本手册面向高校图书馆学科服务场景,说明如何使用 SciMetrics 的 AI 作者映射功能,基于学校、学院或科研团队花名册,将文献数据库中的作者记录精准映射到本校教师,从而支持教师科研成果梳理、学科画像、学院成果统计和论文认领核验。
说明:本功能适用于“作者”和“通讯作者”两类对象。界面中可能显示为“AI 作者映射”或“AI 通讯作者映射”。
一、操作方法
1. 典型应用场景
高校图书馆在开展学科服务时,常常需要回答以下问题:
1. 某学院、某学科、某团队的老师近年发表了哪些论文?
2. 学校花名册中的教师,哪些可以在 WoS、Scopus、CNKI 等文献数据中精准定位?
3. 同名作者、英文缩写作者、拼音作者如何归并到校内真实教师?
4. 如何区分本校教师成果和校外同名作者成果?
5. 如何统计某教师、某学院或某岗位类型的论文成果、引用表现和合作网络?
AI 作者映射的核心用途,是把文献作者表中的原始作者写法,映射到用户提供的花名册标准写法。例如:
| 文献中的作者写法 | 花名册中的教师记录 | 映射结果 |
| Wang, Q. | 计算机学院-王强 | 计算机学院-王强 |
| Chen Qiang | 图书馆学系-陈强 | 图书馆学系-陈强 |
| Li, B.[School of Packaging] | 包装学院-李彪 | 包装学院-李彪 |
| Wang Q. | 计算机学院-王强、材料学院-王清 | `计算机学院-王强 |
图1:高校图书馆学科服务中使用教师花名册匹配论文成果的示意图
2. 使用前准备
使用 AI 作者映射前,建议准备三类数据:
| 数据 | 说明 |
| 文献数据 | 从 WoS、Scopus、CNKI、万方、PubMed 等来源导入的论文数据。 |
| 作者或通讯作者表 | 软件读取文献后自动生成的作者表、通讯作者表。 |
| 单位花名册 | 学校、学院、学科或团队的教师名单,每行一位教师。 |
花名册建议包含尽可能多的辅助信息,尤其是学院、部门、单位、岗位或学科方向。推荐格式:
计算机学院-王强
材料科学与工程学院-李娜
图书情报学院-陈强
包装学院-李彪
医学部-王琦
准备花名册时建议遵循以下原则:
1. 每行只放一位教师。
2. 同一个教师使用一种标准写法。
3. 学院或部门名称尽量完整。
4. 同名教师必须加上学院、部门或其他辅助信息。
5. 离职、退休、附属医院、兼职教师是否纳入,应先由图书馆或业务部门确定口径。
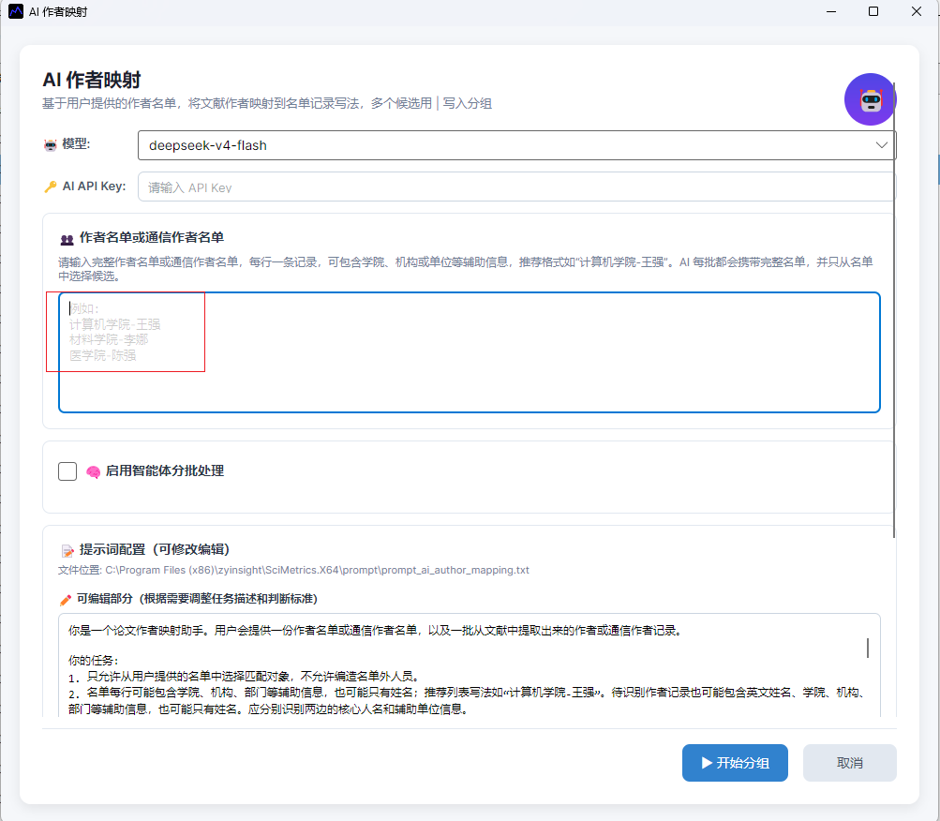
图2:学校教师花名册示例
3. 导入文献数据并确认作者表
