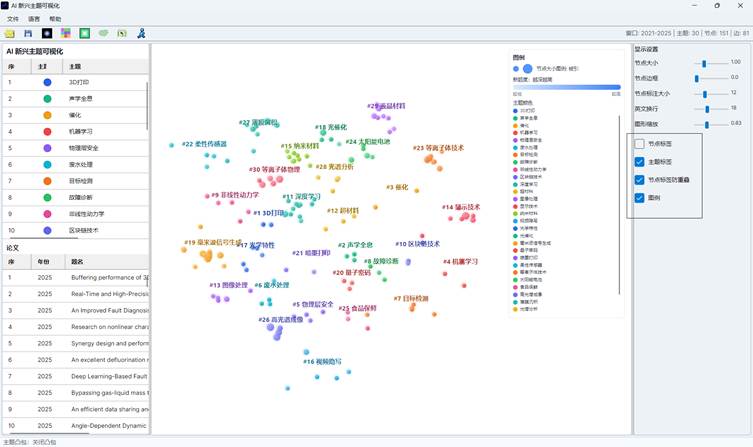
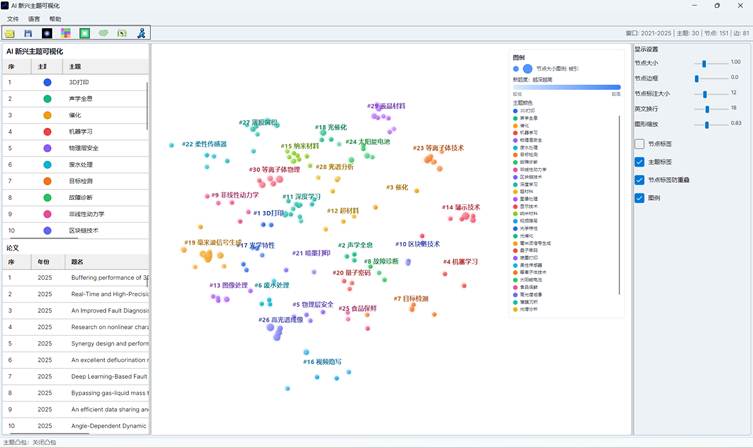
7.4 主题凸包
顶部工具栏中的“凸包”按钮用于切换主题范围显示。点击后会在三种模式之间循环:
| 模式 | 说明 |
| 无凸包 | 不显示主题边界 |
| 有机凸包 | 使用更贴合节点分布的柔和边界 |
| 凸包 | 使用较规整的几何边界 |
主题凸包适合在报告中展示不同主题在论文空间中的范围,但如果主题很多或节点过密,可以关闭凸包以减少遮挡。
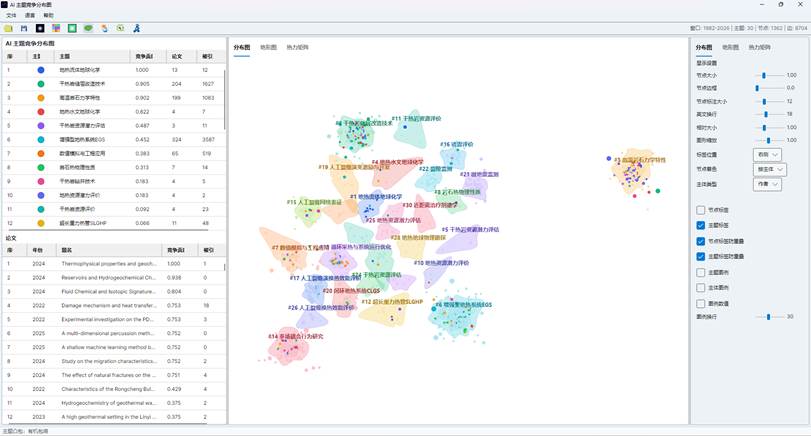
图16:AI主题分布凸包效果图
7.5 节点选择和拖动
分布图支持交互式调整:
| 操作 | 效果 |
| 鼠标滚轮 | 缩放分布图 |
| Shift + 左键拖动空白处 | 平移分布图 |
| 点击主题 | 高亮主题论文 |
| 点击论文 | 高亮论文及同主题论文组 |
| 顶部“选择同类节点” | 选中当前论文所在主题的全部节点 |
| 拖动选中节点 | 移动同主题节点组 |
| 拖动主题标签 | 手动调整主题标签位置 |
| 点击空白处 | 清除当前高亮 |
在制作报告图片时,可以先选中某个主题或论文,再微调节点组和主题标签,使图形更清晰。
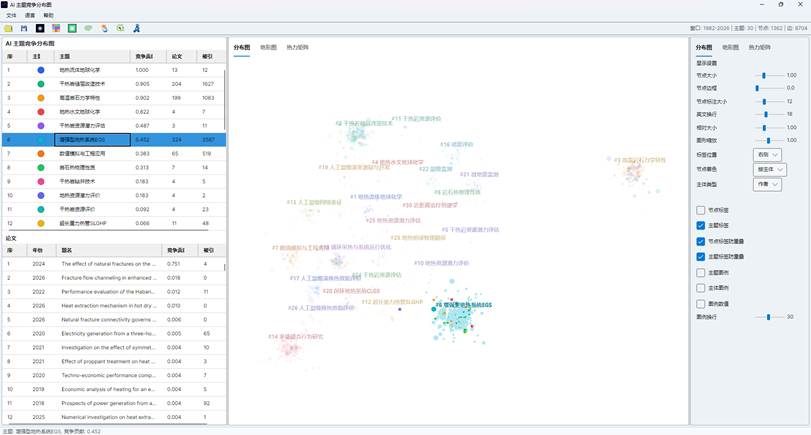
图17:AI主题节点高亮的效果
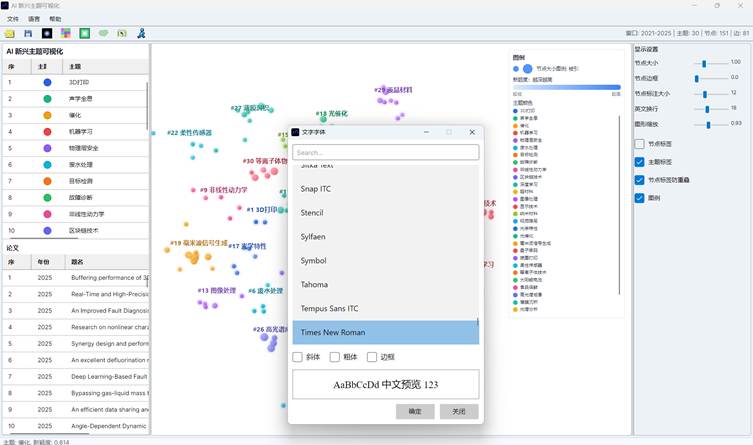
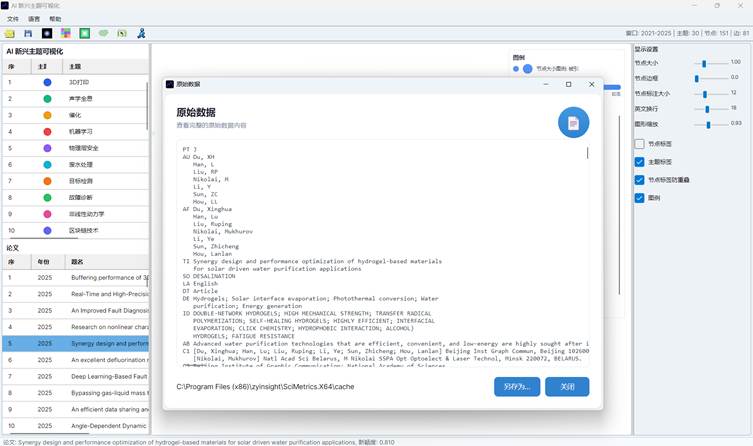
7.6 右键功能
分布图中可通过右键菜单进行补充操作:
| 位置 | 右键功能 |
| 主题标签或空白区域 | 设置主题字体 |
| 论文节点 | 查看原始数据 |
| 论文节点或空白区域 | 处理论文标签重叠 |
“查看原始数据”会尝试打开该论文在本地缓存中的原始记录,便于从可视化结果回到文献详情。
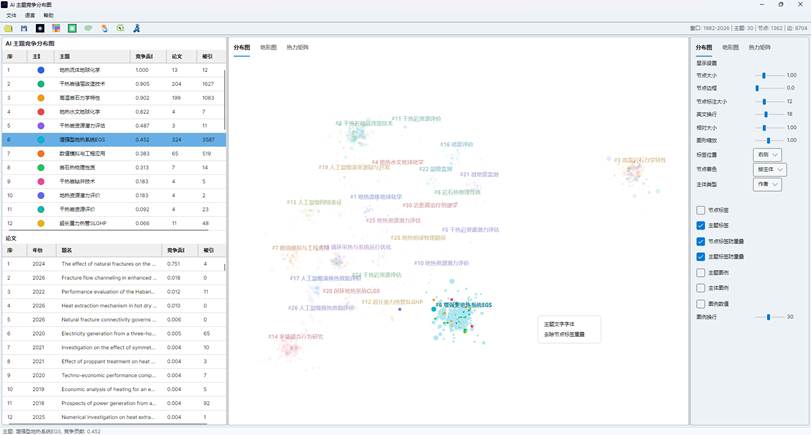
图18:分布图右键菜单修改字体
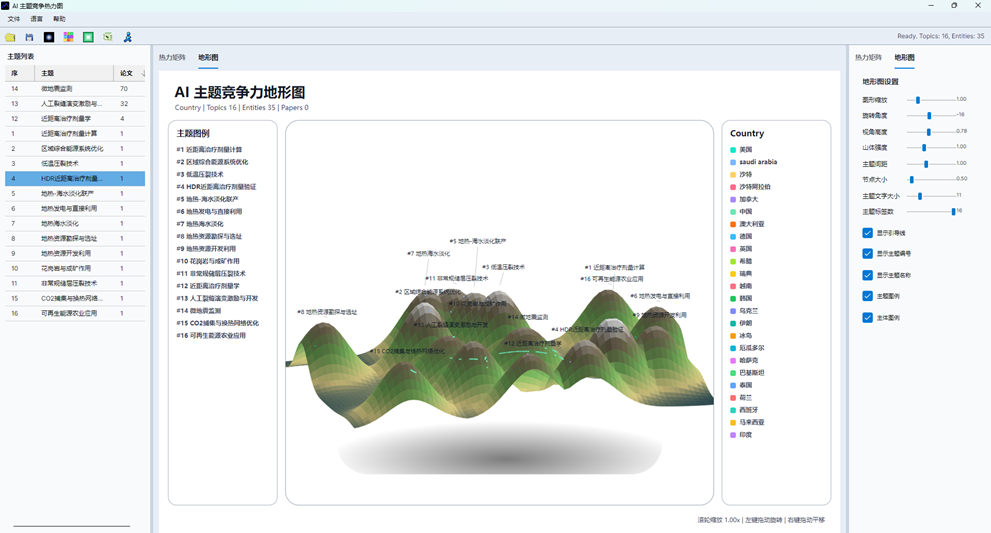
8. 阅读地形图视图
切换到“地形图”页签后,系统会把竞争分布图转换为三维地形表达。
地形图的基本含义:
| 图形元素 | 含义 |
| 山峰 | AI 主题 |
| 山峰高度 | 主题竞争贡献强度 |
| 山峰位置 | 来自分布图中的主题空间位置 |
| 点 | 主题内论文节点 |
| 点颜色 | 可按竞争贡献或主体着色 |
| 主题图例 | 展示主题名称、编号和贡献值 |
| 主体图例 | 展示作者、机构或国家颜色 |
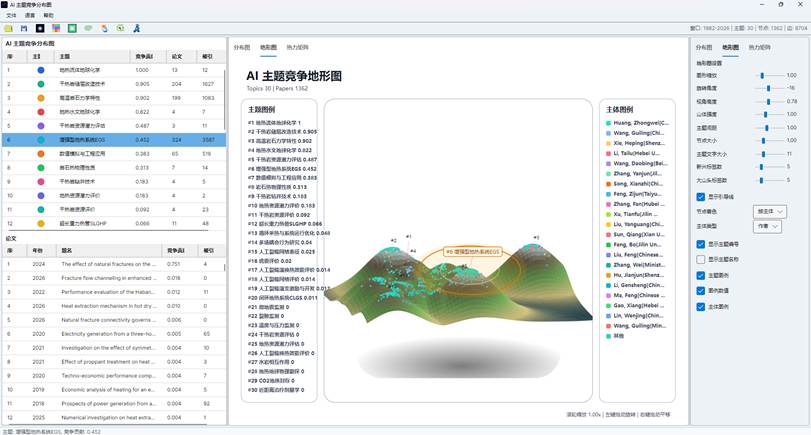
图19:AI主题地形图视图全景
8.1 地形图右侧设置
右侧“地形图”设置页签包含:
| 参数 | 作用 |
| 图形缩放 | 放大或缩小地形图 |
| 旋转角度 | 调整左右旋转视角 |
| 视角高度 | 调整俯视或平视角度 |
| 山体强度 | 调整山峰高度的视觉强弱 |
| 主题间距 | 调整主题山峰之间的距离 |
| 节点大小 | 调整地形图中的论文点大小 |
| 主题文字大小 | 调整地形图主题标签字号 |
| 高贡献标签数 | 控制显示多少个高竞争贡献主题标签 |
| 大山头标签数 | 控制显示多少个大规模主题标签 |
| 显示引导线 | 控制主题标签与山峰之间的引导线 |
| 节点着色 | 选择按竞争贡献或按主体着色 |
| 主体类型 | 选择作者、机构或国家 |
| 显示主题编号 | 是否在主题标签中显示编号 |
| 显示主题名称 | 是否在主题标签中显示名称 |
| 主题图例 | 是否显示主题图例 |
| 图例数值 | 是否显示贡献值或数量 |
| 主体图例 | 是否显示主体颜色图例 |
“高贡献标签数”用于控制地形图中显示多少个高竞争贡献主题标签。
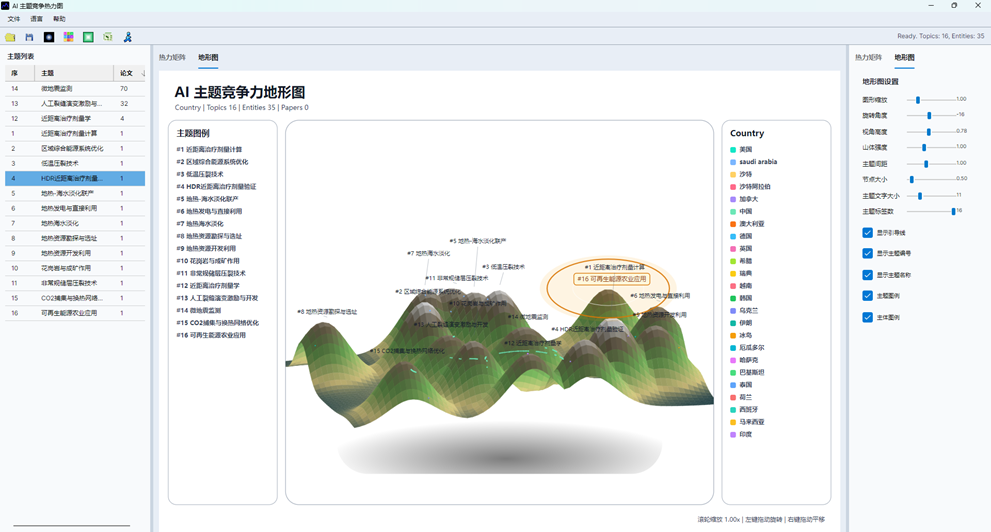
8.2 地形图交互
地形图支持以下鼠标操作:
| 操作 | 效果 |
| 鼠标滚轮 | 缩放地形图 |
| 左键拖动 | 旋转地形图 |
| 右键拖动 | 平移地形图 |
| 点击主题附近 | 高亮主题 |
| 右键空白处 | 打开主题文字字体设置 |
地形图适合用于展示整体竞争地貌,例如某个主题形成明显高峰、多个主题形成相邻峰群,或者某类主体在高贡献区域中分布集中。
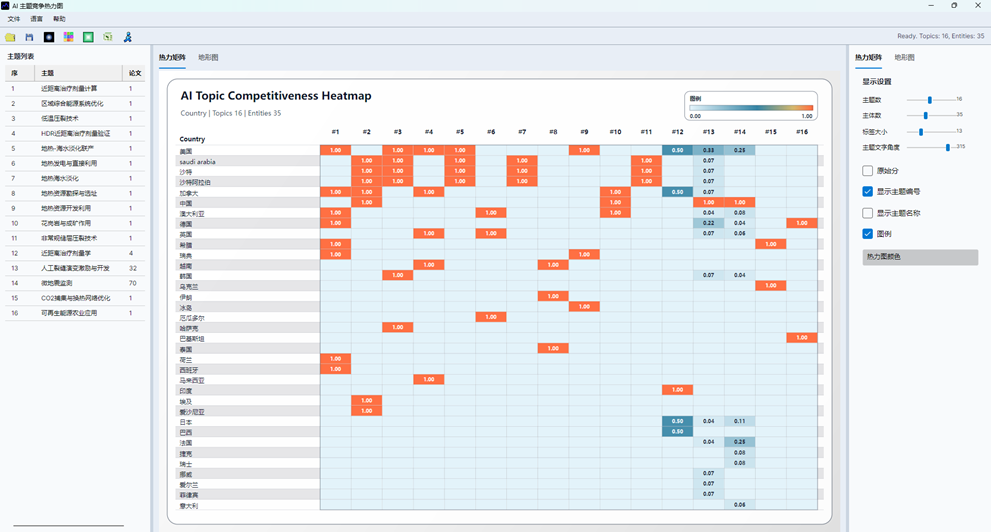
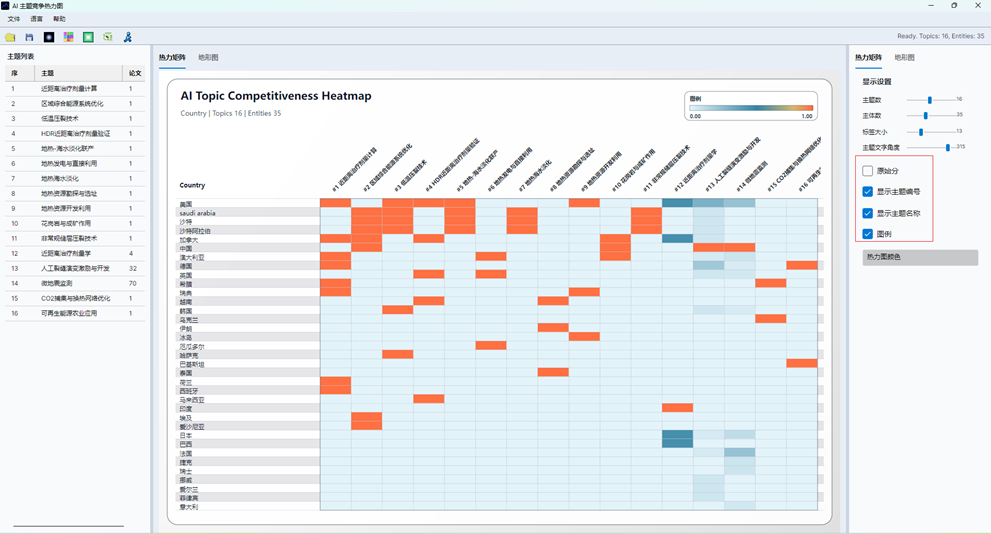
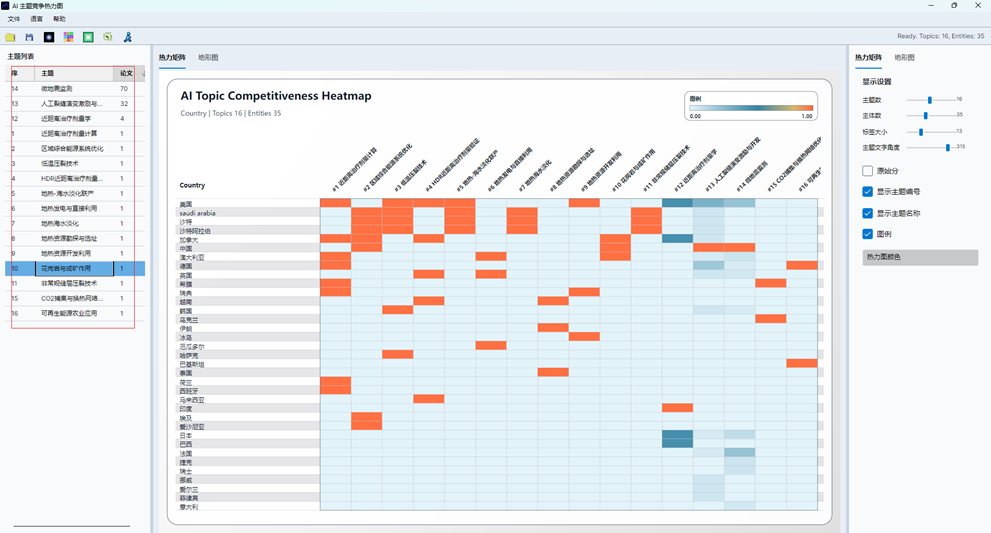
9. 阅读热力矩阵视图
“热力矩阵”页签用于补充展示主体-主题竞争力矩阵。它与旧的“AI 主题竞争热力图”功能有关,但在新版分布图窗口中作为辅助页签出现。
热力矩阵的基本含义:
| 元素 | 含义 |
| 行 | 作者、机构或国家主体 |