操作步骤:
1. 打开软件,导入需要分析的文献数据。
2. 数据读取完成后,在数据表区域查看 作者 表和 通讯作者 表。
3. 检查作者记录是否包含英文姓名、拼音姓名、缩写姓名、机构信息等内容。
4. 按业务需要勾选需要处理的作者记录。
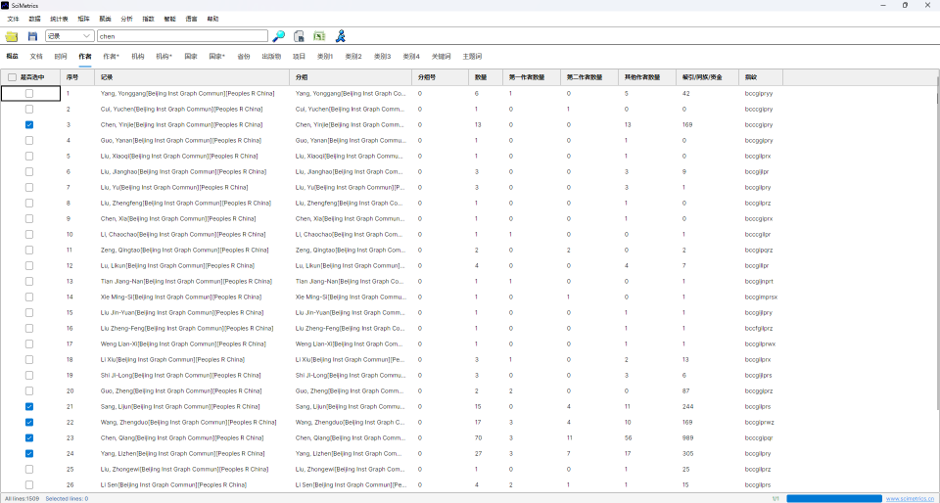
图3:作者表中显示英文缩写、拼音和机构信息的作者记录
说明:
- 如果要统计全部参与作者成果,可在 作者 表中使用 AI 作者映射。
- 如果只关注通讯作者成果,可在 通讯作者 表中使用 AI 通讯作者映射。
- 如果只处理本校成果,建议先通过机构、国家、省份或检索条件筛选出相关文献,再进行作者映射。
4. 选择要映射的作者记录
AI 作者映射只处理当前选中的作者记录。使用前需要先在作者表或通讯作者表中选择记录。
操作步骤:
1. 打开 作者 表或 通讯作者 表。
2. 勾选或选中需要映射的作者记录。
3. 对于初次使用,建议先选择几十条记录进行测试。
4. 测试结果符合预期后,再扩大到学院、学科或全校范围。
图4:智能体批量处理
建议:
- 首次运行可先选择同一学院或同一学科的作者,便于检查结果。
- 如果作者数量较多,建议启用智能体分批处理。
- 如果同名作者较多,花名册中一定要保留学院或部门信息。
5. 打开 AI 作者映射功能
有两种常用入口。
入口一:主菜单
1. 进入 智能 -> AI分组 -> AI 作者映射。
2. 如果当前处理的是通讯作者,进入 智能 -> AI分组 -> AI 通讯作者映射。
入口二:右键菜单
1. 在 作者 表中选中记录。
2. 右键打开菜单,选择 AI 作者映射。
3. 在 通讯作者 表中右键时,选择 AI 通讯作者映射。
图5:主菜单中的 智能 -> AI分组 -> AI 作者映射 入口
图6:作者表右键菜单中的 AI 作者映射 入口
6. 配置 AI 作者映射参数
打开功能后,会出现 AI 设置窗口。主要配置项包括模型、API Key、作者名单、分批处理和提示词。
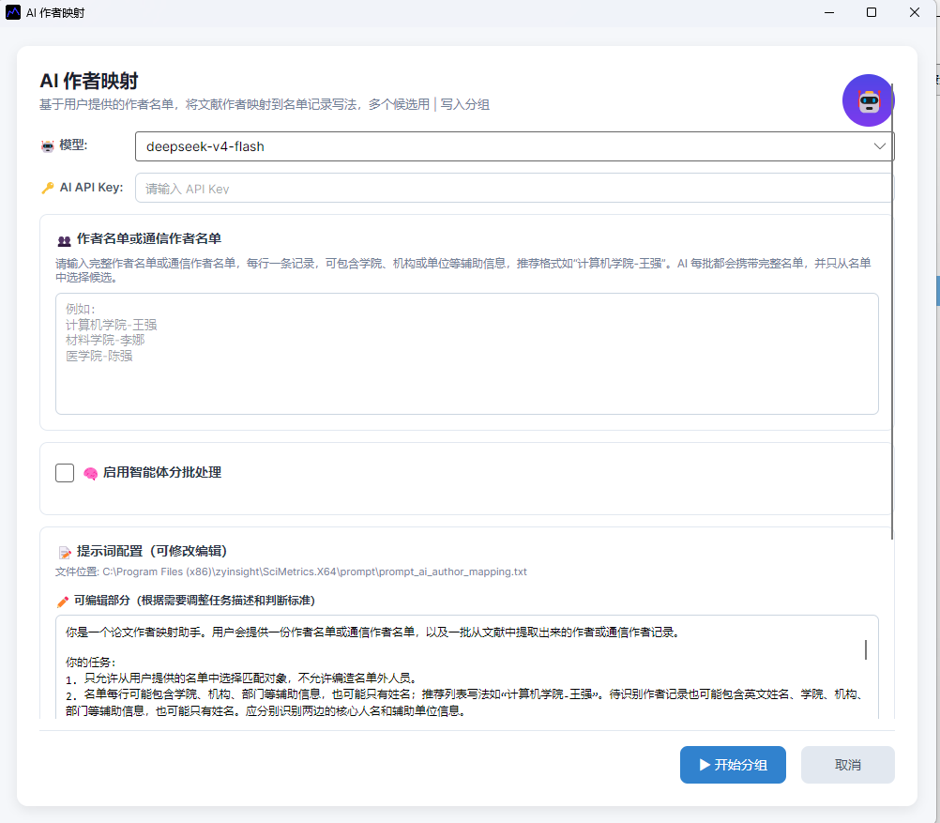
图7:AI 作者映射设置窗口
参数说明:
| 参数 | 说明 |
| 模型 | 选择用于作者映射的 AI 模型。 |
| API Key | 输入模型调用所需的密钥。 |
| 作者/通讯作者名单 | 粘贴学校、学院或团队花名册。AI 只会从这份名单中选择结果。 |
| 启用分批处理 | 当选中作者较多时,建议启用。 |
| 每批数量 | 每次提交给 AI 的作者记录数,默认一般为 100。 |