| 列 | AI 主题 |
| 单元格颜色 | 竞争力强弱 |
| 单元格数值 | 原始分数或归一化分数 |
| 主题编号 | 与主题列表和分布图主题对应 |
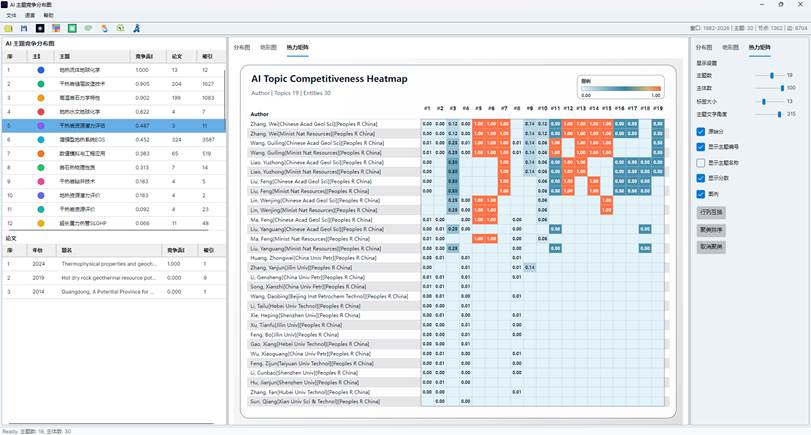
图20:AI主题分布热力图
右侧“热力矩阵”设置包括:
| 参数 | 作用 |
| 主题数 | 控制显示的主题数量 |
| 主体数 | 控制显示的主体数量 |
| 标签大小 | 调整行列文字字号 |
| 主题文字角度 | 调整主题列标签旋转角度 |
| 原始分数 | 在原始贡献和归一化竞争力之间切换 |
| 显示主题编号 | 是否显示主题编号 |
| 显示主题名称 | 是否显示主题名称 |
| 显示数值 | 是否在单元格中显示数值 |
| 图例 | 是否显示热力矩阵图例 |
| 交换行列 | 将主体和主题轴对调 |
| 矩阵聚类 | 根据竞争力模式重排行列,使相似主体或主题靠近 |
| 重置矩阵聚类 | 恢复原始排序 |
热力矩阵适合查看精确的主体-主题对应关系。若需要导出独立热力图 SVG,可继续使用旧的“AI 主题竞争热力图”功能;新版分布图窗口中的 SVG 保存主要导出分布图视图。
10. 背景、重置和语言
顶部工具栏提供常用全局操作:
| 按钮 | 作用 |
| 打开 | 打开 .topiccompetitionmap 文件 |
| 保存 | 保存 .topiccompetitionmap 或导出 SVG |
| 黑白背景 | 在黑色和白色背景之间切换 |
| 自定义背景 | 通过颜色选择器设置背景色 |
| 重置 | 恢复默认显示参数、视角、标签和背景 |
| 凸包 | 切换主题凸包模式 |
| 选择同类节点 | 选择当前论文同主题节点组 |
| Excel | 导出分布图数据 |
| 退出 | 关闭窗口 |
背景颜色会同步应用于分布图、地形图和热力矩阵。深色背景适合屏幕演示,浅色背景适合 Word、论文和打印材料。
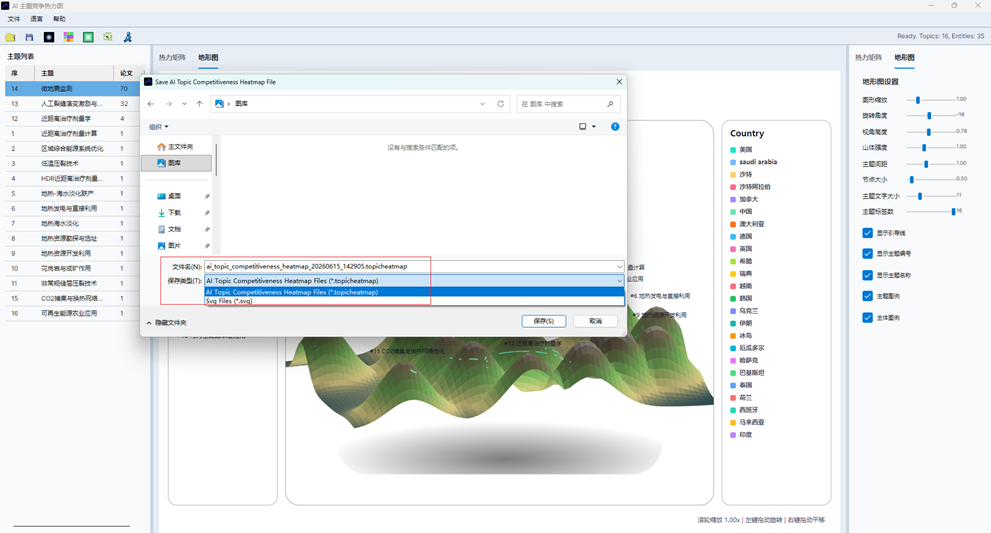
11. 保存、打开和导出
11.1 保存为 .topiccompetitionmap
在分布图窗口点击“保存”,选择 AI 主题竞争分布图文件格式时,系统会保存为:
*.topiccompetitionmap
该文件用于保存 AI 主题竞争分布图模型和显示样式。
保存内容包括:
- 论文节点、主题、连线和布局坐标;
- 主题颜色、节点形状和标签位置;
- 分布图显示设置;
- 背景颜色;
- 图例、标签、凸包等渲染设置。
需要注意:.topiccompetitionmap 主要保存分布图模型和样式。若单独打开该文件时没有原始数据集上下文,按主体着色和内嵌热力矩阵可能无法完整恢复,系统会回退到按竞争贡献着色,或隐藏热力矩阵页签。
11.2 打开 .topiccompetitionmap
可以从分布图窗口工具栏点击“打开”,也可以在主界面打开 .topiccompetitionmap 文件。打开后可继续查看分布图,并调整已有显示样式。
11.3 导出 SVG
在保存窗口中选择 SVG 文件格式时,系统会导出当前分布图模型的 SVG 图像。SVG 适合插入 Word、PPT、论文或继续在矢量软件中编辑。
说明:当前 SVG 导出由分布图视图完成,主要输出分布图画面。如果需要保存地形图或热力矩阵画面,建议使用截图工具;如果需要独立热力图 SVG,可使用“AI 主题竞争热力图”功能。
11.4 导出 Excel
点击顶部工具栏中的 Excel 按钮,可导出分布图数据。默认文件名类似:
ai_topic_competition_distribution_data_yyyyMMdd_HHmmss.xlsx
虽然文件名和部分字段沿用主题竞争分布图结构,但在 AI 主题竞争分布图中,CompetitionContribution 等字段实际表示竞争贡献。
Excel 中主要工作表包括:
| 工作表 | 内容 |
| Summary | 节点数、连线数、主题数等概要 |
| Topics | 主题竞争贡献、论文数、被引、坐标 |
| Papers | 论文竞争贡献、年份、被引、坐标 |
| Links | 论文间关系 |
| Settings | 分布图模型参数 |
12. 推荐工作流
建议按以下流程完成一次分析:
导入或打开数据集
→ 生成或检查 AI 主题
→ 检查作者、机构、国家数据
→ 需要时勾选文献和主体
→ 导出 AI 主题竞争力指数 Excel
→ 生成 AI 主题竞争分布图
→ 在分布图中查看高贡献论文和主体分布
→ 在地形图中观察主题竞争峰值
→ 在热力矩阵中核对主体-主题数值
→ 调整颜色、形状、标签、图例和背景
→ 保存 `.topiccompetitionmap`,导出 SVG、Excel 或截图
→ 将指数表、分布图、地形图和热力矩阵写入报告
二、原理说明
1. 数据基础
AI 主题竞争力指数和 AI 主题竞争分布图依赖同一批基础数据:
| 数据 | 作用 |
| 文献 | 竞争贡献的基本单位 |
| AI 主题 | 定义竞争的主题方向 |