| 提示词配置 | 映射规则说明,通常不需要修改。 |
操作步骤:
1. 在 模型 中选择已配置的 AI 模型。
2. 填写或确认 API Key。
3. 将单位花名册粘贴到 作者/通讯作者名单 输入框。
4. 作者数量较多时勾选 启用分批处理。
5. 设置每批数量,建议从 50 到 100 开始。
6. 点击确定,开始映射。
7. 查看映射结果
映射完成后,软件会把结果写回作者表或通讯作者表。
关键字段:
| 字段 | 含义 |
| Record | 文献数据中提取的原始作者写法。 |
| Group | AI 映射后的花名册标准写法。 |
| GroupId | 映射标记,通常包含 AuthorMap、判断类型和模型名称。 |
| ParId | 分组父级信息,作者映射时一般置为 0。 |
映射结果示例:
| Record | Group | GroupId |
| Wang, Q. | 计算机学院-王强 | AuthorMap[Matched][模型名] |
| Chen, Q.[Beijing Inst Graph Commun] | 图书情报学院-陈强 | AuthorMap[Matched][模型名] |
| Wang Q. | `计算机学院-王强 | 材料学院-王清` |
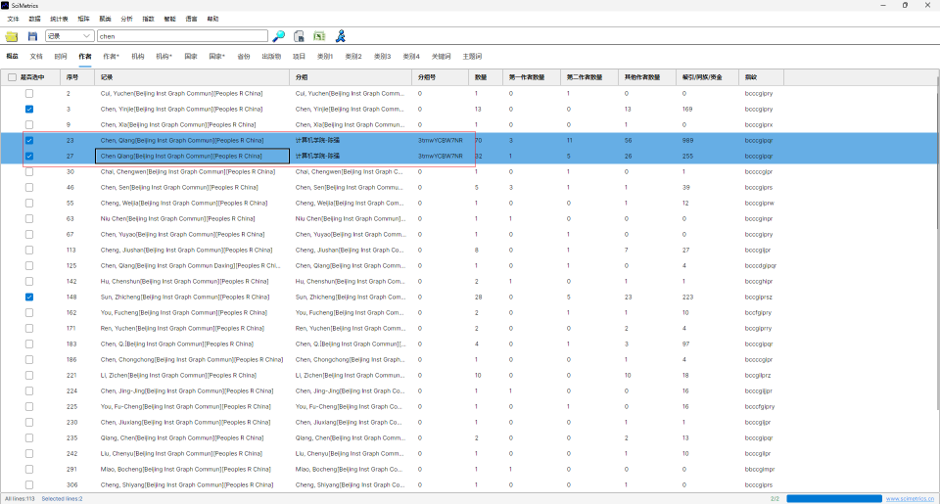
图8:作者表中 Group 字段写入映射结果
结果类型说明:
| 类型 | 含义 | 处理建议 |
| Matched | AI 判断可以唯一匹配到花名册中的某位教师。 | 可作为初步可信结果,建议抽样核验。 |
| Ambiguous | AI 判断可能对应多位教师,结果用 ` | ` 分隔。 |
| Unmatched | 无法在花名册中找到合理候选。 | 不写入 Group,可补充花名册或人工复核。 |
8. 利用映射结果定位教师论文成果
作者映射完成后,可以用 Group 字段把文献作者统一到校内教师身份,从而开展成果统计。
常见操作:
1. 在作者表中搜索某位教师的标准写法,如 计算机学院-王强。
2. 使用“查看相关”功能定位该教师关联的文献。
3. 导出数据表或统计表,形成教师成果清单。
4. 按学院、学科或团队字段汇总教师论文数量、期刊、年份、合作机构等。
5. 对通讯作者映射结果单独统计,用于分析本校主导成果。
图9:截图占位:通过 Group 字段搜索某位教师
图10:查看某位教师关联论文列表
高校图书馆常见成果清单字段建议:
| 字段 | 说明 |
| 教师标准名称 | 来自花名册映射结果,如 计算机学院-王强。 |