| 被引次数 | 衡量文献在主题中的引用贡献 |
| 作者、机构、国家 | 竞争主体 |
| 文献-主体关系 | 将文献贡献分配给作者、机构或国家 |
| 关键词、主题词、引用、共引、分类 | 构建论文间关系和空间布局 |
系统优先读取专门的文献-主题关系表;如果没有,则从文献表中的 AI 主题字段读取主题,并按分隔符拆分多主题。
2. AI 主题竞争力指数原理
AI 主题竞争力指数的目标,是计算某个主体在某个 AI 主题中的相对竞争贡献。
设:
- d 表示一篇文献;
- t 表示一个 AI 主题;
- e 表示一个主体,可以是作者、机构或国家;
- T(d) 表示文献 d 所属的 AI 主题集合;
- Citation(d) 表示文献 d 的被引次数。
2.1 主题分摊
如果一篇文献属于多个 AI 主题,系统会按主题数量平均分摊:
TopicWeight(d,t) = 1 / |T(d)|
这样可以避免多主题文献在每个主题中都被重复计为完整贡献。
2.2 引用平滑
当前默认使用引用平滑:
CitationWeight(d) = Citation(d) + 1
这样零被引文献仍然可以贡献少量权重,不会在计算中完全消失。
2.3 主题内归一分母
对每个主题 t,系统计算该主题下所有文献的平滑引用总量:
TopicCitationTotal(t) = sum(Citation(i) + 1), i 属于主题 t
2.4 文献对主题的贡献
一篇文献 d 对主题 t 的贡献为:
Contribution(d,t) = 1 / |T(d)| * (Citation(d) + 1) / TopicCitationTotal(t)
如果关闭引用平滑,则公式中的 Citation(d) + 1 会改为 Citation(d)。
2.5 主体原始分数
如果主体 e 与文献 d 存在关联,并且文献 d 属于主题 t,则该文献贡献会计入主体 e 在主题 t 下的原始分数:
RawScore(e,t) = sum Contribution(d,t)
当前实现不按同一文献中的作者数、机构数或国家数再次分摊。也就是说,只要某作者、机构或国家参与了该文献,该主体在对应维度中会获得该文献对主题的完整贡献。
2.6 按主题归一化
为了比较同一主题下不同主体的竞争力,系统对每个主题独立归一化:
TCI(e,t) = RawScore(e,t) / max_e RawScore(e,t)
归一化后,每个主题中最高主体的竞争力为 1,其余主体介于 0 到 1 之间。
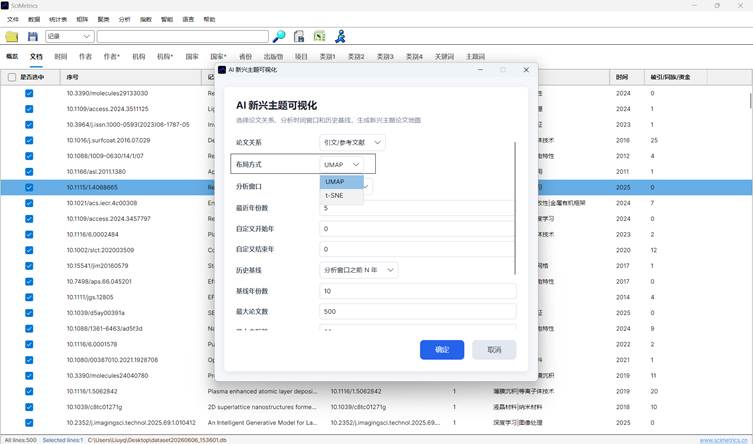
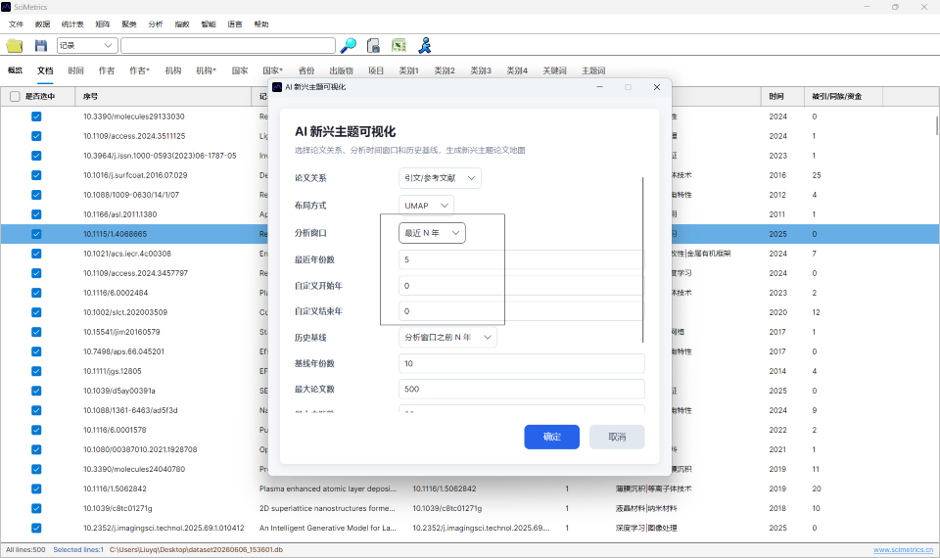
3. 分布图生成原理
AI 主题竞争分布图基于论文关系布局和竞争贡献计算,把论文、主题和主体映射到同一个可视空间中。
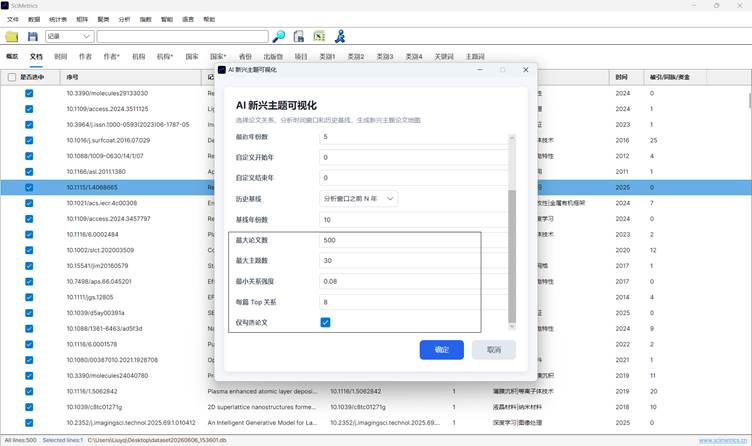
当前分布图模型的主要参数为:
| 参数 | 当前实现 |
| 论文关系 | 混合关系 |
| 布局方式 | UMAP |
| 分析年份 | 全部年份 |
| 历史基线 | 不使用历史基线 |
| 最大论文数 | 用户设定 |
| 最大主题数 | 用户设定 |
| 最小关系强度 | 0.08 |
| 每篇论文保留关系 | Top 8 |
系统先根据关键词、主题词、引用、共引和分类等信息构建论文间混合关系,再用 UMAP 将论文投影到二维空间。随后,系统计算论文与主题的竞争贡献,并写入分布图模型:
| 数据项 | 含义 |
| 论文竞争贡献 | 论文在其主题中的归一化贡献强度 |
| 论文归一化贡献 | 论文在其主题中的归一化贡献强度 |
| 论文原始贡献 | 按引用和主题归属累计得到的原始贡献 |
| 论文原始贡献 | 按引用和主题归属累计得到的原始贡献 |
| 主题竞争贡献 | 同一主题内论文贡献的综合结果 |
| 主题原始贡献 | 主题下论文原始贡献的累计值 |
因此,在导出的分布图数据 Excel 中,如果看到 CompetitionContribution,应按“竞争贡献”解释,而不是按“竞争贡献”解释。
4. 分布图可视化原理
分布图把论文、主题和主体映射到同一个二维画面:
| 可视化编码 | 数据含义 |
| 节点位置 | 论文间混合关系布局结果 |
| 节点大小 | 论文被引次数 |
| 节点颜色 | 竞争贡献或主体类别 |
| 节点形状 | 主题样式 |
| 主题标签位置 | 主题论文的空间中心,可手动微调 |
| 主题凸包 | 同一主题论文的空间边界 |
| 图例 | 解释节点大小、主题颜色、主体颜色和贡献强度 |
分布图主要用于观察“竞争贡献在论文空间中的分布”。距离越近的论文,通常表示它们在混合关系中更接近;但二维布局是降维结果,不宜把任意两点之间的距离解释为精确数值。
5. 地形图生成原理
地形图把分布图中的主题空间进一步转化为地形表达。
5.1 主题位置
主题山峰的位置来自分布图中的主题位置。竞争结构相近、论文空间接近的主题,在地形图中也更容易靠近。
5.2 山峰高度