| 原始作者写法 | 文献数据库中的作者名称。 |
| 论文题名 | 文献标题。 |
| 发表年份 | 用于年度成果统计。 |
| 期刊 / 会议 | 用于成果来源分析。 |
| 作者类型 | 普通作者或通讯作者。 |
| 本校机构 | 用于确认是否为本校成果。 |
| 被引次数 | 用于影响力分析。 |
| DOI / 文献号 | 用于后续核验。 |
9. 结果复核建议
AI 作者映射可以显著提高定位效率,但涉及科研成果认领时,建议保留人工复核环节。
优先复核以下记录:
1. Group 中包含 | 的多候选记录。
2. 同名或同姓同首字母作者。
3. 文献作者缺少机构信息的记录。
4. 花名册中存在同名教师的学院。
5. 英文缩写过短的记录,例如 Wang, J.、Li, Y.。
6. 跨学院、附属医院、联合培养或兼职教师相关记录。
复核方法:
| 方法 | 说明 |
| 看机构地址 | 判断论文机构是否与教师所在学院或学校一致。 |
| 看研究方向 | 题名、关键词、摘要是否符合教师研究方向。 |
| 看通讯作者 | 通讯作者邮箱或地址是否指向本校。 |
| 看合作网络 | 共同作者是否为同一学院或团队成员。 |
| 查 DOI / 原文 | 对关键成果进行外部核验。 |
10. 保存和复用
AI 作者映射设置中的作者名单会被保存,便于下次继续使用。对于图书馆学科服务工作,建议建立多个花名册版本。
推荐命名方式:
全校教师花名册_2026
计算机学院教师花名册_2026
图书情报学院教师花名册_2026
附属医院通讯作者名单_2026
重点学科团队名单_2026
建议工作流:
1. 学校层面建立全校花名册。
2. 学院层面维护学院花名册。
3. 学科服务馆员可按服务对象维护专题花名册。
4. 每次成果统计前记录使用的花名册版本。
5. 对人工修正后的映射结果定期回填到花名册或规则库。
二、原理说明
1. AI 作者映射的基本逻辑
AI 作者映射本质上是一个“受控名单匹配”任务。系统把两类信息发送给 AI:
1. 用户提供的作者名单或通讯作者名单。
2. 当前选中的待识别作者记录。
AI 必须只从用户提供的名单中选择候选,不能编造名单外人员。匹配成功后,系统将名单中的原始写法写入 Group 字段。
例如,花名册中是:
计算机学院-王强
材料学院-王清
待识别作者是:
Wang, Q.
如果无法唯一判断是王强还是王清,AI 应返回多候选结果,并写为:
计算机学院-王强|材料学院-王清
2. 匹配依据
AI 作者映射会综合使用以下线索:
| 线索 | 说明 |
| 中文姓名 | 直接比较中文姓名是否一致。 |
| 拼音姓名 | 比较 王强 与 Wang Qiang、Qiang Wang 等写法。 |
| 缩写姓名 | 比较 Wang, Q.、Wang Q 等姓氏加首字母形式。 |
| 姓名前后顺序 | 同时考虑名在前、姓在前。 |
| 学院 / 部门 | 用作辅助证据,提高或降低置信度。 |
| 机构地址 | 作者记录中带机构信息时,可辅助判断是否为本校教师。 |
| 候选唯一性 | 如果同姓同首字母只有一个候选,可判为匹配;多个候选则判为模糊。 |
3. 写回规则
系统解析 AI 返回的 JSON 结果,并按以下方式写回数据表:
| AI 返回 | 系统写回 |
| group_value 不为空 | 写入 Group 字段。 |
| decision = Matched | GroupId 写入 AuthorMap[Matched][模型名]。 |
| decision = Ambiguous | GroupId 写入 AuthorMap[Ambiguous][模型名]。 |
| decision = Unmatched 且无 group_value | 不写入映射结果。 |
| 多个候选 | 使用 ` |
系统要求 AI 返回结果覆盖每一个待识别 ID。如果某些 ID 被模型遗漏,程序会尝试只对遗漏 ID 再次请求,以提高结果完整性。
4. 为什么适合高校图书馆学科服务
高校成果分析的难点不只是“作者重名”,还包括:
1. 中文姓名在国际数据库中常被写成拼音。
2. 许多数据库只保留姓氏和名字首字母。
3. 同一学校内可能存在多位同姓同首字母教师。
4. 作者机构字段常包含英文缩写、旧机构名、二级学院或附属医院名称。
5. 学科服务需要按本校组织体系统计,而不是只按数据库作者字符串统计。
AI 作者映射允许图书馆把“组织花名册”作为受控知识输入,让 AI 在名单范围内完成解释和匹配,从而把文献数据转化为面向学校管理和学科服务的教师成果数据。
5. 方法局限
使用该功能时,需要注意以下限制:
1. AI 映射结果不能替代最终人工认领。
2. 花名册越完整,映射结果越稳定。
3. 缺少机构、题名或学科信息时,缩写作者更容易产生多候选。
4. 同姓同首字母教师较多时,应优先使用学院花名册分批处理。
5. 不同模型对复杂姓名和机构线索的判断能力不同,建议固定模型版本。
6. 成果用于正式考核、绩效或评价时,应进行人工复核和留痕。
推荐原则:
- 用 AI 做初筛和批量归并。
- 用馆员复核处理模糊候选。
- 用教师本人或学院确认关键成果。
- 用固定花名册版本保证统计口径一致。