山峰高度主要反映主题竞争贡献。竞争贡献越高,山峰越明显。右侧“山体强度”可以改变高度的视觉表现,但不改变原始数据。
5.3 论文点颜色
地形图中的论文点可按两种方式着色:
| 着色方式 | 解释 |
| 按竞争贡献 | 点颜色表示论文竞争贡献高低 |
| 按主体 | 点颜色表示作者、机构或国家主体 |
按主体着色依赖原始数据集中的文献-主体映射。如果映射不可用,系统会提示数据不可用,并回退到按竞争贡献着色。
5.4 标签选择
地形图中的标签有两类:
| 标签类型 | 含义 |
| 高贡献标签 | 优先显示竞争贡献较高的主题 |
| 大山头标签 | 优先显示论文规模较大或峰体显著的主题 |
二者结合使用,可以同时看见“贡献高的主题”和“规模大的主题”。
6. 热力矩阵原理
热力矩阵从同一次竞争力计算结果中提取主体-主题矩阵。
可显示两种数值:
| 数值 | 含义 |
| 原始分数 | 主体在主题中的累计原始贡献 |
| 归一化分数 | 同一主题内按最高主体归一化后的竞争力 |
矩阵聚类会根据行列的竞争力模式重新排序,使相似主体或相似主题更靠近。聚类只改变显示顺序,不改变计算结果。
7. 文件格式与导出原理
7.1 指数 Excel
指数 Excel 是最适合做精确数值分析的结果文件。其标准矩阵包括作者、机构和国家三个维度,并保留归一化分数与原始分数。
7.2 .topiccompetitionmap
.topiccompetitionmap 是分布图模型文件。它保存节点、主题、连线、布局和显示样式,适合后续重新打开继续调整图形。
由于文件结构沿用 AI 主题竞争分布图,文件名和部分字段可能出现 competition 或 contribution 字样。在 AI 主题竞争分布图中,应根据窗口标题和本手册说明,将这些字段解释为竞争分布图模型和竞争贡献。
7.3 SVG
SVG 导出主要面向分布图视图,适合报告和排版。如果要保存地形图或热力矩阵,可使用截图工具;如果要导出独立热力图 SVG,可使用“AI 主题竞争热力图”功能。
7.4 分布图数据 Excel
分布图数据 Excel 导出的是图模型数据,包括 Topics、Papers、Links 和 Settings。它适合复核图中节点、主题、坐标和贡献值,但不等同于完整的 AI 主题竞争力指数 Excel。
8. 结果解读建议
8.1 用指数表做精确判断
如果需要判断“哪个主体在某个主题上最强”,应优先查看 AI 主题竞争力指数 Excel。归一化分数适合主题内比较,原始分数适合观察累计贡献规模。
8.2 用分布图观察高贡献论文和主体分布
分布图适合发现:
- 高贡献论文是否集中在少数主题区域;
- 某些主体是否覆盖多个主题;
- 同一主体是否在高贡献区域形成连续分布;
- 某些主题是否存在明显的核心论文群。
8.3 用地形图观察整体竞争地貌
地形图适合展示宏观格局:
- 哪些主题形成竞争高峰;
- 高峰之间是否相互靠近;
- 哪些主题规模较大但贡献不一定最高;
- 哪些主体颜色集中在高峰区域。
8.4 用热力矩阵核对主体-主题关系
热力矩阵适合回答:
- 某个主体在哪些主题上更强;
- 某个主题下有哪些主体竞争力突出;
- 不同主体的优势主题是否相似;
- 聚类后是否出现相近竞争模式的主体群。
9. 常见问题
9.1 为什么生成不了 AI 主题竞争分布图?
常见原因包括:
- 尚未生成 AI 主题;
- 文献没有年份或被引次数;
- 所选维度缺少作者、机构或国家数据;
- 勾选了“仅使用勾选文献”但没有勾选文献;
- 勾选了“仅使用勾选主体”但没有勾选对应主体。
9.2 为什么按主体着色不可用?
按主体着色需要原始数据集中存在文献与作者、机构或国家的映射。如果打开的是单独保存的 .topiccompetitionmap 文件,原始主体映射可能不可用,系统会回退为按竞争贡献着色。
9.3 为什么热力矩阵和分布图的数值显示不完全一样?
分布图中的论文和主题竞争贡献用于展示论文空间与主题峰值;热力矩阵展示主体-主题矩阵。二者来自同一竞争力思想,但展示对象不同:分布图强调论文和主题,热力矩阵强调主体和主题。
9.4 为什么 SVG 不是地形图或热力矩阵?
当前分布图窗口的 SVG 导出主要输出分布图视图。地形图和热力矩阵建议使用截图保存,或使用独立热力图功能导出热力图 SVG。
9.5 主题名称、颜色和形状修改后会影响原始数据吗?
在分布图窗口中修改主题名称、颜色、形状或删除主题,主要影响当前可视化模型和保存的图文件,不建议将其理解为对原始数据集的全面回写。若要长期修订 AI 主题,建议回到数据集中的 AI 主题编辑功能处理。
10. 使用建议
- 做正式报告前,先导出 AI 主题竞争力指数 Excel,保留可复核数据。
- 分布图中优先使用“按竞争贡献”查找高贡献区域,再切换“按主体”观察主体分布。
- 主题很多时,关闭论文标签,只保留主题标签和图例。
- 做展示图时,可使用主题凸包、主题形状和主体图例增强可读性。
- 地形图适合呈现宏观格局,热力矩阵适合支撑精确比较。
- 保存 .topiccompetitionmap 作为可编辑图文件,同时导出 SVG 或截图用于报告。